


Задача A
Рассмотрим сначала случай, когда все числа отличны от нуля. Тогда можно взять a*c*e граммов песка, получить из них b*c*e граммов свинца, из них - b*d*e граммов золота, из них - b*d*f граммов песка. Если b*d*f > a*c*e, то можно неограниченно увеличивать количество песка, а, соответственно, и золота. В противном случае, когда b*d*f <= a*c*e, сколь угодно большое количество золота получить невозможно. То же самое верно, если у дроби (a*c*e)/(b*d*f) только числитель или только знаменатель равен нулю. В противном случае возникает неопределенность 0/0 и нужно делать отдельную проверку случаев.
Поясню, почему я сделала эту задачу именно задачей A.
1. Для решения задачи требуются совсем незначительные знания по программированию (только if), поэтому она была доступна всем участникам.
2. Хитрые случаи действительно были, но я понадеялась, что "сильные участники ... помогут новичкам отловить все баги своими взломами". Так оно и вышло.
Хотя, возможно, я была не права: эта задача слишком сложная для А.
Большое количество взломов по этой задаче - вполне предвиденное обстоятельство. Специально оставила большой класс тестов, не вошедший в претесты, чтобы было интереснее ломать. Ради справедливости стоит отметить, что Артем Рахов был против этого. В связи с этой задачей остро всплыла проблема, о которой написал Gassa: претесты отражают весьма неполный набор случаев и заранее непонятно, какой это набор и как интерпретировать событие "решение прошло претесты". Мне кажется, стоит обсудить этот вопрос и четко определить принципы разработки претестов.
Задача B
Задача решается жадно. Заменим одну цифру в первой дате таким образом, чтобы год получился наименьшим возможным. На каждом следующем шаге будем перебирать все замены одной цифры в очередной дате и выбирать такую, которая делает дату не меньше предыдущей и при этом как можно меньшей. Если последний год не превзошел 2011 - решение найдено. Иначе решения не существует.
Как это доказать? Рассмотрим некоторое правильное решение. Ясно, что если первая дата в нем не совпадает с наименьшим числом, которое можно получить из первого заданного, то можно заменить ее на это число. Вторую дату также можно заменить на наименьшее возможное число, не превосходящее первого и т.д. В результате мы получим из любого решения тот жадный вариант, который научились строить. А если такого жадного варианта не существует - то и решения не существует.
Также можно было решать задачу динамикой.
Задача C
Будем отдельно для каждого звена ломаной определять, может ли Гарри поймать снитч на нем. Заметим, что так как vp ≥ vs, то если Гарри может поймать снитч в некоторый момент времени, то он сможет поймать его и в более поздний момент времени. Он сможет просто лететь за снитчем по его траектории. Поэтому используем бинарный поиск на каждом отрезке.
Отдельно остановлюсь на проблемах с EPS, возникших у участников. Проблемы могли возникнуть из-за того, что
1) некоторый EPS стоял в условии: while (leftTime + EPS < rightTime) <делать бинпоиск>. В задаче нужно было с определенной точностью выводить не только время, но и координаты точки. Если время отличается от правильного не больше, чем на EPS, то координаты точки могут отличаться значительно сильнее. В таких случаях нужно сравнивать не аргумент функции, а саму функцию с EPS. Или, как обычно делаю я и что однажды не понравилось преподавателю по численным методам, делать некоторое фиксированное количество итераций бинпоиска (например, 60).
2) EPS в сравнении времен внутри бинпоиска вроде этого:
if (currentTime + addTime > distance / potterSpeed - EPS)
rightTime = currentTime;
else
leftTime = currentTime;
Здесь его вообще лучше убрать. Или поставить EPS значительно меньше по сравнению с точностью, с которой надо выводить точку.
(Приведенные фрагменты кода - из решения Егора.)
