


| Codeforces Round 315 (Div. 1) |
|---|
| Finished |
Living in Byteland was good enough to begin with, but the good king decided to please his subjects and to introduce a national language. He gathered the best of wise men, and sent an expedition to faraway countries, so that they would find out all about how a language should be designed.
After some time, the wise men returned from the trip even wiser. They locked up for six months in the dining room, after which they said to the king: "there are a lot of different languages, but almost all of them have letters that are divided into vowels and consonants; in a word, vowels and consonants must be combined correctly."
There are very many rules, all of them have exceptions, but our language will be deprived of such defects! We propose to introduce a set of formal rules of combining vowels and consonants, and include in the language all the words that satisfy them.
The rules of composing words are:
- The letters are divided into vowels and consonants in some certain way;
- All words have a length of exactly n;
- There are m rules of the form (pos1, t1, pos2, t2). Each rule is: if the position pos1 has a letter of type t1, then the position pos2 has a letter of type t2.
You are given some string s of length n, it is not necessarily a correct word of the new language. Among all the words of the language that lexicographically not smaller than the string s, find the minimal one in lexicographic order.
The first line contains a single line consisting of letters 'V' (Vowel) and 'C' (Consonant), determining which letters are vowels and which letters are consonants. The length of this string l is the size of the alphabet of the new language (1 ≤ l ≤ 26). The first l letters of the English alphabet are used as the letters of the alphabet of the new language. If the i-th character of the string equals to 'V', then the corresponding letter is a vowel, otherwise it is a consonant.
The second line contains two integers n, m (1 ≤ n ≤ 200, 0 ≤ m ≤ 4n(n - 1)) — the number of letters in a single word and the number of rules, correspondingly.
Next m lines describe m rules of the language in the following format: pos1, t1, pos2, t2 (1 ≤ pos1, pos2 ≤ n, pos1 ≠ pos2, 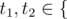 'V', 'C' }).
'V', 'C' }).
The last line contains string s of length n, consisting of the first l small letters of the English alphabet.
It is guaranteed that no two rules are the same.
Print a smallest word of a language that is lexicographically not smaller than s. If such words does not exist (for example, if the language has no words at all), print "-1" (without the quotes).
VC
2 1
1 V 2 C
aa
ab
VC
2 1
1 C 2 V
bb
-1
VCC
4 3
1 C 2 V
2 C 3 V
3 V 4 V
abac
acaa
In the first test word "aa" is not a word of the language, but word "ab" is.
In the second test out of all four possibilities only word "bb" is not a word of a language, but all other words are lexicographically less, so there is no answer.
In the third test, due to the last rule, "abac" doesn't belong to the language ("a" is a vowel, "c" is a consonant). The only word with prefix "ab" that meets the given rules is "abaa". But it is less than "abac", so the answer will be "acaa"
