


Hello, I've made a video-editorial for the problem Div.2 E (Div.1 C) from the latest contest.
https://www.youtube.com/watch?v=lST0djhfxfk
Thanks the authors for a cool contest!
| # | User | Rating |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 4 | atcoder_official | 161 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
Hello, I've made a video-editorial for the problem Div.2 E (Div.1 C) from the latest contest.
https://www.youtube.com/watch?v=lST0djhfxfk
Thanks the authors for a cool contest!
Hello, I've made a video-editorial for the problem Div.2 D (Div.1 B) from the yesterday's contest.
https://www.youtube.com/watch?v=0pQjbLOQL-c
Thanks Arti1990 for this controversial problem!
Hello, here's a video-editorial for problems F and G from the latest "CodeTON" contest with a little motivational speech in the beginning.
https://www.youtube.com/watch?v=fJ_0M2DDEvw
Thanks RDDCCD and the TON Foundation for a cool contest!
Hello, I've made a video-editorial for problems Div.2 B–E (Div.1 A–C) from today's contest.
https://www.youtube.com/watch?v=VwY7QzStMk4
Thanks the authors for a cool contest!
Hello, I've made a full video editorial for the latest CF div. 2 round / first three problems from div. 1.
https://www.youtube.com/watch?v=-ksLcl2tQCg
Thanks to all the authors for a cool contest!
Hello, I've made a video-editorial for problems Div.2 C–E (Div.1 A–C) from today's contest.
https://www.youtube.com/watch?v=VdRo42OEJIY
Thanks the authors for a cool contest!
Hello, I've made a video-editorial for problems Div.2 C–E (Div.1 A–C) from yesterday's contest.
https://www.youtube.com/watch?v=k6dxqX3JIhM
Thanks the authors for a cool contest!
Hello, I've made a video-editorial for problems Div.2 B–E (Div.1 A–C) from today's contest.
https://www.youtube.com/watch?v=Gu3GbiMUSAw
Thanks the authors for a cool contest!
Hello, I've made a video-editorial for problems D–E from yesterday's contest.
https://www.youtube.com/watch?v=mGgV3eHhVoI
Thanks the authors for a cool contest!
Hello, here's a video-editorial for problems B–E from today's contest.
https://www.youtube.com/watch?v=c9A-fO6fPXQ
Thanks RDDCCD and the TON Foundation for a cool contest!
Hello, I've made a full video editorial for the latest CF round. I'm a bit late, but I can compensate that by having a super-solution for problem E, which is faster than the authors' and also easier in my opinion.
https://www.youtube.com/watch?v=i1i_7lqnGwA
Thanks to all the authors for a cool contest!
Hello, I've made a video-editorial for problem F from yesterday's contest, but if the constraints were much higher. As I use Diophantine equations there, I've decided to make a separate short video about them. So here they are both:
https://www.youtube.com/watch?v=Yn5GAoGHTsM
https://www.youtube.com/watch?v=IDmDg6PoVug
Thanks the developers for a cool contest!
Hello, here's a video-editorial for problems B–E from yesterday's contest.
https://www.youtube.com/watch?v=ch-yS2jqmKQ
Thanks Nebius for a cool contest!
I have found these articles, where it's already described:
https://codeforces.me/blog/entry/72527
https://codeforces.me/blog/entry/46620
They are both very good, but I want to write a more concise blog about the modular inverse specifically, as it is needed in many problems that don't even belong to number theory.
There are two integer numbers A and B. Suppose you know that A is divisible by B. But they are very big, so you only know their remainders modulo some prime number M: A % M and B % M. You want to know the remainder of their quotient – (A / B) % M. But (A % M) may be not divisible by (B % M). What to do?
Such question is very common in combinatorical problems, for example when counting binomial coefficients, where you need to divide n! by k! and (n - k)!.
The short answer is you need to calculate B to the power of M - 2 modulo M (using binary exponentiation). The resulting number is called the modular inverse of B. Now you can multiply A by it to effectively divide it by B.
