


Thank you all for participating in the round!
We apologize for the wrong checker in problem E at the beginning of the contest, as well as the weak tests in problem B. To be honest, all the hacked submissions have similar logic and codes in B, which made me suspicious. Anyway, we are sorry for the inconvenience! >_<
| A | B | C | D | E | F | G | H | I | |
|---|---|---|---|---|---|---|---|---|---|
| Error_Yuan | 800 | 1200 | 1600 | 2100 | 2300 | 2600 | 3000 | 3400 | 3500 |
| sszcdjr | 800 | 1100 | 1600 | 2000 | 2300 | 2600 | 2900 | 3300 | 3500 |
| wyrqwq | 800 | 1000 | 1400 | 2200 | 2300 | 2600 | 3000 | 3500 | 3500 |
| Otomachi_Una | 800 | 1000 | 1600 | 2200 | 2400 | 2600 | 3200 | 3500 | 3500 |
| dXqwq | 900 | 1100 | 1700 | 2200 | 2400 | 2600 | 3200 | 3500 | 3500 |
| Kubic | 800 | 1000 | 1600 | 2400 | 2200 | 2800 | 3000 | 3500 | 3300 |
| wsc2008qwq | 800 | 1100 | 1600 | 1900 | 2200 | 2700 | 3100 | ||
| chromate00 | 800 | 1000 | 1600 | 1900 | |||||
| rui_er | 800 | 1000 | 1500 | 1800 | 2200 | 2500 | 3000 | ||
| abc864197532 | 800 | 1100 | 1600 | 2200 | 2300 | 2500 | 2900 |
| A | B | C | D | E | F | G | H | I | |
|---|---|---|---|---|---|---|---|---|---|
| Average | 810 | 1060 | 1580 | 2090 | 2289 | 2611 | 3033 | 3450 | 3467 |
| Actual | 800 | 1100 | 1700 | 1900 | 2100 | 2500 | 3000 | 3500 | 3400 (Thank you, rainboy) |
Author: Otomachi_Una
First Blood: Benq at 00:00:51
Greedy from small to large.
We can delete the numbers from small to large. Thus, previously removed numbers will not affect future choices (if $$$x<y$$$, then $$$x$$$ cannot be a multiple of $$$y$$$). So an integer $$$x$$$ ($$$l\le x\le r$$$) can be removed if and only if $$$k\cdot x\le r$$$, that is, $$$x\le \left\lfloor\frac{r}{k}\right\rfloor$$$. The answer is $$$\max\left(\left\lfloor\frac{r}{k}\right\rfloor-l+1,0\right)$$$.
Time complexity: $$$\mathcal{O}(1)$$$ per test case.
#include <bits/stdc++.h>
#define all(s) s.begin(), s.end()
using namespace std;
using ll = long long;
using ull = unsigned long long;
const int _N = 1e5 + 5;
int T;
void solve() {
int l, r, k; cin >> l >> r >> k;
cout << max(r / k - l + 1, 0) << endl;
return;
}
int main() {
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
cin >> T;
while (T--) {
solve();
}
}
for _ in range(int(input())):
l, r, k = map(int, input().split())
print(max(r // k - l + 1, 0))
Author: wyrqwq
First Blood: Benq at 00:02:30
($$$\texttt{01}$$$ or $$$\texttt{10}$$$ exists) $$$\Longleftrightarrow$$$ (both $$$\texttt{0}$$$ and $$$\texttt{1}$$$ exist).
Each time we do an operation, if $$$s$$$ consists only of $$$\texttt{0}$$$ or $$$\texttt{1}$$$, we surely cannot find any valid indices. Otherwise, we can always perform the operation successfully. In the $$$i$$$-th operation, if $$$t_i=\texttt{0}$$$, we actually decrease the number of $$$\texttt{1}$$$-s by $$$1$$$, and vice versa. Thus, we only need to maintain the number of $$$\texttt{0}$$$-s and $$$\texttt{1}$$$-s in $$$s$$$. If any of them falls to $$$0$$$ before the last operation, the answer is NO, otherwise, the answer is YES.
Time complexity: $$$\mathcal{O}(n)$$$ per test case.
#include <bits/stdc++.h>
#define all(s) s.begin(), s.end()
using namespace std;
using ll = long long;
const int _N = 1e5 + 5;
void solve() {
int n; cin >> n;
string s, t; cin >> s >> t;
int cnt0 = count(all(s), '0'), cnt1 = n - cnt0;
for (int i = 0; i < n - 1; i++) {
if (cnt0 == 0 || cnt1 == 0) {
cout << "NO" << '\n';
return;
}
if (t[i] == '1') cnt0--;
else cnt1--;
}
cout << "YES" << '\n';
}
int main() {
int T; cin >> T;
while (T--) {
solve();
}
}
for _ in range(int(input())):
n = int(input())
s = input()
one = s.count("1")
zero = s.count("0")
ans = "YES"
for ti in input():
if one == 0 or zero == 0:
ans = "NO"
break
one -= 1
zero -= 1
if ti == "1":
one += 1
else:
zero += 1
print(ans)
Author: Error_Yuan
First Blood: ksun48 at 00:05:34
Binary search.
Do something backward.
First, do binary search on the answer. Suppose we're checking whether the answer can be $$$\ge k$$$ now.
Let $$$f_i$$$ be the current rating after participating in the $$$1$$$-st to the $$$i$$$-th contest (without skipping).
Let $$$g_i$$$ be the minimum rating before the $$$i$$$-th contest to make sure that the final rating is $$$\ge k$$$ (without skipping).
$$$f_i$$$-s can be calculated easily by simulating the process in the statement. For $$$g_i$$$-s, it can be shown that
where $$$g_{n+1}=k$$$.
Then, we should check if there exists an interval $$$[l,r]$$$ ($$$1\le l\le r\le n$$$), such that $$$f_{l-1}\ge g_{r+1}$$$. If so, we can choose to skip $$$[l,r]$$$ and get a rating of $$$\ge k$$$. Otherwise, it is impossible to make the rating $$$\ge k$$$.
We can enumerate on $$$r$$$ and use a prefix max to check whether valid $$$l$$$ exists.
Time complexity: $$$\mathcal{O}(n\log n)$$$ per test case.
Consider DP.
There are only three possible states for each contest: before, in, or after the skipped interval.
Consider $$$dp_{i,0/1/2}=$$$ the maximum rating after the $$$i$$$-th contest, where the $$$i$$$-th contest is before/in/after the skipped interval.
Let $$$f(a,x)=$$$ the result rating when current rating is $$$a$$$ and the performance rating is $$$x$$$, then
And the final answer is $$$\max(dp_{n,1}, dp_{n,2})$$$.
Time complexity: $$$\mathcal{O}(n)$$$ per test case.
