


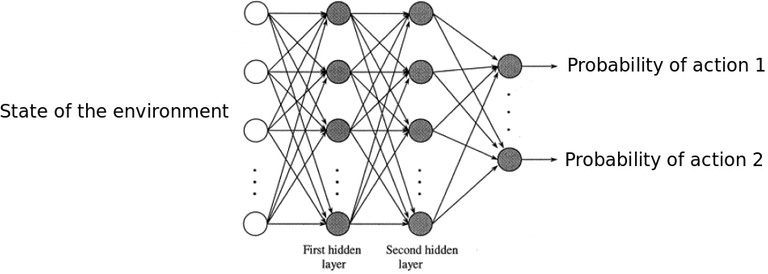
We would like to create a model that which when given a game state, it predicts the best move.
Lets say our game is the simple Tic Tac Toe. It is a small game and we can train the AI for it in a handful of minutes.
Here is our example neural network, reduced the number of hidden layer to avoid cluttering.
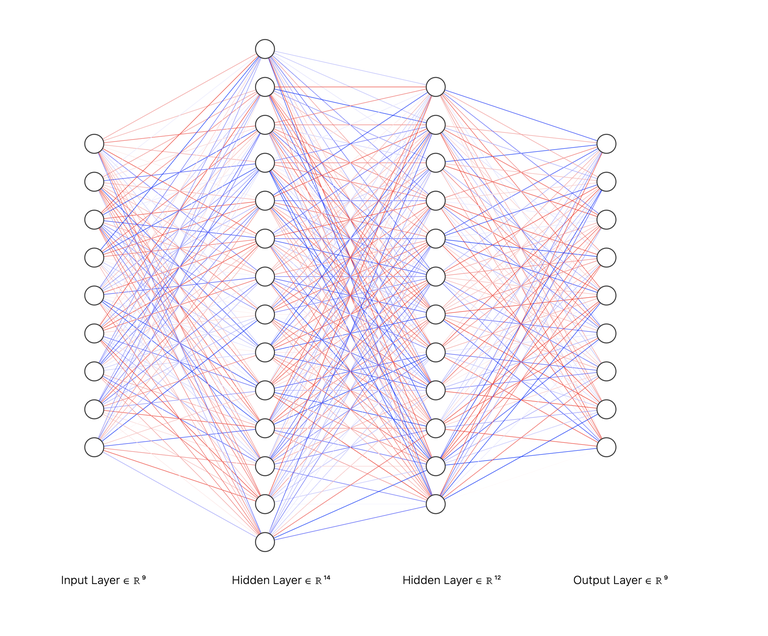
In the above network, the inputs are going to be board states. For example,

Lets assume the neural networks always predicts from the perspective of that the turn is of player -1.
If we can build a neural network, we can just flip the board and predict for the opposite player, easy peasy.
I use the algorithm mentioned at OPEN AI blog for training. Its almost same for the CartPole Reinforcement Learning environment from OpenAI GYM https://spinningup.openai.com/en/latest/algorithms/vpg.html.
Also please read into the blog http://karpathy.github.io/2016/05/31/rl/ from Andrej Karpathy from a beginner perspective.
So the training algorithm looks like this:
- Run a number of simulations / battles / episodes
For every simulation:
--> Run a play till the end of game, i.e. either someone wins, or the game ends in a draw. The learning agent picks a random action based on the probability outputted by neural network for the input game board state. This way the neural network has a stochastic behavior and it helps in both exploration vs exploitation of existing good moves. The higher the probability of a action, it means the action has been voted up many times, the lower means its not favored much but still the learning process can / needs to explore the action unless the probability is 0 thus adding some potential for the already existing network to not get stuck in some kind of minima where a little bit of exploration would have brought excellent returns.
--> Calculate the reward for the player.
--> Feed it into the Neural Network model for training.
If we run this enough times, the Network gets better at avoiding the bad moves and maximizing the probability of good moves. And voila, we have it right here, create a model that is better than the opponent.
Once we do it enough times, the model gets better and better. Although, it doesn't beat the MiniMax perfect playing opponent but at least I got something working using a radical new way that utilizes the latest Neural Network strategies. The algorithm I used is a rudimentary algorithm. Advanced form of algorithm has been used by OpenAI to achieve super human performance in Atari games and Dota 2 with nothing but self play.
Finally here is my code, https://github.com/kingofdelphi/tic_tac_toe_agi. Of course I am still improving the AI and my code as I learn since it hasn't been much since I started learning these stuffs.
I am going to try more advanced algorithms and see how the model improves. Right now, it loses against minmax 5% of the times, I want to get it down to zero.
It may be possible someone of you has already cracked the game using self play while utilizing neural networks. If so, I am very much interested to learn more about your approaches / code. Once again heres my code, https://github.com/kingofdelphi/tic_tac_toe_agi. I am gonna keep tweaking it to my hearts content.
Thank you for reading!