Note: this only works if B % M is not 0 and M is prime.
This is a well-known formula that relies on Fermat's little theorem and the fact that every non-zero element of the ring of remainders modulo prime number has exactly one multiplicative inverse. If you want to know more, you can read the aforementioned articles.
Hello, I've recorded another detailed video-editorial for problems div.2 C–F / div.1 A–D from yesterday's contest.
https://www.youtube.com/watch?v=ch-yS2jqmKQ
Thanks for all the authors for this cool contest!
Hello, I've recorded a detailed video-editorial for problems C, D and E from today's div.2 contest.
https://www.youtube.com/watch?v=jFSUQmxCoUI
Thanks MateoCV for a cool contest!
Hello, I've recorded a video-editorial for problem F from the latest div.1 contest, where I apply the method which I call "narrow down the choice".
https://www.youtube.com/watch?v=lOkpzBAbFIE
If you want, I'll make a blog entry where I tell in details about this method.
Suppose you want to know this sum for some n and k:
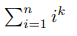
Here are the well known formulas for the first several k:
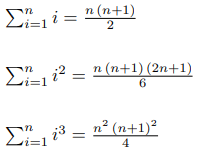
But suppose you forgot them. What to do? Luckily, there is an easy algorithm to generate those formulas.
First of all, let's prove a theorem.
Suppose for every integer non-negative n:
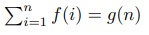
where f and g are polynoms. Then for some constant c:
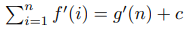
For every positive integer n:
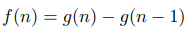
These two polynoms are equal in an infinite number of points, which means that they are identical. Which allows us to say:
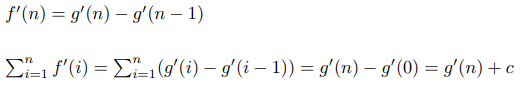
Let's say we want to find the formula for the sum of squares. Then using our theorem we can create such an algorithm:
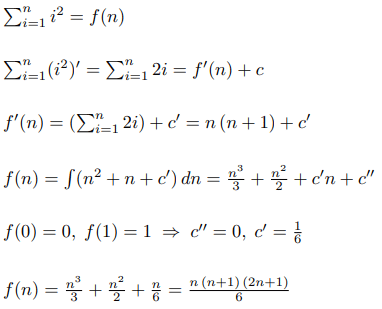
Now let's run the same algorithm to find the formula for the sum of cubes:
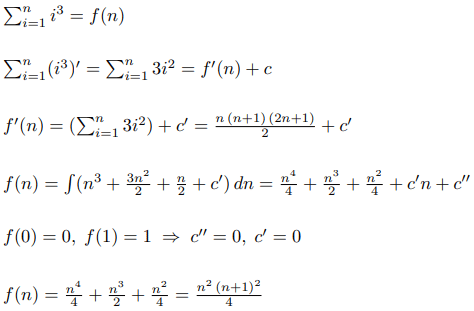
Hello, I've recorded a video-editorial for D1 and D2 from today's contest, where I apply my method of "Process-DP".
https://www.youtube.com/watch?v=oOyPQL16x1M
You can read about this method in details here:
No, I don't mean Convex Hull Trick and Knuth optimization. I mean simpler and more common methods.
This is a continuation of my series of posts on DP, to understand the terminology read the prologue.
Very often after building the DP graph one can discover that the transitions into a state go not from a random set of vertices, but from some segment of values for one of the parameters. For example, from states dp[i][j] with some constant i and j lying in a segment [a, b].
In such cases one may not implement each transition separately, but to implement them all at once. If by implementing a transition we mean adding from dp[A] to dp[B], then we can use prefix sums. In case if we need to find the best transition into dp[B], then we can use Segment Tree.
AtCoder DP Contest: Problem M Find the number of integer sequences of length n where i-th number is from 0 to a[i] and the sum of numbers is equal to k.