#include <bits/stdc++.h>
#define all(s) s.begin(), s.end()
using namespace std;
using ll = long long;
using ull = unsigned long long;
const int _N = 1e5 + 5;
int T;
void solve() {
int n; cin >> n;
vector<int> a(n + 1);
for (int i = 1; i <= n; i++) cin >> a[i];
vector<int> pre(n + 1);
int curf = 0;
for (int i = 1; i <= n; i++) {
if (curf < a[i]) curf++;
else if (curf > a[i]) curf--;
pre[i] = max(pre[i - 1], curf);
}
auto check = [&](int k) {
int curg = k;
for (int i = n; i >= 1; i--) {
if (pre[i - 1] >= curg) return true;
if (a[i] < curg) curg++;
else curg--;
}
return false;
};
int L = 0, R = n + 1;
while (L < R) {
int mid = (L + R + 1) >> 1;
if (check(mid)) L = mid;
else R = mid - 1;
}
cout << L << '\n';
return;
}
int main() {
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
cin >> T;
while (T--) {
solve();
}
}
for _ in range(int(input())):
n = int(input())
def f(a, x):
return a + (a < x) - (a > x)
dp = [0, -n, -n]
for x in map(int, input().split()):
dp[2] = max(f(dp[1], x), f(dp[2], x))
dp[1] = max(dp[1], dp[0])
dp[0] = f(dp[0], x)
print(max(dp[1], dp[2]))
Author: Error_Yuan
First Blood: ksun48 at 00:13:24
There are many different approaches to this problem. Only the easiest one (at least I think so) is shared here.
Try to make the graph into a forest first.
($$$deg_i\le 1$$$ for every $$$i$$$) $$$\Longrightarrow$$$ (The graph is a forest).
Let $$$d_i$$$ be the degree of vertex $$$i$$$.
First, we keep doing the following until it is impossible:
- Choose a vertex $$$u$$$ with $$$d_u\ge 2$$$, then find any two vertices $$$v,w$$$ adjacent to $$$u$$$. Perform the operation on $$$(u,v,w)$$$.
Since each operation decreases the number of edges by at least $$$1$$$, at most $$$m$$$ operations will be performed. After these operations, $$$d_i\le 1$$$ holds for every $$$i$$$. Thus, the resulting graph consists only of components with size $$$\le 2$$$.
If there are no edges, the graph is already cool, and we don't need to do any more operations.
Otherwise, let's pick an arbitrary edge $$$(u,v)$$$ as the base of the final tree, and then merge everything else to it.
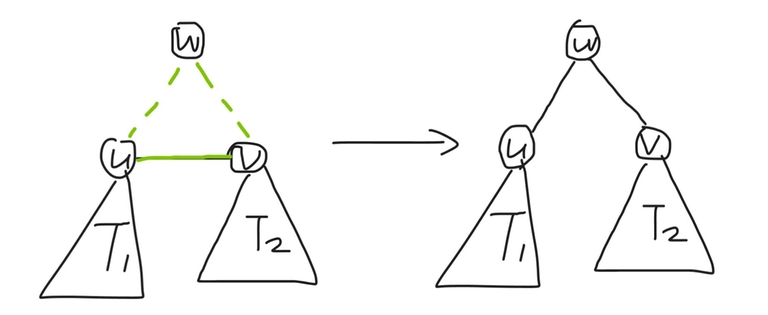
For a component with size $$$=1$$$ (i.e. it is a single vertex $$$w$$$), perform the operation on $$$(u, v, w)$$$, and set $$$(u, v) \gets (u, w)$$$.
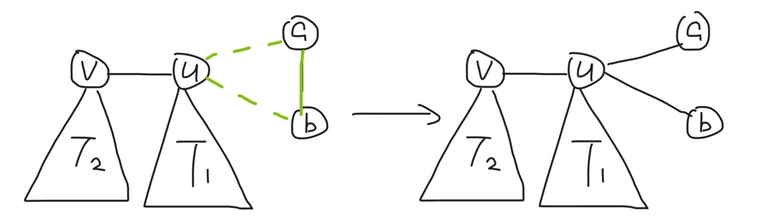
For a component with size $$$=2$$$ (i.e. it is an edge connecting $$$a$$$ and $$$b$$$), perform the operation on $$$(u, a, b)$$$.
It is clear that the graph is transformed into a tree now.
The total number of operations won't exceed $$$n+m\le 2\cdot \max(n,m)$$$.
In the author's solution, we used some data structures to maintain the edges, thus, the time complexity is $$$\mathcal{O}(n+m\log m)$$$ per test case.
#include <bits/stdc++.h>
using namespace std;
#ifdef DEBUG
#include "debug.hpp"
#else
#define debug(...) (void)0
#endif
using i64 = int64_t;
constexpr bool test = false;
int main() {
cin.tie(nullptr)->sync_with_stdio(false);
int t;
cin >> t;
for (int ti = 0; ti < t; ti += 1) {
int n, m;
cin >> n >> m;
vector<set<int>> adj(n + 1);
for (int i = 0, u, v; i < m; i += 1) {
cin >> u >> v;
adj[u].insert(v);
adj[v].insert(u);
}
vector<tuple<int, int, int>> ans;
for (int i = 1; i <= n; i += 1) {
while (adj[i].size() >= 2) {
int u = *adj[i].begin();
adj[i].erase(adj[i].begin());
int v = *adj[i].begin();
adj[i].erase(adj[i].begin());
adj[u].erase(i);
adj[v].erase(i);
ans.emplace_back(i, u, v);
if (adj[u].contains(v)) {
adj[u].erase(v);
adj[v].erase(u);
} else {
adj[u].insert(v);
adj[v].insert(u);
}
}
}
vector<int> s;
vector<pair<int, int>> p;
for (int i = 1; i <= n; i += 1) {
if (adj[i].size() == 0) {
s.push_back(i);
} else if (*adj[i].begin() > i) {
p.emplace_back(i, *adj[i].begin());
}
}
if (not p.empty()) {
auto [x, y] = p.back();
p.pop_back();
for (int u : s) {
ans.emplace_back(x, y, u);
tie(x, y) = pair(x, u);
}
for (auto [u, v] : p) {
ans.emplace_back(y, u, v);
}
}
println("{}", ans.size());
for (auto [x, y, z] : ans) println("{} {} {}", x, y, z);
}
}
Author: Error_Yuan, wyrqwq
First Blood: ksun48 at 00:23:50
$$$2$$$ is powerful.
Consider primes.
How did you prove that $$$2$$$ can generate every integer except odd primes? Can you generalize it?
In this problem, we do not take the integer $$$1$$$ into consideration.
Claim 1. $$$2$$$ can generate every integer except odd primes.
Proof. For a certain non-prime $$$x$$$, let $$$\operatorname{mind}(x)$$$ be the minimum divisor of $$$x$$$. Then $$$x-\operatorname{mind}(x)$$$ must be an even number, which is $$$\ge 2$$$. So $$$x-\operatorname{mind}(x)$$$ can be generated by $$$2$$$, and $$$x$$$ can be generated by $$$x-\operatorname{mind}(x)$$$. Thus, $$$2$$$ is a generator of $$$x$$$.
Claim 2. Primes can only be generated by themselves.
According to the above two claims, we can first check if there exist primes in the array $$$a$$$. If not, then $$$2$$$ is a common generator. Otherwise, let the prime be $$$p$$$, the only possible generator should be $$$p$$$ itself. So we only need to check whether $$$p$$$ is a generator of the rest integers.
For an even integer $$$x$$$, it is easy to see that, $$$p$$$ is a generator of $$$x$$$ if and only if $$$x\ge 2\cdot p$$$.
Claim 3. For a prime $$$p$$$ and an odd integer $$$x$$$, $$$p$$$ is a generator of $$$x$$$ if and only if $$$x - \operatorname{mind}(x)\ge 2\cdot p$$$.
Proof. First, $$$x-\operatorname{mind}(x)$$$ is the largest integer other than $$$x$$$ itself that can generate $$$x$$$. Moreover, only even numbers $$$\ge 2\cdot p$$$ can be generated by $$$p$$$ ($$$x-\operatorname{mind}(x)$$$ is even). That ends the proof.
