


25 февраля в 14:00 состоится очередная личная школьная интернет-олимпиада http://neerc.ifmo.ru/school/io/
На этот раз мы приготовили вам:
- Более сложный набор задач (ближе к уровню РОИ), надеемся, что он будет интересным.
- Условия на русском и на английском языке.
- Небольшой бонус в официальном web-client'е :)
К сожалению, во время этого раунда не будет работать PCMS2 Java Client.
P.S. На задачах этой олимпиады также проводится соревнование на школьных сборах в Давосе, куда приехали школьники из различных стран, в т.ч.России — Davos I-CUP.







А какой еще бонус?
Бонус, это попытки? :)
а что в них будет отображаться?
теперь возможно смотреть исходный код посылки как в Ejudge
эх, лучше бы уж токены добавили
лучше бы web-клиент работал...
а если бы задачи были, то вообще супер
Только что выложили. Извиняемся за задержку.
А если PCMS2 Web Client не будет работать, то как отправлять. Я по другому не знаю.
Извините. Заработал.
А не школьники вне конкурса могут решать?
Я один не могу зайти в клиент? Выводит: неверный логин или пароль, хотя пароль сохранен в браузере и никаких ошибок быть не может.
Да-да, практически одновременно с тобой написал об этом ниже :)
Снова все стало на свои места. Кстати, вопросы жюри можно посылать только через почту?
Да.
отвисло
Почему-то Web Client не пускает в систему, хотя ввожу правильный логин и пароль. У кого-нибудь еще такое есть?
А я не могу отправить задачу, выдает ошибку. Error You must select the problem you have solved. Что это может быть?
Надо выбрать задачу? Ваш Кеп.
Я не первый раз участвую. Все выбираю как надо. Позвонил другу у него без проблем все отправляет. Я отправлял 2 разные задачи на каждую из них пищет одно и то-же.
UPD: Проблема была в Explorer, под Opera все отправилось, а то у меня уже паника началась.
Как Б решалась?
еще 10 минут до конца.
Расскажите, как решать ВСЕ задачи.
На 1-ю задачу я писал бор по битам.
да да, так же делал
Тоже писал бор по битам, но почему-то у меня 40. У кого-нибудь еще есть такое? Вот код
возможно я ошибаюсь, но не из за того у вас 1<<31 и это вываливается за тип?
Да, это вываливается за тип. Возможно из-за этого. Спасибо.
я писал маленькое извращенство с set и lower_bound: для каждого a[i] сохранил в set < int, int > nums[r] его суффикс, начинающийся в r. Потом с помощью этой информации отвечал на запрос для b[i]: во-первых, инвертируем его, потом смотрим первый слева бит, который на том же месте где-то был в a[i], потом пытаемся после него жадно добавлять биты правее.
UPD да уж, видимо где-то набажил.
По-моему, в этот раз, организаторы перестарались со сложностью задач...
Написано, что эти задачи по уровню близки к РОИ.
Если это действительно так, то это хорошо. Можно заранее понять, что на всероссе ничего (ну или мало что) светит (я про себя).
На РОИ не будет участников, занявших здесь первые 6 мест :)
Ну, тоже верно :)
Нет, задачи хорошие. Большой плюс авторам.
задачи конечно хороши, соответсвуют уровню
А вот и результаты. Быстро :-)
Как решалась D на полный балл ?
У меня почти-перебор прошел на 100.
Сначала прочитаем все запросы (то есть, решение оффлайн).
Будем составлять пути от меньшего к большему. То есть, мы перебираем все простые пути в порядке возрастания длин пока не найдем все ответы. Самый маленький путь — очевидно самое маленькое из ребер. Дальше возможны варианты — добавить к текущему-самому-маленькому-пути какое-нибудь ребро которое примыкает к одному из концов пути, или взять за очередной путь еще какое-нибудь ребро. Сам этот перебор путей легко реализовать, например, кучей. Теперь, когда у нас есть какой-то путь, то смотрим в какие моменты времени обе вершины одинакового цвета (оба города поддерживают одинаковую партию) и на основании этого будем изменять ответ.
Почему-то ответы находятся довольно быстро (надо проверить не очень много путей), я не знаю почему.
Код
Интересно, Гена тоже такое писал? Я писал ровное O((N+M+K)*log(N)).
Как Гена решал я не знаю :) Для того, чтобы сломать по TL мое решение, возможно, есть тесты. Можешь рассказать как за O((N+M+K)*log(N))?
Да. Заметим что путь имеет длину не более чем 2, что очевидно от обратного. Теперь для каждой вершины будем знать 2 дерева отрезков(по минимуму расстояний) по вершинах соседних с данной, одно для тех кто сейчас 1го типа 2е для 2го, понятно что в сумме элементов не много. Дальше есть 4 способа создать маршрут, либо через одну вершину, либо вообще ребро. Понятно что с помощью деревьев искать два минимальных элемента не сложно. Теперь допустим мы встретили обновление. Обновим данную вершину для всех соседних и обновим ответ для самой вершины. Теперь осталось только каждый раз быстро знать минимум для всех вершин, с этой подзадаче тоже хорошо справляется дерево отрезков, так-как ответ может ухудшиться.
