


Update: Due to popular request, we created a script for you to generate your own rating profile. For detailed instructions, refer to our ui page on github. We plan to rewrite our code in Javascript to expand functionality, but hopefully this is helpful in the meantime. Please let us know if you have any suggestions!
This project was written jointly with yj12.
Several heuristics exist for finding suitable practice problems on Codeforces. One common piece of advice is to sort all problems by the number of solvers and to work down the list. However, the number of solvers depends on a number of factors, including the recency of the contest, and the date and time the contest was held. Another heuristic is to try to solve problems at a certain level, for instance, all Div. 1 C problems. However, the difficulty of such problems can vary greatly from contest to contest.
We decided to create a better measure of problem difficulty, which we’ll call “problem rating”. Problem rating is an integral value, with higher problem ratings reflecting harder problems. In order for the rating to be meaningful, we made it mathematically compatible with user ratings. Technically, problem rating is the rating of a hypothetical contestant such that his/her expected rank equals the number of participants who solved the problem. In practice, if you meet a problem whose rating is equal to your rating, you are expected to solve it in half of your contests. To give you some intuition into this number, say there is a contest with 10 contestants rated 2000. If 5 of those contestants solved it (and 5 did not), the problem would be rated 2000. If 7 solved the problem, it would be rated 1852. If 9 solved the problem, it would be rated 1618. For convenience, we give problems solved by all users a rating of 0 and problems solved by no users a rating of 5000.
Of course, there are some shortcomings to this approach. For instance, not all problems are equally attempted by all contestants during a contest; most of us are much more likely to attempt earlier problems than later ones. Furthermore, since users who don’t solve any problems don’t count as participants, our ratings are deflated, especially when the first problem of a problem set is difficult. These are issues we hope to address as we refine our ratings in the future.
We’ve provided a list of problem ratings at our github page. Instead of ordering by the number of people who solved each problem, you could personalize your list by practicing problems in a target range.
Do we actually get more points for solving harder questions?
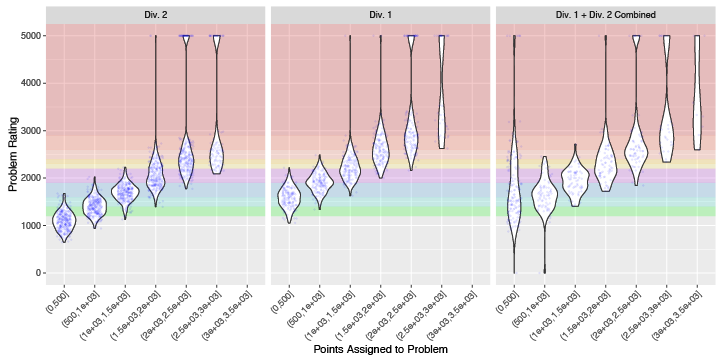
There is a clear linear relationship between the point value of problems and their rating, although there is a fair bit of spread for each point value. A Div. 2 500-point question could be as easy as gray or as hard as blue, and a Div. 1 500-point question ranges from gray all the way to yellow.
How stable are problem ratings and contestant ratings over time?
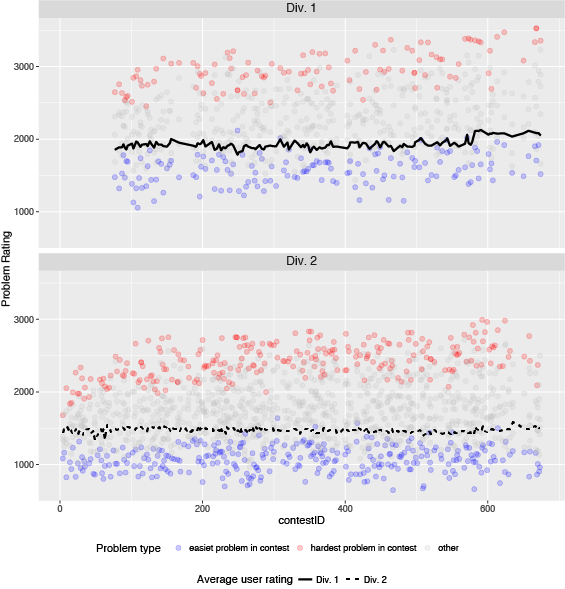
In this plot, each dot indicates one problem. The hardest problem in each contest is colored red, and the easiest problem in each contest is colored blue. Both the hardest and easiest problems in Div. 1 have been creeping upwards over time, while easy problem in Div. 2 have been more stable. The average rating of Div. 1 participants (solid black line) and Div. 2 participants (dashed black line) are rather stable over time, with a jump recently due to the recategorization of Div. 1 and Div. 2.