Thus, we have found a good way to check if a certain number can be generated from $$$p$$$. We can use the linear sieve to pre-calculate all the $$$\operatorname{mind}(i)$$$-s.
Time complexity: $$$\mathcal{O}(\sum n+V)$$$, where $$$V=\max a_i$$$.
Some other solutions with worse time complexity can also pass, such as $$$\mathcal{O}(V\log V)$$$ and $$$\mathcal{O}(t\sqrt{V})$$$.
#include <bits/stdc++.h>
#define all(s) s.begin(), s.end()
using namespace std;
using ll = long long;
using ull = unsigned long long;
const int _N = 4e5 + 5;
int vis[_N], pr[_N], cnt = 0;
void init(int n) {
vis[1] = 1;
for (int i = 2; i <= n; i++) {
if (!vis[i]) {
pr[++cnt] = i;
}
for (int j = 1; j <= cnt && i * pr[j] <= n; j++) {
vis[i * pr[j]] = pr[j];
if (i % pr[j] == 0) continue;
}
}
}
int T;
void solve() {
int n; cin >> n;
vector<int> a(n + 1);
for (int i = 1; i <= n; i++) cin >> a[i];
int p = 0;
for (int i = 1; i <= n; i++) {
if (!vis[a[i]]) p = a[i];
}
if (!p) {
cout << 2 << '\n';
return;
}
for (int i = 1; i <= n; i++) {
if (a[i] == p) continue;
if (vis[a[i]] == 0) {
cout << -1 << '\n';
return;
}
if (a[i] & 1) {
if (a[i] - vis[a[i]] < 2 * p) {
cout << -1 << '\n';
return;
}
} else {
if (a[i] < 2 * p) {
cout << -1 << '\n';
return;
}
}
}
cout << p << '\n';
return;
}
int main() {
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
init(400000);
cin >> T;
while (T--) {
solve();
}
}
Author: sszcdjr
First Blood: taeyeon_ss at 00:16:50
If there are both consecutive $$$\texttt{R}$$$-s and $$$\texttt{B}$$$-s, does the condition hold for all $$$(i,j)$$$? Why?
Suppose that there are only consecutive $$$\texttt{R}$$$-s, check the parity of the number of $$$\texttt{R}$$$-s in each consecutive segment of $$$\texttt{R}$$$-s.
If for each consecutive segment of $$$\texttt{R}$$$-s, the parity of the number of $$$\texttt{R}$$$-s is odd, does the condition hold for all $$$(i,j)$$$? Why?
If for at least two of the consecutive segments of $$$\texttt{R}$$$-s, the parity of the number of $$$\texttt{R}$$$-s is even, does the condition hold for all $$$(i,j)$$$? Why?
Is this the necessary and sufficient condition? Why?
Don't forget some trivial cases like $$$\texttt{RRR...RB}$$$ and $$$\texttt{RRR...R}$$$.
For each $$$k>n$$$ or $$$k\leq0$$$, let $$$c_k$$$ be $$$c_{k\bmod n}$$$.
Lemma 1: If there are both consecutive $$$\texttt{R}$$$-s and $$$\texttt{B}$$$-s, the answer is NO.
Proof 1: Suppose that $$$c_{i-1}=c_i=\texttt{R}$$$ and $$$c_{j-1}=c_j=\texttt{B}$$$, it's obvious that there doesn't exist a palindrome route between $$$i$$$ and $$$j$$$.
Imagine there are two persons on vertex $$$i$$$ and $$$j$$$. They want to meet each other (they are on the same vertex or adjacent vertex) and can only travel through an edge of the same color.
Lemma 2: Suppose that there are only consecutive $$$\texttt{R}$$$-s, if for each consecutive segment of $$$\texttt{R}$$$-s, the parity of the number of $$$\texttt{R}$$$-s is odd, the answer is NO.
Proof 2: Suppose that $$$c_i=c_j=\texttt{B}$$$, $$$i\not\equiv j\pmod n$$$ and $$$c_{i+1}=c_{i+2}=\dots=c_{j-1}=\texttt{R}$$$. The two persons on $$$i$$$ and $$$j$$$ have to "cross" $$$\texttt{B}$$$ simultaneously. As for each consecutive segment of $$$\texttt{R}$$$-s, the parity of the number of $$$\texttt{R}$$$-s is odd, they can only get to the same side of their current consecutive segment of $$$\texttt{R}$$$-s. After "crossing" $$$\texttt{B}$$$, they will still be on different consecutive segments of $$$\texttt{R}$$$-s separated by exactly one $$$\texttt{B}$$$ and can only get to the same side. Thus, they will never meet.
Lemma 3: Suppose that there are only consecutive $$$\texttt{R}$$$-s, if, for at least two of the consecutive segments of $$$\texttt{R}$$$-s, the parity of the number of $$$\texttt{R}$$$-s is even, the answer is NO.
Proof 3: Suppose that $$$c_i=c_j=\texttt{B}$$$, $$$i\not\equiv j \pmod n$$$ and vertex $$$i$$$ and $$$j$$$ are both in a consecutive segment of $$$\texttt{R}$$$-s with even number of $$$\texttt{R}$$$-s. Let the starting point of two persons be $$$i$$$ and $$$j-1$$$ and they won't be able to "cross" and $$$\texttt{B}$$$. Thus, they will never meet.
The only case left is that there is exactly one consecutive segment of $$$\texttt{R}$$$-s with an even number of $$$\texttt{R}$$$-s.
Lemma 4: Suppose that there are only consecutive $$$\texttt{R}$$$-s, if, for exactly one of the consecutive segments of $$$\texttt{R}$$$-s, the parity of the number of $$$\texttt{R}$$$-s is even, the answer is YES.
Proof 4: Let the starting point of the two persons be $$$i,j$$$. Consider the following cases:
Case 1: If vertex $$$i$$$ and $$$j$$$ are in the same consecutive segment of $$$\texttt{R}$$$-s, the two persons can meet each other by traveling through the $$$\texttt{R}$$$-s between them.
Case 2: If vertex $$$i$$$ and $$$j$$$ are in the different consecutive segment of $$$\texttt{R}$$$-s and there are odd numbers of $$$\texttt{R}$$$-s in both segments, the two person may cross $$$\texttt{B}$$$-s in the way talked about in Proof 2. However, when one of them reaches a consecutive segment with an even number of $$$\texttt{R}$$$-s, the only thing they can do is let the one in an even segment cross the whole segment and "cross" the next $$$\texttt{B}$$$ in the front, while letting the other one traveling back and forth and "cross" the $$$\texttt{B}$$$ he just "crossed". Thus, unlike the situation in Proof 2, we successfully changed the side they can both get to and thus they will be able to meet each other as they are traveling toward each other and there are only odd segments between them.
Case 3: If vertex $$$i$$$ and $$$j$$$ are in the different consecutive segment of $$$\texttt{R}$$$-s and there are an odd number of $$$\texttt{R}$$$-s in exactly one of the segments, we can let both of them be in one side of there segments and change the situation to the one we've discussed about in Case 2 (when one of them reached a consecutive segment with even number of $$$\texttt{R}$$$-s).
As a result, the answer is YES if:
- At least $$$n-1$$$ of $$$c_1,c_2,\dots,c_n$$$ are the same (Hint 6), or
- Suppose that there are only consecutive $$$\texttt{R}$$$-s, there's exactly one of the consecutive segments of $$$\texttt{R}$$$-s such that the parity of the number of $$$\texttt{R}$$$-s is even.
And we can judge them in $$$\mathcal{O}(n)$$$ time complexity.