На С++ с векторами не сложно написать, но для меня была проблемой запихнуть деревья отрезков в линейную память.
Не понял предложение "Обновим данную вершину для всех соседних и обновим ответ для самой вершины", будем изменять значение вершины у каждого соседа, их же много может быть?
Их будет в сумме для всех запросов не много, если быть точным то это будет кол-во ребер в графе, а вершину мы только один раз можем изменять по условию. Обновим, это означает что запишем ее в нужное дерево и удалим их того где она уже не должна быть.
Ах, не заметил, что только раз менять вершину можно..спасибо.
Если есть рёбра A-B и B-C, то из путей A-B, B-C и A-B-C как минимум один подойдёт, поэтому достаточно рассматривать только самый короткий путь длины 2. Проще всего это сделать, добавив ещё одно ребро A-C для этого пути (с весом, равным сумме весов A-B и B-C) и теперь рассматривая только пути длины 1. В остальном вроде так же.
А новых ребер не много будет? Ну например если граф — дерево и все вершины находится на расстоянии 1 от корня. Тогда новых ребер по идеи будет квадрат, или я не так понял?
Нет, в граф добавляется ровно одно ребро, соответствующее кратчайшему пути длины 2.
А, понял.
лично меня больше всего порадовала Б, и даже не сама задача, а то что я не ошибся в рассуждениях, за что очень боялся
Расскажите пожалуйста как ее решать больше чем на 30 баллов.
не то прочитал
Там будет первый или второй тур?
А какая разница? Заранее прорешать? :)
Предполагалось ли, что задачи на сегодняшнем контесте отсортированы по возрастанию сложности (A — самая простая, D — самая сложная)?
для каждого всегда по разному) но то что Д сложнее всех это да.
как решать С на 100?
Будем делать стандартную проверку на правильность и как только нашли символ который все портит, проверим его. То-есть проверим все 5 вариантов. Потом перевернем строку и сделаем тоже самое.
а зачем переворачивать?
и код можете показать?
Потому-что мой алгоритм ставит только закрывающие скобки.
тогда не совсем понятно, почему 5 вариантов
всего у нас есть 6 различных скобок, а всех, кроме одной (которая уже стоит), 5
Если алгоритм такой, можно вроде только 2-3 варианта рассмотреть.
я о том же
я для гарантии рассматривал.
Расскажите кто-нибудь как тестировать задачи с чекером, где ответ не однозначен. В данном случае задача С.
Надо проверить является ли вывод правильной скобочной последовательностью, и проверить что отличается от ввода только на 1 символ. На каждую задачу нужен свой чекер.
UPD: Сорри, не так понял вас =)
Дак там, вроде, есть готовый чекер в архиве с тестами. Я просто им пользоваться не умею вот и спрашиваю.
привет, Вань! можно попробовать оттестить с помощью тестилки тимуса, но это вроде проблемно, легче самому чекер встроить в программа, самому написать
Привет. Я сам тестером тимуса пользуюсь когда ответ однозначен. Тут да, несложно написать свой чекер. Но проще один научиться пользоваться чекером из архива с тестами, чем каждый раз писать свой.
ну там надо указать имя чекера, не?
Самый простой способ — положить в папку задачи свое решение, переименнованное как %имя задачи%_%любой суффикс%.%расширение%, например, competition_sp.java, потом в папке tests запустить команду docheck %указанный суффикс% (в данном случае docheck sp). В решениях жюри суффикс — инициалы авторов.
Как правильно решалась задача В?
я решил так: пусть для каждой строки xi — это мальчики стоящие на нечетных позициях, и yi — на нечетных
отметим, что четные строки (с четной длиной) очередность не меняют, так же, если в наборе строк есть хотя бы одна нечетная строка (с нечетной длиной), то четные строки мы можем расставить так, чтобы по максимуму задействовать мальчиков в этой строке, то если для четной строки выполняется xi ≥ yi поставить ее перед первой нечетной строкой, иначе, после первой нечетной строки, т.о. можем сразу выкинуть из рассмотрения четные строки.
остались нечетные строки, расставив их каким либо образом, мы получим, что в первой поставленной строке будут учитываться мальчики, стоящие на нечетных позициях, во-второй поставленной, мальчики на четной позиции, в третьей снова на нечетной... и т.д.
теперь надо как-то оптимально расставить строки на нечетный позиции! всего нечетных позиций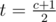 . пусть xi > yi, (i — какая либо нечетная строка) то очевидно, что этого мальчика выгодно поставить на нечетную позицию. пусть таких строк v, тогда возможны 3 случая:
. пусть xi > yi, (i — какая либо нечетная строка) то очевидно, что этого мальчика выгодно поставить на нечетную позицию. пусть таких строк v, тогда возможны 3 случая:
v = t ну тут все очевидно, просто берем эти строки
v < t тогда возьмем v этих строк, остальные, очевидно, выгодно взять такие, что yi - xi минимально, чтобы минимизировать потери на четных позициях
v > t тогда возьмем эти первые t строк, у которых xi - yi максимально, это оптимально так как, если мы попытаемся поменять какие-то строки, стоящие на нечетной и четной позиции, мы не улучшим ответ
на самом деле, все эти 3 случая сводятся к обычной сортировке по xi - yi
вот код
такое вот длинное, извратское, но надеюсь, понятное решение