Let's solve it with the Process Simulation approach. Consider a process of writing this sequence number by number. The parameters of the process will be:
How many number are already written.
The sum of the written numbers.
The value of dp[i][j] will be the number of paths of the process leading into this state.
The amount of transitions of a single state is O(k), the overall amount of transitions is O(n k^2), too much.
Let's consider where the states intodp[i][j] are leading from. Obviously, from dp[i - 1][l] where l belongs to the segment [max(0, j - a[i - 1]), j].
Thus, before counting the layer i, we can count prefix sums on the layer i - 1 in order to count dp[i][j] in O(1).
Let's return to a problem from a previous part of my blog.
543A - Writing Code There are n programmers that need to write m lines of code and make no more than b mistakes. i-th programmer makes a[i] mistakes per line. How many ways are there to do it? (Two ways are different if the number of lines that some programmer writes differs).
Let's remember our very first solution: define a process where at each step we assign another programmer the number of lines written by him. The parameters will be:
The amount of programmers passed by.
The total amount of written lines.
The total amount of made mistakes.
The value of dp[i][j][k] will be the number of paths of the process leading into this state.
Then there will be O(n m b) states overall and there are O(m) transitions from a single state, so there are O(n m^2 b) transitions overall, which is too much.
But let's consider from which states there is a transition into the state dp[i][j][k]. If the last step was "i - 1-th programmer has written x lines of code" then the transition was from a state dp[i - 1][j - x][k - x * a[i - 1]] (where x >= 0).
So the states from which there is a transitions are located on a line in the table of the i - 1-th layer, and generally such sum can be calculated in O(1) time from an analogous sum for the state dp[i][j - 1][k - a[i - 1]].
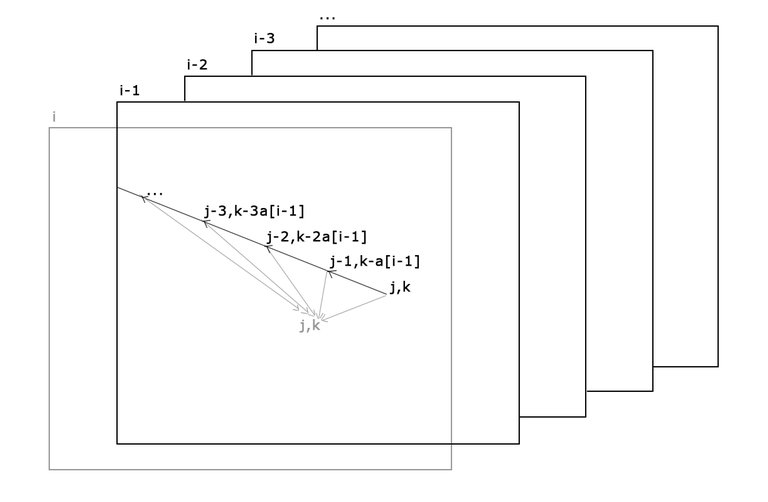
After some simplifications, the code will look as follows:
It's the oldest trick in the book. If one of the parameters is too large and the value is on the contrary limited, one can try swapping their roles.
AtCoder DP Contest: Problem E There are n objects, i-th one has a weight of w[i] and a value of v[i]. What is the maximal sum of values among all sets of objects, where the sum of weights is no more than m? In this version of the problem n <= 100, m <= 10^9, v[i] <= 10^3.
Let's take the solution from a previous part of the blog: consider a process where on each step a new object is considered and is either picked or skipped, the parameters of the process will be:
The number of considered objects.
The total weight of the picked objects.
The value of DP will be the largest sum of values of the picked objects for the given state of the process.
With the given constraints the maximal value of the second parameter will be 10^9 and the maximal value of DP will be 10^5, so it makes sense to swap their roles. The process will be the same, but the parameters will be:
The number of considered objects.
The total value of the picked objects.
The value of DP will be the smallest sum of all weights of the picked objects for the given state of the process.
In the end we will find the largest sum of objects' values among those for which the minimal total weight is no more than W.