#include <bits/stdc++.h>
using namespace std;
void solve(){
int n; cin>>n;
string s; cin>>s;
int visr=0,visb=0,ok=0;
for(int i=0;i<n;i++){
if(s[i]==s[(i+1)%n]){
if(s[i]=='R') visr=1;
else visb=1;
ok++;
}
}
if(visr&visb){
cout<<"NO\n";
return ;
}
if(ok==n){
cout<<"YES\n";
return ;
}
if(visb) for(int i=0;i<n;i++) s[i]='R'+'B'-s[i];
int st=0;
for(int i=0;i<n;i++) if(s[i]=='B') st=(i+1)%n;
vector<int> vc;
int ntot=0,cnt=0;
for(int i=0,j=st;i<n;i++,j=(j+1)%n){
if(s[j]=='B') vc.push_back(ntot),cnt+=(ntot&1)^1,ntot=0;
else ntot++;
}
if(vc.size()==1||cnt==1){
cout<<"YES\n";
return ;
}
cout<<"NO\n";
return ;
}
signed main(){
int t; cin>>t;
while(t--) solve();
return 0;
}
Count the number of strings of length $$$n$$$ satisfying the condition.
Solve the problem for $$$c_i\in\{\texttt{A},\texttt{B},\dots,\texttt{Z}\}$$$, and solve the counting version.
Author: wyrqwq, Error_Yuan
First Blood: taeyeon_ss at 00:56:22
This problem has two approaches. The first one is the authors' solution, and the second one was found during testing.
The array $$$a$$$ is constructed with the operations. How can we use this property?
If we want to make all $$$a_i=x$$$, what is the minimum value of $$$x$$$? Use the property mentioned in Hint 1.
(For the subproblem in Hint 2), try to find an algorithm related to the positions of $$$\texttt{L/R}$$$-s directly.
(For the subproblem in Hint 2), the conclusion is that, the minimum $$$x$$$ equals $$$\text{# of }\texttt{L}\text{-s} + \text{# of }\texttt{R}\text{-s} - \text{# of adjacent }\texttt{LR}\text{-s}$$$. Think why.
Go for DP.
Read the hints first.
Then, note that there are only $$$\mathcal{O}(V)$$$ useful positions: If (after the initial operations) $$$a_i>V$$$ or $$$a_{i}=a_{i-1}$$$, we can simply ignore $$$a_i$$$, or merge $$$c_i$$$ into $$$c_{i-1}$$$.
Now let $$$dp(i,s)$$$ denote the answer when we consider the prefix of length $$$i$$$, and we have "saved" $$$s$$$ pairs of $$$\texttt{LR}$$$.
Then,
Write $$$\mathrm{cntL}$$$ and $$$\mathrm{cntR}$$$ as prefix sums:
Do casework on the sign of the things inside the $$$\mathrm{abs}$$$, and you can maintain both cases with 1D Fenwick trees.
Thus, you solved the problem in $$$\mathcal{O}(V^2\log V)$$$.
Solve the problem for a single $$$v$$$ first.
Don't think too much, just go straight for a DP solution.
Does your time complexity in DP contain $$$n$$$ or $$$m$$$? In fact, both $$$n$$$ and $$$m$$$ are useless. There are only $$$\mathcal{O}(V)$$$ useful positions.
Use some data structures to optimize your DP. Even $$$\mathcal{O}(v^2\log^2 v)$$$ is acceptable.
Here is the final step: take a look at your DP carefully. Can you change the definition of states a little, so that it can get the answer for each $$$1\le v\le V$$$?
First, note that there are only $$$\mathcal{O}(V)$$$ useful positions: If (after the initial operations) $$$a_i>V$$$ or $$$a_{i}=a_{i-1}$$$, we can simply ignore $$$a_i$$$, or merge $$$c_i$$$ into $$$c_{i-1}$$$.
Now, let's solve the problem for a single $$$v$$$.
Denote $$$dp(i,j,k)$$$ as the maximum answer when considering the prefix of length $$$i$$$, and there are $$$j$$$ prefix additions covering $$$i$$$, $$$k$$$ suffix additions covering $$$i$$$.
Enumerate on $$$i$$$, and it is easy to show that the state changes if and only if $$$j+k+a_i=v$$$, and
You can use a 2D Fenwick tree to get the 2D prefix max. Thus, you solved the single $$$v$$$ case in $$$\mathcal{O}(v^2\log^2 v)$$$.
In fact, we can process the DP in $$$\mathcal{O}(v^2 \log v)$$$ by further optimization:
This only requires $$$a_p+q\ge a_i+j$$$ when $$$a_p\le a_i$$$, and $$$q\le j$$$ when $$$a_p\ge a_i$$$. So you can use 1D Fenwick trees to process the dp in $$$\mathcal{O}(v^2 \log v)$$$.
Now, let's go for the whole solution.
Let's modify the DP state a bit: now $$$dp(i,j,k)$$$ is the state when using $$$v-k$$$ suffix operations (note that $$$v$$$ is not a constant here). The transformation is similar.
Then the answer for $$$v=i$$$ will be $$$\max dp(*,*,i)$$$.
#include <bits/stdc++.h>
#define all(s) s.begin(), s.end()
using namespace std;
using ll = long long;
using ull = unsigned long long;
using ld = double;
const int _N = 4105;
const ld inf = 1e15;
int T;
struct fenwick {
ll c[_N]; int N;
int lowbit(int x) { return x & (-x); }
void init(int n) {
N = n;
for (int i = 1; i <= N; i++) c[i] = -1e18;
}
void update(int x, ll v) {
// assert(x != 0);
while (x < N) {
c[x] = max(c[x], v);
x += lowbit(x);
}
}
ll getmx(int x) {
// assert(x != 0);
ll res = -1e18;
while (x > 0) {
res = max(res, c[x]);
x -= lowbit(x);
}
return res;
}
} pre[4105], suf[4105];
void solve() {
int n, o, m, k; cin >> n >> o >> m;
k = 0;
vector<ll> a(n + 3), c(n + 3), d(n + 3), L(n + 3), R(n + 3), L2(n + 3), R2(n + 3);
for (int i = 1; i <= n; i++) cin >> c[i];
for (int i = 1; i <= o; i++) {
char op; int x; cin >> op >> x;