Таким образом, никакого криминала с жесткими ограничениями не было. Возможно, в подобных задачах крайние тесты на точность должны содержаться в претестах? Но это снова о принципах составления претестов.
UPD. У задачи существует еще и аналитическое решение. Рассмотрим i-й отрезок. Пусть (xi, yi, zi) и (xi + 1, yi + 1, zi + 1) - его концы, ti - время, за которое снитч достигает его начала. Тогда в момент времени t снитч будет в точке (x, y, z), x = xi + (xi + 1 - xi)(t - ti) / Ti, y = yi + (yi + 1 - yi)(t - ti) / Ti, z = zi + (zi + 1 - zi)(t - ti) / Ti, Ti - время, необходимое снитчу для преодоления всего отрезка. Чтобы поймать снитч в точке (x, y, z), Гарри нужно преодолеть расстояние, квадрат которого (x - Px)2 + (y - Py)2 + (z - Pz)2 за время t. Это возможно, если (x - Px)2 + (y - Py)2 + (z - Pz)2 ≤ (tvp)2. Чтобы найти наименьший подходящий момент t, нужно решить соответствующее квадратное уравнение.
Задача D
Обозначим через Si множество всевозможных распределений первых i по учеников по факультетам, представляющее собой множество четверок вида (a1, a2, a3, a4), где a1 - количество учеников, отправленных в Гриффиндор, a2 - в Когтевран и т.д. Интуитивно понятно, что эти множества будут небольшими. Поэтому можно, тривиальным образом переходя от Si - 1 к Si, получить Sn, и по нему определить ответ.
Как же все-таки строго обосновать такой алгоритм? Пусть имеется некоторое множество S = {(ai1, ai2, ai3, ai4)}i = 1, 2, ..., k. Представим его элементы в виде aij = bj + xij, xij ≥ 0, причем bj выбраны максимально возможными, т.е. для любого j найдется i, такое, что xij = 0. Назовем кортеж (b1, b2, b3, b4) базовой частью для S, а множество {(xi1, xi2, xi3, xi4)}i = 1, 2, ..., k -- вариантной частью.
В самом начале для S0 и базовая, и вариантная части равны нулю. Проследим, как изменяются базовая и вариантная часть при рассмотрении очередного ученика. Если для этого ученика факультет фиксирован, но изменится только базовая часть. Она увеличится на 1 в позиции, соответствующей факультету. Из этого, в частности, следует, что можно получить множество с любой базовой частью (поскольку заданная во входном файле строка может содержать любую комбинацию символов G, H, R, S). Если же очередной символ в строке '?', то это может повлиять на изменение и базовой, и вариантной частей.
Например, для строки '????' имеем:
S0 = {(0 + 0, 0 + 0, 0 + 0, 0 + 0)},
S1 = {(0 + 1, 0 + 0, 0 + 0, 0 + 0), (0 + 0, 0 + 1, 0 + 0, 0 + 0), (0 + 0, 0 + 0, 0 + 1, 0 + 0), (0 + 0, 0 + 0, 0 + 0, 0 + 1)},
S2 = {(0 + 1, 0 + 1, 0 + 0, 0 + 0), (0 + 1, 0 + 0, 0 + 1, 0 + 0), (0 + 1, 0 + 0, 0 + 0, 0 + 1), (0 + 0, 0 + 1, 0 + 1, 0 + 0), (0 + 0, 0 + 1, 0 + 0, 0 + 1), (0 + 1, 0 + 0, 0 + 1, 0 + 1)},
S3 = {(0 + 1, 0 + 1, 0 + 1, 0 + 0), (0 + 1, 0 + 1, 0 + 0, 0 + 1), (0 + 1, 0 + 0, 0 + 1, 0 + 1), (0 + 0, 0 + 1, 0 + 1, 0 + 1)\},
S4 = {(1 + 0, 1 + 0, 1 + 0, 1 + 0)}.
