


| Codeforces Round 315 (Div. 1) |
|---|
| Закончено |
Жить в Байтландии было и так неплохо, но добрый король решил порадовать своих подданных и ввести национальный язык. Собрал он лучших мудрецов и отправил в экспедицию по дальним странам, чтобы они узнали всё про то, как должен быть устроен язык.
Долго ли, коротко ли, вернулись мудрецы из путешествия еще более мудрецами. Заперлись на полгода в столовой, после чего сказали королю: "много есть разных языков, но почти во всех есть буквы, которые делятся на гласные и согласные; внутри слова гласные и согласные необходимо сочетать правильно".
Правил очень много, во всех есть исключения, но наш язык будет лишен таких недочётов! Мы предлагаем ввести формальные правила сочетания гласных и согласных, и включить в язык все слова, которые им удовлетворяют.
Правила составления слов:
- Буквы делятся на гласные и согласные некоторым определённым образом;
- Все слова имеют длину ровно n;
- Есть m правил вида (pos1, t1, pos2, t2). Каждое правило гласит: если на позиции pos1 буква типа t1, то на позиции pos2 буква типа t2.
Вам дана некоторая строка s длины n, не обязательно являющаяся корректным словом нового языка. Среди всех слов языка, не меньших лексикографически, чем строка s, найдите лексикографически минимальное.
В первой строке находится одна строка, состоящая из букв 'V' (Vowel) и 'C' (Consonant), определяющая, какие буквы являются гласными, а какие — согласными. Длина этой строки l — это размер алфавита нового языка (1 ≤ l ≤ 26), при этом в качестве букв алфавита используются первые l букв английского алфавита. Если i-й символ строки равен 'V', то данная буква является гласной, иначе — согласной.
Во второй строке находятся два целых числа n, m (1 ≤ n ≤ 200, 0 ≤ m ≤ 4n(n - 1)) — количество букв в одном слове и количество правил соответственно.
Затем в m строках описаны m правил языка в следующем формате: pos1, t1, pos2, t2 (1 ≤ pos1, pos2 ≤ n, pos1 ≠ pos2, 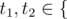 'V', 'C' }).
'V', 'C' }).
В последней строке находится строка s длины n, состоящая из первых l маленьких букв латинского алфавита.
Гарантируется, что никакие два правила не совпадают.
Выведите лексикографически минимальное слово языка, которое лексикографически не меньше s. Если таких слов нет (например, если в языке вообще нет слов), выведите "-1" (без кавычек).
VC
2 1
1 V 2 C
aa
ab
VC
2 1
1 C 2 V
bb
-1
VCC
4 3
1 C 2 V
2 C 3 V
3 V 4 V
abac
acaa
В первом тесте слово "aa" не является словом языка, но слово "ab" является.
Во втором тесте из всех четырех возможных только слово "bb" не является словом языка, однако все остальные слова лексиграфически меньше, поэтому ответа нет.
В третьем тесте из-за последнего правила "abac" не принадлежит языку ("a" — гласная, "c" — согласная). Единственное слово с префиксом "ab" соответствующее заданным правилам — это "abaa". Но оно меньше "abac", поэтому ответом будет "acaa"