Sometimes we can notice about two parameters that we don't have to know the value of each separately, instead it's enough to track the value of some combination of them. For example, in case if at the end we do some check on whether the sum of two parameters exceeds some value then it is possible that we can change these two parameters with a one equal to their sum.
19B - Checkout Assistant There are n products, each has a price of c[i] and the time of processing t[i]. Find a set of products with the smallest total price such that their total time of processing is no less than the number of the remaining products.
Consider a process where on each step a new product is considered and is either picked or skipped. The parameters will be:
The number of considered products.
Total processing time of the picked products.
The number of skipped products.
The value of DP will be the minimal total price of the picked products for a given state of the process.
At the end we are interested in the states dp[n][j][k] where j >= k. As k <= n, after the parameter j has reached n there is no need to increase it any further, so we will write down all the states of the process with the larger values of the parameter j as if j = n.
Thus, the number of states is equal to O(n^3), as is the number of transitions, which does not satisfy the time limit.
Let's have a closer look on where the transitions from the state dp[i][j][k] are leading to: in case if we pick the product – into dp[i + 1][j + t[i]][k], and in case if we skip – into dp[i + 1][j][k + 1].
Notice that in the first case the difference of the second and the third parameters simply increases by t[i], in the second case – decreases by 1, and in the end we need to cut the states in which this difference is non-negative, therefore instead of these two parameters separately, we can instead track their difference.
For convinience instead of j - k we will track j + i - k (so the parameter is never negative, as k <= i), then in case of picking the product the parameter is increased by t[i] + 1, and in case of skipping it doesn't change.
At the end we cut the states where this parameter is no less than n, at the same time it doesn't decrease after any transition, so analogically to the previous solution, we can write down the states with j + i - k > n into dp[i][n].
Thus, the amounts of states and transitions both equal O(n^2).
If you want to know more, I remind that I do private lessons on competitive programming, the price is $30/h. Contact me on Telegram, Discord: rembocoder#3782, or in CF private messages.
It seems, there are so many materials on binary search already that everyone must know how to code it, however every material seems to tell its own approach, and I see people being lost and still making bugs on such a simple thing. That's why I want to tell you about an approach which I find the most elegant. Of all the variety of articles, I saw my approach only in this comment (but less generalized).
Suppose you want to find the last element less than x in a sorted array and just store a segment of candidates for the answer [l, r]. If you write:
int l = 0, r = n - 1; // the segment of candidates
while (l < r) { // there are more than 1 candidate
int mid = (l + r) / 2;
if (a[mid] < x) {
l = mid;
} else {
r = mid - 1;
}
}
cout << l;
...you will run into a problem: suppose l = 3, r = 4, then mid = 3. If a[mid] < x, you will end up in a loop (the next iteration will be again on [3, 4]).
Okay, it can be fixed with rounding mid up – mid = (l + r + 1) / 2. But we have another problem: what if there are no such elements in the array? We would need an extra check for that case. As a result, we have a pretty ugly code that is not generalized very well.
Let's generalize the problem we want to solve. We have a statement about an integer number n that is true for integers smaller than some bound, but then always stays false once n exceeded that bound. We want to find the last n for which the statement is true.
First of all, we will use half-intervals instead of segments (one border is inclusive, another is non-inclusive). Half-intrevals are in general very useful, elegant and conventional in programming, I recommend using them as much as possible. In that case we will choose some small l for which we know in before the statement is true and some big r for which we know it's false. Then the range of candidates is [l, r).
My code for that problem would be:
int l = -1, r = n; // a half-interval [l, r) of candidates
while (r - l > 1) { // there are more than 1 candidate
int mid = (l + r) / 2;
if (a[mid] < x) {
l = mid; // now it's the largest for which we know it's true
} else {
r = mid; // now it's the smallest for which we know it's false
}
}
cout << l; // in the end we are left with a range [l, l + 1)
The binary search will only do checks for some numbers strictly between initial l and r. It means that it will never check the statement for l and r, it will trust you that for l it's true, and for r it's false. Here we consider -1 as a valid answer, which will correspond to no numbers in array being less than x.