if (op == 'L') L[x]++;
else R[x]++;
}
vector<int> tL(n + 3), tR(n + 3);
for (int i = 1; i <= n; i++) tR[i] = tR[i - 1] + R[i];
for (int i = n; i >= 1; i--) tL[i] = tL[i + 1] + L[i];
int q = 0, curL = 0, curR = 0;
for (int i = 1; i <= n; i++) {
a[i] = tL[i] + tR[i];
if (a[i] <= m + k) {
if (a[i] == a[i - 1] && L[i] == 0 && R[i] == 0) {
if (q == 0) q++;
d[q] += c[i];
continue;
}
q++;
L2[q] += L[i];
R2[q] += R[i] + curR;
L2[q - 1] += curL;
d[q] += c[i];
curL = curR = 0;
} else {
curL += L[i];
curR += R[i];
}
}
L2[0] = 0; L2[q] += curL;
for (int i = 1; i <= q; i++) L2[i] += L2[i - 1], R2[i] += R2[i - 1];
m += k;
vector<ll> dp(2 * m + 2, -1e18);
for (int i = 0; i <= 2 * m; i++) {
pre[i].init(2 * m + 2);
suf[i].init(2 * m + 2);
}
vector<ll> ans(m + 1);
for (int i = 1; i <= q; i++) {
dp.resize(2 * m + 2, -1e18);
dp[L2[i - 1]] = d[i];
for (int s = 0; s <= m; s++) {
ll res1 = pre[s - L2[i - 1] + m].getmx(R2[i] - L2[i - 1] + m + 1);
ll res2 = suf[s - R2[i] + m].getmx(m + 1 - R2[i] + L2[i - 1]);
dp[s] = max({ dp[s], res1 + d[i], res2 + d[i] });
if (L2[q] + R2[i] - s >= 0 && L2[q] + R2[i] - s <= m) ans[L2[q] + R2[i] - s] = max(ans[L2[q] + R2[i] - s], dp[s]);
}
for (int s = 0; s <= m; s++) {
if (dp[s] <= -1e12) continue;
pre[s - L2[i - 1] + m].update(R2[i] - L2[i - 1] + m + 1, dp[s]);
suf[s - R2[i] + m].update(m + 1 - R2[i] + L2[i - 1], dp[s]);
}
}
for (int i = 1; i <= m; i++) {
ans[i] = max(ans[i - 1], ans[i]);
cout << ans[i] << " \n"[i == m];
}
return;
}
int main() {
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
cin >> T;
while (T--) {
solve();
}
}
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define pb push_back
#define pii pair<int, int>
#define all(a) a.begin(), a.end()
const int mod = 1e9 + 7, N = 5005;
void solve() {
int n, m, V;
cin >> n >> m >> V;
vector <int> c(n);
for (int i = 0; i < n; ++i) {
cin >> c[i];
}
vector <int> pre(n + 1);
for (int i = 0; i < m; ++i) {
char x; int v; cin >> x >> v, --v;
if (x == 'L') {
pre[0]++, pre[v + 1]--;
} else {
pre[v]++;
}
}
for (int i = 0; i < n; ++i) {
pre[i + 1] += pre[i];
}
vector <pair <ll, int>> vec;
for (int i = 0, j = 0; i < n; i = j) {
ll tot = 0;
while (j < n && pre[i] == pre[j]) {
tot += c[j], j++;
}
if (pre[i] <= V) {
vec.emplace_back(tot, pre[i]);
}
}
vector bit(V + 5, vector <ll>(V + 5, -1ll << 60));
auto upd = [&](int x, int y, ll v) {
for (int i = x + 1; i < V + 5; i += i & (-i)) {
for (int j = y + 1; j < V + 5; j += j & (-j)) {
bit[i][j] = max(bit[i][j], v);
}
}
};
auto query = [&](int x, int y) {
ll ans = -1ll << 60;
for (int i = x + 1; i > 0; i -= i & (-i)) {
for (int j = y + 1; j > 0; j -= j & (-j)) {
ans = max(ans, bit[i][j]);
}
}
return ans;
};
upd(0, 0, 0);
vector <ll> tmp(V + 1);
for (auto [val, diff] : vec) {
for (int i = 0; i + diff <= V; ++i) {
tmp[i] = query(i, i + diff);
}
for (int i = 0; i + diff <= V; ++i) {
upd(i, i + diff, tmp[i] + val);
}
}
for (int i = 1; i <= V; ++i) {
cout << query(i, i) << " \n"[i == V];
}
}
int main() {
ios::sync_with_stdio(false), cin.tie(0);
int t;
cin >> t;
while (t--) {
solve();
}
}
Solve the problem in $$$\mathcal{O}(V^2)$$$.
Author: sszcdjr
First Blood: Benq at 02:04:40 (though unintended brute force), jiangly at 02:55:12 (intended, orz!)
It's hard to calculate the expected number. Try to change it to the probability.
Consider a $$$\mathcal{O}(3^n)$$$ dp first.
Use inclusion and exclusion.
Write out the transformation. Try to optimize it.
Let $$$dp_S$$$ be the probability such that exactly the points in $$$S$$$ have the message.
The answer is $$$\sum dp_S\cdot tr_S$$$, where $$$tr_S$$$ is the expected number of days before at least one vertex out of $$$S$$$ to have the message (counting from the day that exactly the points in $$$S$$$ have the message).
For transformation, enumerate $$$S,T$$$ such that $$$S\cap T=\varnothing$$$. Transfer $$$dp_S$$$ to $$$dp_{S\cup T}$$$. It's easy to precalculate the coefficient, and the time complexity differs from $$$\mathcal{O}(3^n)$$$, $$$\mathcal{O}(n\cdot 3^n)$$$ to $$$\mathcal{O}(n^2\cdot 3^n)$$$, according to the implementation.
The transformation is hard to optimize. Enumerate $$$T$$$ and calculate the probability such that vertices in $$$S$$$ is only connected with vertices in $$$T$$$, which means that the real status $$$R$$$ satisfies $$$S\subseteq R\subseteq (S\cup T)$$$. Use inclusion and exclusion to calculate the real probability.
List out the coefficient:
(Note that $$$w_e$$$ denotes the probability of the appearance of the edge $$$e$$$)
We can express it as $$$\mathrm{Const}\cdot f_{S\cup T}\cdot g_S\cdot h_T$$$. Use a subset convolution to optimize it. The total time complexity is $$$\mathcal{O}(2^n\cdot n^2)$$$.
It's easy to see that all $$$dp_S\neq0$$$ satisfies $$$1\in S$$$, so the time complexity can be $$$\mathcal{O}(2^{n-1}\cdot n^2)$$$ if well implemented.
