


I haven't seen anyone to write about this technique, so I decided to make a blog about it. I know that it is mostly general intuition, but not everyone really understand it. Also, I would be happy if you add something in comments or correct some errors. Also, before reading this blog I recommend to have some knowledge about segment tree and divide and conquer.
I would like to thank riazhskkh and FBI for reviewing this blog.
The main idea
When we have some divide and conquer algorithm, we can memorize each recursive call to be able to operate with it as data structure. For example, when we do merge sort, we can memorize how array looked after sorting on each call. Using this we can get merge sort tree. Also, if we memorize quick sort in such way, we will get wavelet tree. A lot of standart ways to use divide and conquer would lead to segment tree. But, it also can be used when we divide array on 3 parts or more, when we divide considering parity of indexes of array and so on. One of the main usage of it, that we can do almost all operation which we can do on segment tree, such as lazy propagation or tree descent, (in fact it depends on the task that we are solving) and in the most cases it optimize solutions alot. For example, if we havee recursion that recursevily divide array on even and odd elements,
and assume we memorize at each level (even and odd array each time), then we can do lazy propagation here. For example, we can add $$$x$$$ to all elements on the segment $$$[l,r]$$$, in the same way as in the segment tree. But this recursion can also solve queries to add $$$x$$$ to all elements with even (or odd) indexes on the segment $$$[l,r]$$$, or such indexes that are equal 3 by modulo 4, or in general any index that has last $$$k$$$ bits equal to some number. Also, as you may see, if we replace indexes by numbers, we would get a classic binary tree (a prefix tree).
The problem
We will solve this problem.
Solution
Firstly, we will solve the problem without queries. To make it easier, we can change vertex numbers on the tree using DFS.
For example, from this 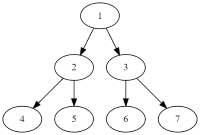 as in the statement to this
as in the statement to this 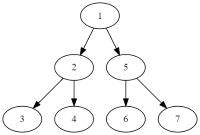 .
.
After changing graph indexing, we can use divide and conquer to check if the permutation is good. In fact, for any vertex, all vertexes in its subtree after sorting should be continuous. It is true because of the way we change vertex numbers. So, it can be easily verified by just taking maximum and minimum of all subtrees and checking if there is the same number of elements between maximum and minimum as there is in the tree (It works because all elements are distinct). Important thing is that we can do it on segments, since segment [1,n] represents the whole tree, while segment [2, $$$\lfloor\frac{n+1}{2}\rfloor$$$ ] represents its right subtree, and segment [ $$$\lfloor\frac{n+1}{2}+1\rfloor$$$ ,n] represents its left subtree. Also, it is important to check if the depth of the vertex is the same. You see, in any DFS order, the depth of all vertices doesn't change, but it is easy to come up with a test, where divide and conquer solution will give yes and depths will be wrong.
This solution works in $$$O(n\cdot log(n))$$$, but we can memorize all layers of a recursion call just like in the segment tree. In fact, all we need to memorize is a maximum and a minimum on a segment and if the segment is good (if check function from divide in conquer returns true or false). Then, we have queries which are to swap two elements. It is the same as changing the value of one element to the value of a second and vice versa for the second element, so all we need to be able to do is to change value of some element. Here, we can just memorize all states of recursion and make something like a segment tree, where segment [l,r) has children [l+1, $$$\lfloor\frac{l+r}{2}\rfloor$$$ ) and [ $$$\lfloor\frac{l+r}{2}\rfloor$$$ , r). So, it will work in $$$O(n\cdot log(n))$$$
Note
This technique can be used not only as binary tree like segment tree, trie or other, but also as another data structures. So, if you have tree with depth $$$g$$$, then you can answer the query in $$$O(g\cdot C)$$$ time where $$$C$$$ is number of operation needed to make decision to the child of the vertex. It means, that in path graph and star graph this will work in linear time per query.
So, you can solve the last problem not only when it is binary, but also when it is random generated. It is because the depth of the random generated tree is $$$O(log(n))$$$.
Also, I believe there could be a lot more tricks like this. Like taking random vertex as a root or doing same on any graph but on MST and so on. Unfortunetly, I have no samples for this yet.







Appreciate it bro.
love the insight! Keep up the good work.
Will this concept will also work for generic tree which is given in D2. DFS Checker (Hard Version) ?
Yes. It will. But running time could be linear per query since graph could have depth linear.
Good job! I'll remember this while solving future problems.