Notice how there are no "+ 1" or "- 1" in my code and no extra checks are needed, and no loops are possible (since mid is strictly between the current l and r).
The only variation that you need to keep in mind is that half of the times you need to find not the last, but the first number for which something is true. In that case the statement must be always false for smaller numbers and always true starting from some number.
We will do pretty much the same thing, but now r will be an inclusive border, while l will be non-inclusive. In other words, l is now some number for which we know the statement to be false, and r is some for which we know it's true. Suppose I want to find the first number n for which n * (n + 1) >= x (x is positive):
int l = 0, r = x; // a half-interval (l, r] of candidates
while (r - l > 1) { // there are more than 1 candidate
int mid = (l + r) / 2;
if (mid * (mid + 1) >= x) {
r = mid; // now it's the smallest for which we know it's true
} else {
l = mid; // now it's the largest for which we know it's false
}
}
cout << r; // in the end we are left with a range (r - 1, r]
Just be careful to not choose a r too large, as it can lead to overflow.
1201C - Maximum Median You are given an array a of an odd length n and in one operation you can increase any element by 1. What is the maximal possible median of the array that can be achieved in k steps?
Consider a statement about the number x: we can make the median to be no less than x in no more than k steps. Of course it is always true until some number, and then always false, so we can use binary search. As we need the last number for which this is true, we will use a normal half-interval [l, r).
To check for a given x, we can use a property of the median. A median is no less than x iff at least half of the elements are no less than x. Of course the optimal way to make half of the elements no less than x is to take the largest elements.
Of course we can reach the median no less than 1 under given constraints, so l will be equal to 1. But even if there is one element and it's equal to 1e9, and k is also 1e9, we still can't reach median 2e9 + 1, so r will be equal to 2e9 + 1. Implementation:
#define int int64_t
int n, k;
cin >> n >> k;
vector<int> a(n);
for (int i = 0; i < n; i++) {
cin >> a[i];
}
sort(a.begin(), a.end());
int l = 1, r = 2e9 + 1; // a half-interval [l, r) of candidates
while (r - l > 1) {
int mid = (l + r) / 2;
int cnt = 0; // the number of steps needed
for (int i = n / 2; i < n; i++) { // go over the largest half
if (a[i] < mid) {
cnt += mid - a[i];
}
}
if (cnt <= k) {
l = mid;
} else {
r = mid;
}
}
cout << l << endl;
Hope I've made it clearer and some of you will switch to this implementation. To clarify, occasionally other implementations can be more fitting, for example with interactive problems – whenever we need to think in terms of an interval of searching, and not in terms of the first/last number for which something is true.
I remind that I do private lessons on competitive programming, the price is $30/h. Contact me on Telegram, Discord: rembocoder#3782, or in CF private messages.
Hello. This is a prologue to my previous posts, in which I'm going to briefly introduce a reader into the terminology of dynamic programming. This is not an exhaustive guide, but merely a preamble, so that an unprepared reader can get a full picture the same way I see it.
Dynamic programming – the way to solve a problem by parametrizing it in such a way that an answer for some values of the parameters would help us find the answer for the other values of the parameters; and then finding the answer for all possible parameters' values.
DP state – a specific set of values for each parameter (a specific subtask).
DP value – the answer for a specific state (subtask).
Transition from state A to state B – a mark meaning that in order to know the value for the state B, we need to know the answer for the state A.
Implementing a transition from A to B – some action done when the answer for the state A is already known, satisfying the condition: if you implement every transition into the state B then we will know the answer for the state B. The very action can vary from problem to problem.
Basic DP state – a state, which has no transitions into it. The answer for such a state is found directly.
DP graph – a graph where every vertex corresponds to a state and every edge corresponds to a transition.
To solve a problem we need to make a DP graph – to determine which transitions there are and how to implement them. Of course, DP graph must not content any cycles. Then we have to find the answer for every basic state and start implementing the transitions.