Исследуем вопрос о том, какой вид может иметь вариантная часть. Ее можно рассматривать независимо от базовой, учитывая при этом, что базовая может быть любой. Рассмотрим орграф, вершинами которого являются вариантные части, а ребра определяются тем, существует ли хотя бы одна базовая часть, при которой от одной вариантной части можно перейти к другой. Нас интересуют лишь те вершины, которые достижимы из {(0, 0, 0, 0)}.
Утверждение. Для всех достижимых из нуля вершин
(1) xij ≤ 2,
(2) k ≤ 13.
Докажем, что все не обладающие свойствами (1) и (2) вершины недостижимы из нуля. Пусть имеется вариантная часть, обладающая свойством (1). Чтобы перебрать переходы из нее, нужно рассмотреть все возможные базовые части. Заметим, что достаточно рассмотреть базовые части, состоящие из чисел 0, 1, 2, 3 и содержащие хотя бы один 0. Действительно, базовая часть влияет на то, какие элементы будут минимальными, и к ним буде прибавление единицы. Базовую часть всегда можно нормировать, чтобы она содержала хотя бы один 0. Если базовая часть содержит числа больше 3, то соответствующие позиции никогда не будут минимальными (т.к. 4+0 > 0+2) и их можно эквивалентным образом заменить на 3 (3+0 > 0+2).
К сожалению, мои попытки рассмотрения случаев вручную ни к чему не привели, поэтому я написала программу, которая обходит описанный граф. Начиная из вершины 0, она строит переходы, перебирая лишь "маленькие" базовые части, описанные в предыдущем абзаце. В итоге эта программа перебирает все достижимые вариантные части (их оказывается чуть больше 1000) и проверяет, что они удовлетворяют условиям (1) и (2). Кроме того, программа позволяет построить тест с k = 13.
Задача вообщем-то предполагалась как задача на интуицию. Некоторые участники сдали другое решение, которое обсуждается здесь. В нем перебираются все перестановки и происходит жадное распределение учеников по факультетам в соответствии с каждой перестановкой. Для меня такое решение оказалось полной неожиданностью. К сожалению, оно неправильное. Добавлен тест 66 против него. Перетестирования решений, сданных во время раунда, разумеется, не будет. Если бы такое решение предвиделось, скорее всего я не стала бы давать такую задачу. Ведь с точки зрения интуиции оно ничем не лучше и не хуже моего. Надеюсь, меня не будут судить строго: все-таки красивая задача, интересно было посмотреть, как ее порешают.
Задача E
Рассмотрим граф, вершинами которого являются этажи, а ребрами - лестницы. Ясно, что, не двигая лестниц, Гарри сможет посетить всю компоненту связности, в которой находится его текущее местоположение.
Каждое ребро может быть использовано для достижения новой вершины не более, чем два раза. Если компонента связности содержит n вершин и m ребер, то при обходе этой компоненты мы используем только n - 1 ребро для достижения новой вершины. Остальные m - n + 1 ребро не будут использованы для достижения новой вершины при их изначальном расположении. Поэтому они будут использованы для достижения новой вершины не более чем по одному разу.
Получаем, что используя ребра только одной компоненты связности, можно достичь не более чем n + m - 1 новых вершин. Всего получается не более чем 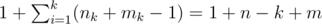 достижимых вершин. Если m < k - 1, то получается, что все вершины посетить невозможно.
достижимых вершин. Если m < k - 1, то получается, что все вершины посетить невозможно.
достижимых вершин. Если m < k - 1, то получается, что все вершины посетить невозможно.Покажем, что в противном случае (m >= k - 1) и если степень вершины 1 отлична от нуля, можно обойти все вершины. Иначе говоря, можно будет придумать такой порядок обхода, чтобы можно было переместить каждое из ребер. Будем обходить текущую компоненту обходом в глубину. Если нам встретилось ребро, ведущее в уже посещенную вершину - перенаправим его в новую компоненту и обойдем ее рекурсивно. После того, как мы прошли по ребру в новую вершину и вернулись обратно, тоже перенаправим его в новую компоненту. В итоге каждое ребро получится использовать повторно, если мы дойдем до всех компонент. Если компонента содержит хотя бы одно ребро, из нее можно перейти к следующей. Если в первую очередь перебирать только компоненты с ребрами, мы пройдем по ним по всем и по неравенству (m >= k -1) нам хватит ребер для посещения изолированных вершин.