#include <bits/stdc++.h>
#define int long long
using namespace std;
const int N=(1<<21),mod=998244353;
const int Lim=8e18;
inline void add(signed &i,int j){
i+=j;
if(i>=mod) i-=mod;
}
int qp(int a,int b){
int ans=1;
while(b){
if(b&1) (ans*=a)%=mod;
(a*=a)%=mod;
b>>=1;
}
return ans;
}
int dp[N],f[N],g[N],h[N];
int s1[N],s2[N];
signed pre[22][N/2],t[22][N/2],pdp[N][22];
int p[N],q[N],totp,totq;
signed main(){
int n,m; cin>>n>>m;
int totprod=1;
for(int i=0;i<(1<<n);i++) s1[i]=s2[i]=1;
for(int i=1;i<=m;i++){
int u,v,p,q; cin>>u>>v>>p>>q;
int w=p*qp(q,mod-2)%mod;
(s1[(1<<(u-1))+(1<<(v-1))]*=(mod+1-w))%=mod;
(s2[(1<<(u-1))+(1<<(v-1))]*=qp(mod+1-w,mod-2))%=mod;
(totprod*=(mod+1-w))%=mod;
}
for(int j=1;j<=n;j++) for(int i=0;i<(1<<n);i++) if((i>>(j-1))&1) (s1[i]*=s1[i^(1<<(j-1))])%=mod,(s2[i]*=s2[i^(1<<(j-1))])%=mod;
for(int i=0;i<(1<<n);i++) f[i]=s2[i],g[i]=totprod*s2[((1<<n)-1)^i]%mod*qp(mod+1-totprod*s2[i]%mod*s2[((1<<n)-1)^i]%mod,mod-2)%mod,h[i]=s1[i];
for(int i=1;i<(1<<n);i++) pre[__builtin_popcount(i)][i>>1]=h[i];
dp[1]=1;
for(int j=1;j<=n;j++){
if(!((1>>(j-1))&1)) add(pdp[1|(1<<(j-1))][j],mod-(dp[1]*g[1]%mod*f[1]%mod));
}
t[0][0]=dp[1]*g[1]%mod;
for(int k=1;k<=n;k++) for(int j=1;j<n;j++) for(int i=0;i<(1<<(n-1));i++) if((i>>(j-1))&1) add(pre[k][i],pre[k][i^(1<<(j-1))]);
for(int j=1;j<n;j++) for(int i=0;i<(1<<(n-1));i++) if((i>>(j-1))&1) add(t[0][i],t[0][i^(1<<(j-1))]);
for(int k=1;k<n;k++){
totp=totq=0;
for(int i=0;i<(1<<(n-1));i++) if(__builtin_popcount(i)<=k) p[++totp]=i; else q[++totq]=i;
for(int l=1,i=p[l];l<=totp;l++,i=p[l]) for(int j=0;j<k;j++) add(t[k][i],1ll*t[j][i]*pre[k-j][i]%mod);
for(int i=0;i<(1<<(n-1));i++) t[k][i]%=mod;
for(int j=1;j<n;j++) for(int l=1,i=p[l];l<=totp;l++,i=p[l]) if((i>>(j-1))&1) add(t[k][i],mod-t[k][i^(1<<(j-1))]);
for(int i=0;i<(1<<(n-1));i++){
if(__builtin_popcount(i)==k){
add(pdp[(i<<1)|1][0],t[k][i]*f[(i<<1)|1]%mod);
int pre=0;
for(int j=1;j<=n;j++){
(pre+=pdp[(i<<1)|1][j-1])%=mod;
if(!((((i<<1)|1)>>(j-1))&1)) add(pdp[(i<<1)|1|(1<<(j-1))][j],mod-pre);
}
(pre+=pdp[(i<<1)|1][n])%=mod;
dp[(i<<1)|1]=pre;
for(int j=1;j<=n;j++){
if(!((((i<<1)|1)>>(j-1))&1)) add(pdp[(i<<1)|1|(1<<(j-1))][j],mod-(dp[(i<<1)|1]*g[(i<<1)|1]%mod*f[(i<<1)|1]%mod));
}
t[k][i]=pre*g[(i<<1)|1]%mod;
}
else t[k][i]=0;
}
for(int j=1;j<n;j++) for(int l=1,i=q[l];l<=totq;l++,i=q[l]) if((i>>(j-1))&1) add(t[k][i],t[k][i^(1<<(j-1))]);
}
int ans=0;
for(int i=1;i<(1<<n)-1;i+=2) (ans+=dp[i]*qp(mod+1-totprod*s2[i]%mod*s2[((1<<n)-1)^i]%mod,mod-2)%mod)%=mod;
cout<<ans;
return 0;
}
Author: Error_Yuan
First Blood: rainboy at 01:33:40 (intended, the only solve in contest, orz!)
The intended solution has nothing to do with dynamic programming.
This is the key observation of the problem. Suppose we have an array $$$b$$$ and a function $$$f(x)=\sum (b_i-x)^2$$$, then the minimum value of $$$f(x)$$$ is the variance of $$$b$$$.
Using the observation mentioned in Hint 2, we can reduce the problem to minimizing $$$\sum(a_i-x)^2$$$ for a given $$$x$$$. There are only $$$\mathcal{O}(n\cdot m)$$$ possible $$$x$$$-s.
The rest of the problem is somehow easy. Try flows, or just find a greedy algorithm!
If you are trying flows: the quadratic function is always convex.
Key Observation. Suppose we have an array $$$b$$$ and a function $$$f(x)=\sum (b_i-x)^2$$$, then the minimum value of $$$f(x)$$$ is the variance of $$$b$$$.
Proof. This is a quadratic function of $$$x$$$, and the its symmetry axis is $$$x=\frac{1}{n}\sum b_i$$$. So the minimum value is $$$f\left(\frac{1}{n}\sum b_i\right)$$$. That is exactly the definition of variance.
Thus, we can enumerate all possible $$$x$$$-s, and find the minimum $$$\sum (a_i-x)^2$$$ after the operations, then take the minimum across them. That will give the correct answer to the original problem. Note that there are only $$$\mathcal{O}(n\cdot m)$$$ possible $$$x$$$-s.
More formally, let $$$k_{x,c}$$$ be the minimum value of $$$\sum (a_i-x)^2$$$ after exactly $$$c$$$ operations. Then $$$\mathrm{ans}_i=\displaystyle\min_{\text{any possible }x} k_{x,i}$$$.
So we only need to solve the following (reduced) problem:
- Given a (maybe non-integer) number $$$x$$$. For each $$$1\le i\le m$$$, find the minimum value of $$$\sum (a_i-x)^2$$$ after exactly $$$i$$$ operations.
To solve this, we can use the MCMF model:
- Set a source node $$$s$$$ and a target node $$$t$$$.
- For each $$$1\le i\le n$$$, add an edge from $$$s$$$ to $$$i$$$ with cost $$$0$$$.
- For each $$$1\le i\le n$$$, add an edge from $$$i$$$ to $$$t$$$ with cost $$$0$$$.
- For each $$$1\le i< n$$$, add an edge from $$$i$$$ to $$$i+1$$$ with cost being a function $$$\mathrm{cost}(f)=(a_i+f-x)^2-(a_i-x)^2$$$, where $$$f$$$ is the flow on this edge.
- Note that the $$$\mathrm{cost}$$$ function is convex, so this model is correct, as you can split an edge into some edges with cost of $$$\mathrm{cost}(1)$$$, $$$\mathrm{cost}(2)-\mathrm{cost}(1)$$$, $$$\mathrm{cost}(3)-\mathrm{cost}(2)$$$, and so on.
Take a look at the model again. We don't need to run MCMF. We can see that it is just a process of regret greedy. So you only need to find the LIS (Largest Interval Sum :) ) for each operation.
Thus, we solved the reduced problem in $$$\mathcal{O(n\cdot m)}$$$.
Overall time complexity: $$$\mathcal{O}((n\cdot m)^2)$$$ per test case.
Reminder: don't forget to use __int128 if you didn't handle the numbers carefully!
#include <bits/stdc++.h>
#define all(s) s.begin(), s.end()
using namespace std;
using ll = long long;
using ull = unsigned long long;
const int _N = 1e5 + 5;
int T;
void solve() {
ll n, m, k; cin >> n >> m >> k;
vector<ll> a(n + 1);
for (int i = 1; i <= n; i++) cin >> a[i];
vector<ll> kans(m + 1, LLONG_MAX);
vector<__int128> f(n + 1), g(n + 1), v(n + 1);
vector<int> vis(n + 1), L(n + 1), L2(n + 1);
ll sum = 0;
for (int i = 1; i <= n; i++) sum += a[i];
__int128 pans = 0;
for (int i = 1; i <= n; i++) pans += n * a[i] * a[i];
auto work = [&](ll s) {
__int128 ans = pans;
ans += s * s - 2ll * sum * s;
f.assign(n + 1, LLONG_MAX);
g.assign(n + 1, LLONG_MAX);
for (int i = 1; i <= n; i++) {
v[i] = n * (2 * a[i] * k + k * k) - 2ll * s * k;
vis[i] = 0;
}
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
L[j] = L2[j] = j;
if (f[j - 1] < 0) f[j] = f[j - 1] + v[j], L[j] = L[j - 1];
else f[j] = v[j];
if (!vis[j]) {
g[j] = LLONG_MAX;
continue;
}
if (g[j - 1] < 0) g[j] = g[j - 1] + 2ll * n * k * k - v[j], L2[j] = L2[j - 1];
else g[j] = 2ll * n * k * k - v[j];
}
__int128 min_sum = LLONG_MAX;
int l = 1, r = n, type = 0;
for (int j = 1; j <= n; j++) {
if (f[j] < min_sum) {
min_sum = f[j], r = j, l = L[j];
}
}
for (int j = 1; j <= n; j++) {
if (g[j] < min_sum) {
min_sum = g[j], r = j, l = L2[j];
type = 1;
}
}
ans += min_sum;
if (type == 0) {
for (int j = l; j <= r; j++) vis[j]++, v[j] += 2 * n * k * k;
} else {
for (int j = l; j <= r; j++) vis[j]--, v[j] -= 2 * n * k * k;
}
kans[i] = min((__int128)kans[i], ans);
}
};
for (ll x = sum; x <= sum + n * m * k; x += k) {
work(x);
}
for (int i = 1; i <= m; i++) cout << kans[i] << " \n"[i == m];
return;
}
int main() {
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
cin >> T;
while (T--) {
solve();
}
}






fast edi yay!
