


Here is git repository to solutions of problems of this contest.
Div.2 A
You should check two cases for YES:
- x mod s = t mod s and t ≤ x
- x mod s = (t + 1) mod s and 2t + 1 ≤ x

Time Complexity: 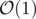
Div.2 B
Nothing special, right? just find the position of letters . and e with string searching methods (like .find) and do the rest.

Time Complexity: 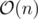
A
Do what problem wants from you. The only thing is to find the path between the two vertices (or LCA) in the tree. You can do this in 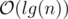 since the height of the tree is . You can keep edge weights in a map and get/set the value whenever you want. Here's a code for LCA:
since the height of the tree is . You can keep edge weights in a map and get/set the value whenever you want. Here's a code for LCA:
LCA(v, u):
while v != u:
if depth[v] < depth[u]:
swap(v, u)
v = v/2 // v/2 is parent of vertex v

Time Complexity: 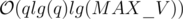
B
First of all starting_time of a vertex is the number of dfs calls before the dfs call of this vertex plus 1. Now suppose we want to find the answer for vertex v. For any vertex u that is not in subtree of v and is not an ancestor v, denote vertices x and y such that:
- x ≠ y
- x is an ancestor of v but not u
- y is an ancestor of u but not v
- x and y share the same direct parent; That is par[x] = par[y].

The probability that y occurs sooner than x in children[par[x]] after shuffling is 0.5. So the probability that starting_time[u] < starting_time[v] is 0.5. Also We know if u is ancestor of v this probability is 1 and if it's in subtree of v the probability is 0. That's why answer for v is equal to 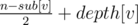 (depth is 1-based and sub[v] is the number of vertices in subtree of v including v itself). Because n - sub[v] is the number of vertices like the first u (not in subtree of v and not an ancestor of v).
(depth is 1-based and sub[v] is the number of vertices in subtree of v including v itself). Because n - sub[v] is the number of vertices like the first u (not in subtree of v and not an ancestor of v).
Thus answer is always either an integer or an integer and a half.
Time complexity:
C
It gets tricky when the problem statement says p and q should be coprimes. A wise coder in this situation thinks of a formula to make sure this happens.
First of all let's solve the problem if we only want to find the fraction  . Suppose dp[i] is answer for swapping the cups i times. It's obvious that dp[1] = 0. For i > 0, obviously the desired cup shouldn't be in the middle in (i - 1) - th swap and with this condition the probability that after i - th swap comes to the middle is 0.5. That's why
. Suppose dp[i] is answer for swapping the cups i times. It's obvious that dp[1] = 0. For i > 0, obviously the desired cup shouldn't be in the middle in (i - 1) - th swap and with this condition the probability that after i - th swap comes to the middle is 0.5. That's why 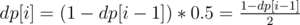 .
.

Some people may use matrix to find p and q using this dp (using pair of ints instead of floating point) but there's a risk that p and q are not coprimes, but fortunately or unfortunately they will be.
Using some algebra you can prove that:
- if n is even then
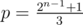 and q = 2n - 1.
and q = 2n - 1. - if n is odd then
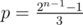 and q = 2n - 1.
and q = 2n - 1.
You can confirm that in both cases p and q are coprimes (since p is odd and q is a power of 2).
The only thing left to handle is to find 2n (or 2n - 1) and parity. Finding parity is super easy. Also 2n = 2a1 × a2 × ... × ak = (...((2a1)a2)...)ak. So it can be calculated using binary exponential. Also dividing can be done using Fermat's little theorem.
Time complexity: O(klg(MAX_A)).
D
Build the prefix automaton of these strings (Aho-Corasick). In this automaton every state denotes a string which is prefix of one of given strings (and when we feed characters to it the current state is always the longest of these prefixes that is a suffix of the current string we have fed to it). Building this DFA can be done in various ways (fast and slow).
Suppose these automaton has N states (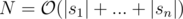 ) and state v has edges outgoing to states in vector neigh[v] (if we define our DFA as a directed graph). Suppose state number 1 is the initial state (denoting an empty string).
) and state v has edges outgoing to states in vector neigh[v] (if we define our DFA as a directed graph). Suppose state number 1 is the initial state (denoting an empty string).
If l was smaller we could use dp: suppose dp[l][v] is the maximum score of all strings with length equal to l ending in state v of our DFA when fed into it.
It's easy to show that dp[0][1] = 0 and dp[1][v] ≤ bv + dp[l + 1][u] for u in neigh[v] and calculating dps can be done using this (here bv is sum of a of all strings that are a suffix of string related to state v).

Now that l is large, let's use matrix exponential to calculate the dp. Now dp is not an array, but a column matrix. Finding a matrix to update the dp is not hard. Also we need to reform + and * operations. In matrix multiplying we should use + instead of * and max instead of + in normal multiplication.
Time complexity: 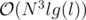 .
.
E
First of all, for each query of 1st type we can assume k = 1 (because we can perform this query k times, it doesn't differ).
Consider this problem: there are only queries of type 1.
For solving this problem we can use heavy-light decomposition. If for a vertex v of the tree we denote av as the weight of the lightest girl in it (∞ in case there is no girl in it), for each chain in HLD we need to perform two type of queries:
- Get weight of the lightest girl in a substring (consecutive subsequence) of this chain (a subchain).
- Delete the lightest girl in vertex u. As the result only au changes. We can find this value after changing in if we have the sorted vector of girls' weights for each vertex (and then we pop the last element from it and then current last element is the lightest girl, ∞ in case it becomes empty).