Если степень вершины 1 равна нулю, мы не можем начать обход, пока не перенаправим в нее какое-нибудь ребро. После этого мы пройдем по этому ребру и выкинем его вместе с вершиной 1 из графа, так как больше использовать это ребро не сможем. Если выбранное ребро - мост, то мы получим в итоге k компонент связности и m - 1 ребро. Если не мост - k - 1 компоненту связности и m - 1 ребро. В первом случае условие m >= k - 1 превращается в условие m >= k. Во втором - m >= k - 1. Поэтому если не все ребра мосты, нужно брать не мост. Если все - мосты, нужно отсоединять ребро от вершины степени >= 2, чтобы не прийти в начальную ситуацию с нулевой степенью первой вершины. Если такой вершины не найдется, то легко показать, что нет решения.







Кстати, в этой задаче я почему-то не догнал, что Гарри сможет поймать снитч и в более поздние моменты времени, если поймал в какой-то, - ещё и гадал, а зачем вообще ограничение, что vp>=vs? Поэтому написал сначала троичный поиск минимума на каждом отрезке, а потом двоичный от начала отрезка до этого минимума. Ещё и боялся, что функция может оказаться невыпуклой и потому не пройдёт! %)
P.S. Кстати, для java тесты с большим количеством входных данных даже чем-то лучше - на какой-нибудь тысячной итерации оно наконец догадается, что тело цикла можно скомпилировать и дальше будет работать шустро.
В задачах не промышленных, а научных строгая постановка нередко получается только после того, как решение уже готово, поэтому имеет смысл писать настолько оптимально, насколько можешь.
Или простое - это численный метод с кучей итераций?
Для компа проще посчитать по формуле. Да и я думаю что это простое, красивое, лаконичное и самое главное быстрое решение.
А в реальных задачах редко есть чёткое ограничение по времени как в спортивном соревновании (типа 2 секудны). Обычно подразумевается - чем быстрее, тем лучше (но не в ущерб понятности и лаконичности).
Численный метод, конечно, проще в том смысле, что думать меньше. Кому-то реализовать проще и быстрее. Но обидно, что эталонное решение тоже такое.
как миркак ACM холивар (а ответ на все холивары - в разных случаях по-разному, вопрос может быть только в том, в каких именно как), может, не стоит продолжать?..По задаче C
if (currentTime + addTime > distance / potterSpeed - EPS)
Если убрать здесь EPS, то решение имеет большой шанс упасть на таком тесте
1
0 0 0
1 1 1
1 1
0 0 0
PS: моё полное решение на таком тесте падает.
Если только числитель, то как раз возможно.
(ага, еще 100 баллов, следующий :))
(Но я только сейчас это поняла, когда перечитала в третий-четвертый раз. А на первый взгляд выглядит очевидной ошибкой, особенно по инерции, после чтения двадцати-тридцати неверных решений.)
while (abs(x1-x2)+abs(y1-y2)+abs(z1-z2) > 1e-10) {
...
if (abs(R0 - R) < 1e-10) break; // криво, но я перестраховался
...
}
P.S. Уже чувствую себя на гауптвахте за злостное нарушение субординации :-X
В спортивном программировании иногда это лучший вариант.
If set 2000,I got AC....
You can have a try with {"?HRS"*2500} :)
what might the time complexity of D be?
Here are the 2 interpretations of problem A's solution as I understood them:
64128016
64128379