I do C with binary search. It's really crazy to see the binary search in this problem.
I screwed up the 3rd claim for E I thought only primes less than equal to $$$\frac{A}{MinDiv[A]}$$$ will work (for composite A)
Same here. I made a false proof.
Exact same bro, I didnt realize you get 2 as divisor by just going to 2*p. Realized a minute too late
I had a slightly different approach for D: for each edge (u,v) with u!=1,v!=1, do operation (1,u,v). then you have a star-tree centered at 1, and a bunch of lone-nodes, then do as in the editorial to connect the lone-nodes
Cool solution! Nice idea, easier to implement than the solution in the editorial (in my opinion) and linear time complexity.
Cool Solution for Cool Graph..... Nice!
And here is what I think to be good implementation of this idea in $$$O(n+m)$$$
Implementation
In B, if(count of 1 in s — count of 0 in r(don't check for last element in r)==1) cout<<"YES";
Hah, I like the Palindrome one
I thought of C as dp but screwed up because for some reason my mind didn't tell me that it's enough to store the maximum rating in the dp
Same
dammn
rainboy is like just so cool ! is he indian ( i saw some grp photo ) ?
H: Thanks for setting the time limit just above my solution's runtime! :)
Our testers' solution (which is $$$\mathcal{O}(n^2\cdot 2^n)$$$) runs for ~10s. :(
for c can any one show there recursive dp solution ?
https://codeforces.me/contest/2029/submission/290805014
can you please explain the j==2 condition in recursion. why opt2= rec(i-1,1), I thought it to be opt2 = f(rec(i-1, 1), v[i]) ?
Because j==2 is closing the skipped segment , so if you are closing the segment at i index , this ith index is also skipped ( you dont need to compare rec(i-1,1) with this v[i] ).
O(n+m) solution for problem D 290751143
in problem E,why are we only considering lowest divisor of x i.e mind(x) for checking if x can be obtained from any generator?
Because for any x, the minimum divisor is either an odd prime or 2, if it's 2 then it can easily be obtained, if it's not 2 then x — mind(x) is even which reduces the problem to checking even numbers only, and for a prime generator p not equal to 2, we can generate all even numbers >= p * 2
why is it necessary that we get x from x-mind(x) only,its just written as a statement,why cant we get x from (x-y)+y where y is some other divisor other than the minimum one?
We can always get x from another x — y. mind(x) is taken for proof's sake.
Because, we can generate all even numbers from a certain point. x — mind(x) basically gives you the largest even number smaller than x that can produce x, let's call it y. That is because if mind(x) | x then mind(x) | x — mind(x). It's kind of like the euclid algorithm for gcd. If you subtract a divisor of a number from the said number, the result will still be divisible by the said number. Basically, you can use larger divisors but there is no point because the difference will always be even, and if we can generate an even number n then we can generate any larger even number. So if any divisor works, then any smaller one does too
why are we sure that x-mind(x) can generate x?
X-mind(x)+mind(x)=x,mind(x) divides (x-mind(x)) so we can add it in x-mind(x) to get x
Actually for problem E it turned out that it's possible to get AC with time complexity $$$\mathcal{O}(\sum n + tV)$$$, though it required me to use bitsets, fast input/output template and some number of identical submissions till i got the lucky one 290762920.
Also one of my TL'ed submissions during the contest passes with 1.3s after the system testing. Is there any reason? 290772979 and 290758813
I had a simpler DP approach for problem C:
Let $$$ \text{dp}[i] $$$ represent the maximum rating that can be achieved such that $$$ r \leq i $$$.
The base case is $$$ \text{dp}[1] = 0 $$$.
Either $$$ r < i $$$ or $$$ r = i $$$. Hence,
$$$ \text{dp}[i] = \max\left( f(\text{dp}[i-1], \, a[i]), \, \underset{1 \leq j < i}{\max} (f[j]) \right) $$$
The definitions of $$$ f(a, \, x) $$$ and $$$ f[i] $$$ are the same as given in the editorial.
The final answer is simply $$$ \text{dp}[n] $$$.
Code: 290775108
i cant process this at all
I think it's pretty clear for $$$r < i$$$, it's $$$f(dp[i-1], a[i])$$$.
Now coming to $$$r = i$$$, you have to choose $$$l$$$ such that after skipping $$$[l, r]$$$, you get the maximum rating possible, that's what the second term represents. Let me know if it's still unclear!
thanks!
script>hihi<\script
I feel like the problem statement of B could have been better
There's an $$$O(V^2)$$$ solution in G, see here: 290755809
My solution for D is a bit different:
First I try to remove all cycles, I do so by erasing all edges (u,v) with u != 1 and v != 1, so that all the remaining edges are in the form (1,u), we can achieve this by making moves of the type (1,u,v).
You keep track of the edges being added and removed using a set, this is useful because you keep track of which nodes are connected to 1 or are isolated.
Now all that remains are some isolated nodes and a tree with root 1: all I do is choose a random node A different from 1 in the tree, and for each isolated node B I make the move (1,A,B), as to add B to the tree, then I assign B to A and continue adding isolated nodes to the tree.
Of course, if the tree only consists of 1 and A doesn't exist, you stop there.
Thanks for the contest! About Problem H:
For the $$$\Theta(3^n)$$$ passing, I received too much bonus :) && :(
The problem itself is interesting, and upsolving in $$$O(2^n n^2)$$$ was a nice practice to me. Perhaps "to optimize it." in the editorial hides a tough detail — something like semi-relaxed convolution is unavoidable, right?
I'm afraid your $$$\Theta (3^n)$$$ is way too fast, sad as one of the setters, but anyway congrats!
On "hiding a tough detail", here is sszcdjr's opinion: nearly every Chinese knows it.
Can you provide more details? I feel that there's a lot of room for improvement in the editorial quality for this problem. I'm stuck on $$$\Theta(2^nn^3)$$$ right now which is slightly too slow.
I'm sorry but the editorial is written by sszcdjr... Judging from your time complexity, I guess you are having difficulty with the so-called subset convolution technique. (idk if my explanation is correct and clear but I hope so, so plz correct me if there is any mistake)
We are given $$$f_{0\dots (2^n-1)}$$$ and $$$g_{0\dots (2^n-1)}$$$. We want to calculate
Assume you know how to perform FWT. Then one can see $0$ (why I have to add a random LaTeX here to make the following LaTeX showing properly), $$$i \operatorname{and} j = 0 \iff \operatorname{popcount}(i) + \operatorname{popcount}(j) = \operatorname{popcount}(i \operatorname{or} j)$$$, so let's denote
(the same for $G_{i,j}$), thus for each $$$s = \operatorname{popcount}(k) \in [0, n]$$$, we can calculate $$$H_s = \operatorname{IFWT}\left( \sum_{j=0}^{s} \operatorname{FWT}(F_j)_i \cdot \operatorname{FWT}(G_{s-j})_i \right)$$$ (it works because it's a linear transform), then $$$h_k = H_{\operatorname{popcount}(k), k}$$$.
