Hello again, It’s Arpa as usual :P. Hope you enjoyed from the Gym, and it’s here is the editorial.
Problem packages are available here. Solutions are available here separately.
Preparation details:
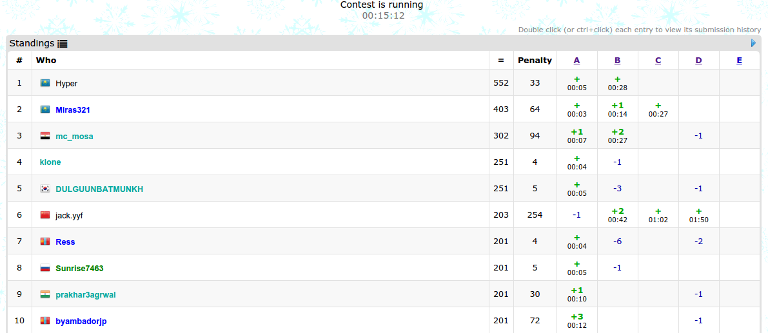
The problems authored by me when the main contest was authoring. Here is a table, showing the percentage of expected accepts (in my opinion, before the contest) and the number of accepts.
| A | B | C | D | |
| Expected | 100% | 30% | 70% | 10% |
| Accepted | 27 | 0 | 8 | 0 |
Difference from main problems
A : n is bigger, binary_pow will not work. You need to calculate 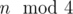 in a faster way.
in a faster way.
B : n and also numbers are much bigger, simple xor will not work.
C : n is bigger, simple LCM will not work because the answer would become really large.
D : Number of alphabets are 26 instead of 22, so it isn’t possible to allocate an array with size 2z (z = 26).
Hints
A : Write the last digit of 1378n for several small values. Calculate in a fast way.
B : Note that if 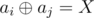 then
then 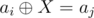 . Use trie.
. Use trie.
C : If the answer exists, it depends on the lengths of cycles in the functional graph. Factorize numbers and calculate LCM.
D : Keep a mask for each vertex, i-th bit of maskv is true if the number of edges in the path from the root to v such that letter i is written on them is odd. Now if number of bits in  is 0 or 1, path between v and u is Dokhtar-kosh. Give an id to each mask.
is 0 or 1, path between v and u is Dokhtar-kosh. Give an id to each mask.
Details
First accepts: A : retired_coder, C : wrinx.
Funniest code : shengdebao ’s code : 23229169. He was managing to get accepted in problem C, with a 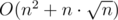 solution :O.
solution :O.
Solutions
I’d like to finish the editorial with the below poem by Saadi Shirazi:
Translation: No one knows the value of good friend as I know, fish will know the value of water when it falls on the beach.
Goodbye ; )







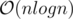 time (for all of the queries)?
time (for all of the queries)? .
. .
.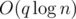 time (for
time (for