This can be done using a classic segment tree. In each node we only need a pair of integers: weight of lightest girl in interval of this node and the vertex she lives in (a pair<int, int>).
This works for this version of the problem. But for the original version we need an additional query type:
3. Increase weight of girls in a substring (consecutive subsequence) of this chain (a subchain) by k.
This can be done using the previous segment tree plus lazy propagation (an additional value in each node, type 3 queries to pass to children).
Now consider the original problem. Consider an specific chain: after each query of the first type on of the following happens to this chain:
- Nothing.
- Only an interval (subchain) is effected.
- Whole chain is effected.
When case 2 happens, v (query argument) belongs to this chain. And this can be done using the 3rd query of chains when we are processing a 2nd type query (effect the chain v belongs to).
When case 3 happens, v is an ancestor of the topmost vertex in this chain. So when processing 1st type query, we need to know sum of k for all 2nd type queries that their v is an ancestor of topmost chain in current chain we're checking. This can be done using a single segment/Fenwick tree (using starting-finishing time trick to convert tree to array).
So for each query of 1st type, we will check all chains on the path to find the lightest girl and delete her.
Time Complexity: 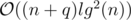
F
In the first thoughts you see that there's definitely a binary search needed (on r). Only problem is checking if there are such two points fulfilling conditions with radius r.
For each edge, we can shift it r units inside the polygon (parallel to this edge). The only points that can see the line coinciding the line on this edge are inside the half-plane on one side of this shifted line (side containing this edge). So problem is to partition these half-planes in two parts such that intersection of half-planes in each partition and the polygon (another n half-planes) is not empty. There are several algorithms for this propose:
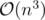 Algorithm:
Algorithm:

It's obvious that if intersection of some half-planes is not empty, then there's at least on point inside this intersection that is intersection of two of these lines (lines denoting these half-planes). The easiest algorithm is to pick any intersection of these 2n lines (n shifted half-planes and n edges of the polygon) like p that lies inside the polygon, delete any half-plane containing this point (intersection of deleted half-planes and polygon is not empty because it contains at least p) and check if the intersection of half-planes left and polygon is not empty (of course this part needs sorting half-planes and adds an additional log but we can sort the lines initially and use something like counting sort in this step).
Well, constant factor in this problem is too big and this algorithm will not fit into time limit. But this algorithm will be used to prove the faster algorithm:
 Algorithm:
Algorithm:
In the previous algorithm we checked if p can be in intersection of one part. Here's the thing:
Lemma 1: If p is inside intersection of two half-planes (p is not necessarily intersection of their lines) related to l - th and r - th edge (l < r) and two conditions below are fulfilled, then there's no partitioning that in it p is inside intersection of a part (and polygon):
- At least one of the half-planes related to an edge with index between l and r exists that doesn't contain p.
- At least one of the half-planes related to an edge with index greater than r or less than l exists that doesn't contain p.
Because if these two lines exist, they should be in the other part that doesn't contain p and if they are, intersection of them and polygon will be empty(proof is easy, homework assignment ;)).

This proves that if such partitioning is available that p is in intersection of one of them, then it belongs to an interval of edges(cyclic interval) and the rest are also an interval (so intersection of both intervals with polygon should be non-empty). Thus, we don't need p anymore. We only need intervals!
Result is, if such partitioning exists, there are integers l and r (1 ≤ l ≤ r ≤ n) such that intersection of half-planes related to l, l + 1, ..., r and polygon and also intersection of half-planes related to r + 1, r + 2, ..., n, 1, 2, ..., l - 1 and polygon are both non-empty.
This still gives an algorithm (checking every interval). But this lemma comes handy here:
We call an interval(cyclic) good if intersection of lines related to them and polygon is non-empty.
Lemma 2: If an interval is good, then every subinterval of this interval is also good.
Proof is obvious.
That gives and idea:
Denote interval(l, r) is a set of integers such that:
- If l ≤ r, then interval(l, r) = {l, l + 1, ..., r}
- If l ≤ r, then interval(l, r) = {r, r + 1, ..., n, 1, ..., l}
(In other words it's a cyclic interval)
Also MOD(x) is:
- x iff x ≤ n
- MOD(x - n) iff x > n
(In other words it's modulo n for 1-based)
The only thing that matters for us for every l, is maximum len such that interval(l, MOD(l + len)) is good (because then all its subintervals are good).
If li is maximum len that interval(i, MOD(i + len)) is good, we can use 2-pointer to find values of l.
Lemma 3: lMOD(i + 1) ≥ li - 1.
Proof is obvious in result of lemma 2.
Here's a pseudo code:
check(r):
len = 0
for i = 1 to n:
while len < n and good(i, MOD(i+len)): // good(l, r) returns true iff interval(l, r) is good
len = len + 1
if len == 0:
return false // Obviously
if len == n:
return true // Barney and Lyanna can both stay in the same position
l[i] = len
for i = 1 to n:
if l[i] + l[MOD(i+l[i])] >= n:
return true
return false
good function can be implemented to work in (with sorting as said before). And 2-pointer makes the calls to good to be .
So the total complexity to check an specific r is .
Time Complexity: 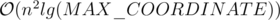
Feel free to comment and ask your questions.