This would work in $$$\mathcal O(2^nn^2)$$$.
Naturally we can do no adaptation to make it "online", because we calculate $$$h_k$$$ in the ascending order of $$$\operatorname{popcount}(k)$$$ so it still works in the same time complexity when $$$f, g$$$ turn out to have something to do with $$$h$$$ (but for NTT, the case is somehow different).
Thanks. I understand how subset convolution works but the part that I don't get is the "online" part that you mentioned in the last paragraph.
Edit: I think I might understand now... will try to implement later.
Edit 2: Here's a sort of high-level explanation in case anyone has the same issue as I did.
Like the editorial says, we have some formula where $$$f(S\cup T)$$$ depends on $$$f(S)$$$, $$$g(T)$$$, $$$h(S\cup T)$$$ where $$$g$$$ and $$$h$$$ are precomputed functions. I was calculating $$$f(S)$$$ in layers based on $$$|S|$$$, and at each step I did one subset convolution to get the contributions to $$$f(S\cup T)$$$. This involves doing one SOS transform on $$$f(S)$$$, multiplying with the SOS transforms for $$$g$$$ (precomputed), and then doing the reverse SOS transform afterward. The last step of doing the reverse SOS transform takes $$$O(n\times 2^n)$$$ time, and furthermore iterated over $$$|S|$$$ and $$$|S\cup T|$$$ for $$$O(2^nn^3)$$$ time complexity. The solution is to defer the reverse SOS transform step until you are on the relevant value of $$$|S|$$$, so it's only done once per size for $$$O(2^nn^2)$$$ time complexity.
If you came to this time complexity, you definitely understand the editorial much better than I am. I am basically stuck on the first line. What does "Let $$$dp_S$$$ be the probability such that exactly the points in $$$S$$$ have the message" even mean? Probability at what point in time? And then the formula following about $$$\sum_S dp_S \cdot tr_S$$$ I also don't understand the meaning of. Could you please help me a bit here?
$$$dp_S$$$ means that the probability that there exists some certain time, such that exactly the points in $$$S$$$ have the message.
I ENJOYED ALL PROBLEMS, KUDOS to the authors
In solution 1 of problem G, the notations are not clear at all. Can anyone can explain what does "saved" s pairs of LR mean? Also, what is preL and preR?
preLandpreRare just the prefix sum array ofcntLandcntR.Thanks! And what is "saved" s pairs of LR?
am I the only one who thought C was easier than B
Conclusion Forces
Amazing problem C. I had thought about binary searching the answer but didn't come up with the solution, but I managed to solve it using dp. It's really cool to see that both approach work.
D problem's solution is short and useful.My solution is find the rings and delete them, but I can't realize it.
Problem D is very similar to 104770D - Перерисованный граф
I'm sorry to hear that... We didn't know the existence of this problem before :(
Although the statements are very similar, solutions are different enough, no need to apologize :) had a lot of fun solving the problems!
C — Kevin's hacking shouldn't go in vain so he must choose at least one element to skip even it reduces his rating.
can anyone explain my tle in problem E 290847100 I think my time complexity is
nlogn + √mx*loglog(mx)*logn + n where mx=max of all ai, i varies from 1 to n and n<=10^5
how do it in my way? can we do it?
For each testcase you allocate vectors (prime and small) of size mx, it takes O(mx) time. You can create and calculate these vectors one time at the beginning.
thank you. I solved it by pre calculating them.
Could anyone help me prove why my solution for problem B https://codeforces.me/contest/2029/submission/290742944 is correct?
As it's binary, considering string s+r(exclude the final character of string r, as it's irrelevant to the result), only when the number of '0' equals to that of '1' do we return "YES". Otherwise, it would return "NO". Is it just a coincidence for my correctness?
pls help <3
In essence, your solution mirrors AaravSin's solution. Let $$$x$$$ represent the number of 1's in
s, and $$$y$$$ represent the number of 1's inr, excluding the last character. AaravSin's solution uses $$$x - (n-2 - y) = 1$$$, which is equivalent to your solution, expressed as $$$x + y = n - 1$$$. Hope it helps.Thx, it really helps :)
why I *3400, is this rainboy's opinion?
In Problem C, can someone explain something lies in this line .
I'm confused about the case when $$$a_i=curg$$$, I understand both cases when $$$a_i>curg$$$ and $$$a_i<curg$$$, but I can't understand $$$a_i=curg$$$, why doing $$$curg$$$-- works just fine?
I'm assuming that when $$$a_i<curg$$$ that means when we take this number it will decrease our rating, so will increase $$$curg$$$ so we can try to get the point we just lost, and when $$$a_i>curg$$$ that means when we take this number our rating will increase so now we need to try to get $$$curg-1$$$ instead of $$$curg$$$, because we just got a new point.
Note that:
Then we see that if $$$curg=a_i$$$, when the rating is $$$curg-1$$$, it will increase by $$$1$$$ after the $$$i$$$-th contest, because $$$curg-1<a_i$$$. Thus, $$$g_{i-1}=curg-1$$$ instead of $$$curg$$$.
Thanks for explaining.
.
Can anyone explain the proof of how the array g is constructed in the editorial of solution 1 of problem C (new_rating)?
This my current thought process but for some reason it does not reach me to the conclusion in the editorial?
So, our base case starts from the back. We know that g[n + 1] = k because before we take another contest after finishing the first n contests (all of them) we need a rating of at least k.
Because we have g[n + 1] we can start populating it backwards. So the general question is what is g[i] in terms of g[i + 1]. g[i + 1] basically gives us the minimum rating after the first i contests, so what that means is that I can get my rating for the first i — 1 contests, g[i], and somehow compare this with a[i] to see what g[i + 1] is. If (a[i] > g[i]), we perform better on the ith contest than we should, g[i + 1] = g[i] + 1, thus g[i] = g[i + 1] — 1. However, I'm stuck because the casework for g[i] depends on g[i], which we don't have yet, so it seems impossible.
May someone tell me how to fix my logic?
For $$$a_i > g_i$$$, since all $$$a$$$ and $$$g$$$ are integers, we have $$$a_i \ge g_i + 1 = g_{i+1}$$$.
Wait that's genius thanks. We can just add one the other side, to turn g[i] to g[i + 1].
in D why we dont pop elements of s?
The solution to D is very well explained.
Why does "the minimum x equals # of L-s+# of R-s−# of adjacent LR-s" and what means adjacent LR-s. Is it like if we have L at number i and R and number i+1. Can somebody explain? Thanks in advance!
I did B, by first calculating what's the max amount of 0's and 1's string s can absorb such that it cant be modified further(using stack), then i just iterated the 2nd string, checking if 0 absorption count or 1 absorption count falls to 0, and then we break,the loop.
The dp used in this is called state machine dp https://jimmy-shen.medium.com/dp-state-machine-ae3177c93a03 .
(degi for every i)->(The graph is a forest). what's the meaning of this hint? I can't see any connection with the solution. In the solution, the author doesn’t make any vertex’s deg to be 1. Actually, he add degree.