


Иногда я задумываюсь, какую реализацию дерева отрезков написать в задаче. Обычно я при помощи метода "пальцем в небо" выбираю какую-то и в большинстве случаев она проходит ограничения.
Я решил подвести основу, так сказать базу, под этот выбор и протестировал на производительность 4 разные реализации:
- Простой рекурсивный "Разделяй и властвуй" Код
- Оптимизированный рекурсивный "Разделяй и властвуй", который не спускается в заведомо ненужных сыновей. Код
- Нерекурсивная реализация (взял отсюда: https://codeforces.me/blog/entry/18051) Код
- Дерево Фенвика Код
Все реализации поддерживают такие запросы:
-
get(l, r): сумма на отрезке (полуинтервале) $$$[l; r)$$$ -
add(i, x): прибавление к элементу под индексом $$$i$$$ числа $$$x$$$
Вот результаты: 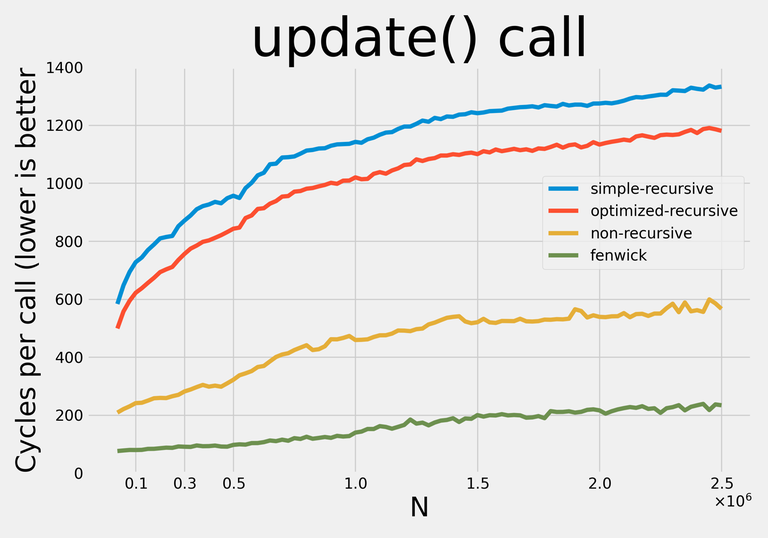
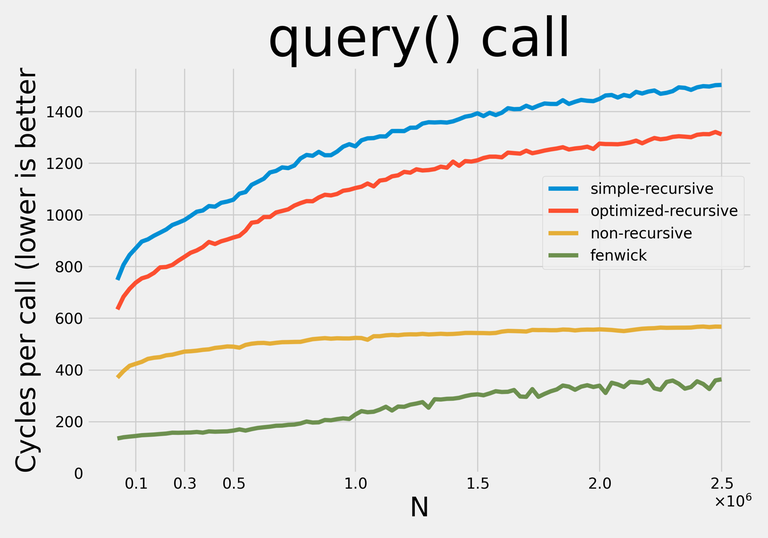
Примечание: я старался не делать никаких оптимизаций, требовательных к конкретным запросам, чтобы с небольшими изменениями структуры данных могли применяться для любых операций.
Я генерировал запросы следующим образом:
- Прибавление в точке: случайный индекс (
rnd() % size) и случайное число - Сумма на отрезке: сначала, генерируется длина отрезка (
rnd() % size + 1), затем подходящая левая граница.
Исходники бенчмарка. Примечание: желательно отключить CPU frequency scaling, закрыть все приложения, которые могут мешать бенчмарку (чем больше закроете -- тем в теории стабильнее будет результат) и "прибить" процесс к конкретному CPU.
Скрипт на Python, создающий красивый график
Результаты в формате JSON на случай, если Вы захотите ещё поиграться с данными.
Я компилировал бенчмарк с #pragma GCC optimize("O3") на GNU GCC 11.3.0, запускал его с фиксированной частотой процессора 2.4 GHz, прикрепив к конкретному ядру процессора.
Наверное, это мой первый вклад в сообщество, поэтому любые дополнения/предложения приветствуются.







Auto comment: topic has been updated by pavook (previous revision, new revision, compare).
Автокомментарий: текст был обновлен пользователем pavook (предыдущая версия, новая версия, сравнить).
All good, but benchmark have 1 error: Fenwick != Segment tree
Although it's technically true, Fenwick tree and non-recursive segment tree are similar both in structure and in performance. It's also a frequent "dilemma": implementing Fenwick tree or segment tree, so its addition felt appropriate.
I do not consider the Fenwick tree and the non-recursive segment tree to be similar in structure.
You can think of a Fenwick tree as a complete segment tree with all right children removed.
Even if it's true, you still can't perform many types of complex operations using Fenwick tree, so imho Fenwick tree is quite useless for regular contests... Anyway, thanks for the blog, it was really interesting :)
Fenwick tree is useful when TL is tight or (if the task allows) if writing a Segment tree will be too long.
I think a pointer-based segment tree is missing.
Thanks for the job you have already done!
However, in my option, it doesn't provide any useful information. It's more a toy research project as you eventually learn different segment tree implementation than a serious benchmark because it simply says something like recursive > non-recursive > fenwick as expected with g glance.
To improve, I list several possible direction here:
Thank you very much for the suggestions.
Notably, non-recursive query has a remarkably constant constant :).
The sudden jumps in update constant plot you can see (at $$$N \approx 275000$$$ for recursive implementations, at $$$N \approx 450000$$$ for non-recursive implementation) align quite nicely with tree sizes beginning not to fit in my 8M L3 Cache.
I couldn't figure anything else special about the plots, so any help/ideas would be appreciated.
CPU model: Intel(R) Core(TM) i5-1135g7. I did run it in full-power mode (perf-bias set to 0 and perf-policy set to performance). I reran the benchmark with pinning the process to a CPU core using
taskset, thank you for this advice.About cache misses and other advanced metrics: I feel like that information would be quite a pain in the butt to collect. I don't know how to measure those metrics except for tools like
perf. But if I'm going useperfor something similar, I'll need to run all the instances separately and collect the results separately. That would really blow up the complexity of running the benchmark.Автокомментарий: текст был обновлен пользователем pavook (предыдущая версия, новая версия, сравнить).
Auto comment: topic has been updated by pavook (previous revision, new revision, compare).