Which categories of problems are the hardest to solve?
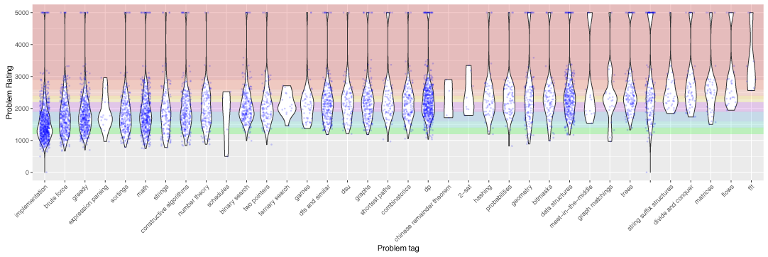
While it is difficult to categorize problems accurately with only a few tags, there are still some interesting patterns in the distribution of problem ratings with respect to problem tags. Categories here are sorted by increasing median problem ratings. There is a significant amount of spread within each tag. Unsurprisingly, problems tagged with “FFT” appear to be the most difficult, but are also infrequently seen. “Flows”, “matrices”, “divide and conquer”, and “string suffix structures” are next, followed by problems without any tags. “Implementation” and "brute force" problems appear to be the easiest, but still quite a few did not get any solves in-contest.
Are problem ratings stable between divisions?
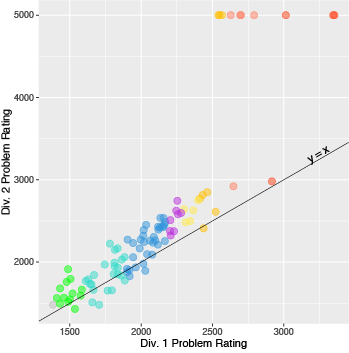
Since a few problems are shared between Div. 1 and Div. 2 contests, we decided to see how well Div. 1 scores correlated with Div. 2 scores for these problems. Here, each dot is a problem shared between two divisions, and they are colored by their Div. 1 ratings. We see a strong linear relationship between the two, and as expected, Div. 1 problem ratings tend to be lower than Div. 2 ratings. This is especially apparently in a few problems that are unsolved by Div. 2 participants but have been solved by Div. 1 participants. This pattern could be attributed to a number of different factors: very difficult questions are sometimes solved by no Div. 2 participants, and they also tend to see these problems later in the contest, leaving them less time to solve them.
What’s next?
Once we have a way of calculating the difficulty of problems, we can visualize a user’s rating trajectory superimposed on top of problems they’ve done either in contest or for practice. Here’s a profile of I_love_Tanya_Romanova, a long-time champion on the problemset leaderboard.
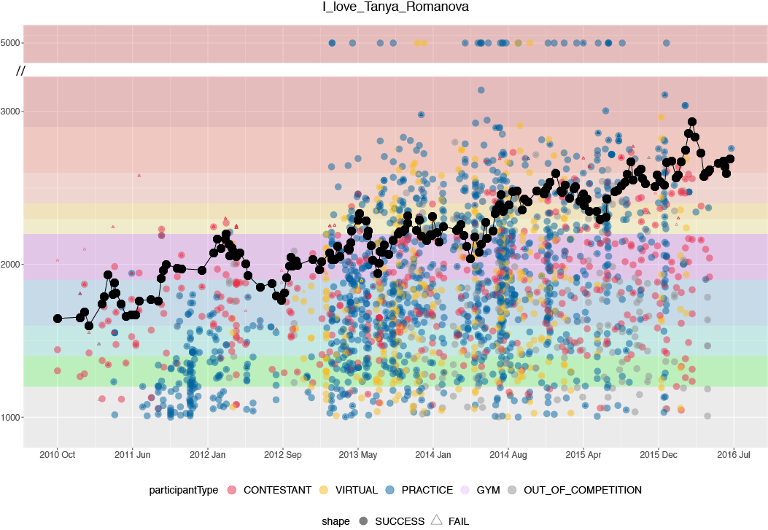
We hope that these visualizations can help us make predictions on how users can best improve their ratings. In particular, we're interested in finding out what the optimal problem difficulty to practice is, and to better understand the relationship between practice and contest performance.