We can implement the transitions in any order as long as this rule holds true: do not implement a transition from state A before a transition into state A. But most often people use two ways to do it: transitions back and transitions forward.
Transitions back implementation – go through all the vertices in the order of topological sorting and for each fixed vertex implement the transitions into it. In other words, on every step we take an un-computed state and compute the answer for it.
Transitions forward implementation – go through all the vertices in the order of topological sorting and for each fixed vertex implement the transitions from it. In other words, on every step we take a computed state and implement the transitions from it.
In different cases different ways to implement transitions are more suitable, including some "custom" ways.
Unlike previous posts I will not dive into details of how to come up with a solution, but will only demonstrate the introduced terms in action.
AtCoder DP Contest: Задача K Two players take turns to pull stones from a pile, on a single turn one can pull a[0], ..., a[n - 2] or a[n - 1] stones. Initially there are k stones in the pile. Who wins given that they play optimally?
The parameter of the DP will be i – how many stones are initially in the pile.
The value of the DP will be 1 if the first player wins for such a subtask and 0 otherwise. The answers will be stored in the arraydp[i]. The state i = x itself is often denoted as dp[x] for short, I will also use this notation. Let's call a position "winning" if the one who makes the first turn in it wins. A position is a winning one iff there is a move into a losing one, i.e. dp[i] = 1 if dp[i - a[j]] = 0 for somej (0 <= j < n, a[j] <= i), otherwise dp[i] = 0.
Thus, there will be transitions from dp[i - a[j]] into dp[i] for every i and j (a[j] <= i <= k, 0 <= j < n).
The implementation of a transition from A to B in that case is: if dp[A] = 0 set dp[B] = 1. By default every state is considered to be a losing state (dp[i] = 0).
The basic state in that case is dp[0] = 0.
The DP graph in case of k = 5, a = {2, 3}:
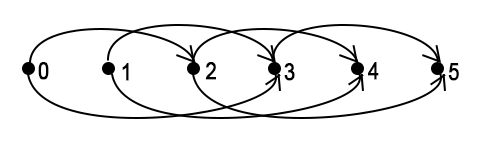
In this code I use the transitions back implementation.
Without any optimizations the time complexity is equal to the number of transitions, in that case it's O(nk).
AtCoder DP Contest: Задача I There are n coins, i-th coin comes up heads with the probability of p[i]. Find the probability that there will be more heads than tails if you toss every coin one time.
The parameters of the DP will be i – how many of the first coins we consider and j – how many shall come up heads.
The value of the DP will be the probability that exactly j would come up heads if you toss the first i coins, it will be stored in the array dp[i][j]. If i > 0 there are two ways to get j coins come up heads: either among the first i - 1 coins j - 1 come up heads and then the next also comes up heads: this is possible if j > 0, the probability of such event isdp[i - 1][j - 1] * p[i - 1]; or among the first i - 1 coins j come up heads and the next does not come up heads: this is possible if j < i, the probability of such event is dp[i - 1][j] * (1 - p[i - 1]). dp[i][j] will be the sum of these two probabilities.
Thus, there will be transitions from dp[i][j] to dp[i + 1][j + 1] and to dp[i + 1][j] for all i and j (0 <= i < n, 0 <= j <= i).
The implementation of a transition from A to B in this case is: add the answer for the state A times the probability of this transition to the answer for the state B. By default every probability to end up in a state is considered to be 0 (dp[i][j] = 0).
This solution uses the Process Simulation approach, read my post to understand it better.
The basic state in this case is dp[0][0] = 1.
The DP graph in case of n = 3:
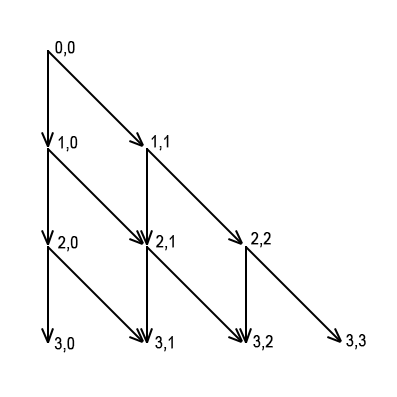
In this code I use the transitions forward implementation.
The number of transitions (and so is the time complexity) in that case is O(n^2).
After reading this article I recommend reading my two previous posts. In there I tell about the two types of dynamic programming and for me this classification seems crucial for further understanding.
Two Kinds of Dynamic Programming: Process Simulation
How to solve DP problems: Regular Approach
If you want to know more, I remind that I do private lessons on competitive programming, the price is $25/h. Contact me on Telegram, Discord: rembocoder#3782, or in CF private messages.
Hello! In the previous post I've introduced two kinds of dynamic programming: Regular and Process Simulation. In it I've told how to solve DP problems using Process Simulation, please read it if you missed in order to understand the difference. Now I want to talk about tricks that help me solve DP problems with Regular approach.
While with the Process Simulation approach we had to invent some process that would build us the desired objects, in the Regular approach we're going to deal with the objects directly. Each state of the DP (i.e., a set of values for each parameter) will correspond to some class of the desired objects, and the corresponding value in the DP table will contain some information about that class, which is in fact equivalent to the Subtask formulation I've introduced in the previous post.
In this post I'll focus on how to come up with transitions for the Regular DP, if you are already decided on the parameters. The general plan is:
Determine, what is a considered object in the problem. Preferably display it visually.
Break the considered objects into classes and try to cover each class with a set of transitions to the lesser subtasks of the problem.
First cover what can be covered in an obvious way, and then focus specifically on what remains.
informatics.msk.ru: ? and * Template You have two strings called "templates" consisting of Latin letters and signs '*' and '?'. You consider a string to fit the template if it can be obtained from the template by changing every '?' to some letter and every '*' to some string of letters (possibly empty). Find the length of the shortest string that fits both templates.
Again, if you really want, it is possible to solve this problem using Process Simulation, but I think this solution will be quite unnatural. So let's proceed with the Subtask approach, or more precisely the Objects Classification approach.
Let's introduce some parameters to this question. A common way to do it in such problems would be to ask the same question about some two prefixes of the templates. That is, "what is the length of the shortest string that fits both of the templates, but if we only consider the first i symbols of the first and the first j symbols of the second template?". Every state of our DP will correspond to such class of strings and the corresponding value in the DP table will store the length of the shortest of such strings.
Now suppose we find the answer for each such question in such order that when we are handling the state dp[i][j], we already know the answer for all smaller pairs of prefixes (we know all the dp[i'][j'], where i' <= i and j' <= j except for the dp[i][j] itself). How can this knowledge help us find the value for the current state? The answer is, we need to look at the current group of objects and to further split it into types. Let's consider three cases:
If none of the prefixes' last symbols is a '*'. Then, obviously, the last symbol of the answer string shall correspond to both of those symbols. Which means, if they are two different letters then the set of answers is empty (in which case we store inf as the shortest answer's length). Otherwise, without its last symbol, the answer string shall fit for the prefix of length i - 1 of the first template and the prefix of length j - 1 of the second template. Which means there is a one-to-one correspondence between the set of answers for the state dp[i][j] and the set of answers for the state dp[i - 1][j - 1]. And the shortest answer for dp[i][j] is larger than the answer for dp[i - 1][j - 1] by one, i.e. dp[i][j] = dp[i - 1][j - 1] + 1.
If both of the prefixes' last symbols are '*'. Then we can see that among all the answers the shortest one will be such that at least one of the two '*' corresponds to an empty string within it (because otherwise we can throw away some of the last letters of the answer and make it shorter, while still valid). Thus, we can split the answers/objects, corresponding to the state dp[i][j] in three groups: the ones where the '*' of the first template's prefix is changed to an empty string, the ones where the '*' of the second template's prefix is changed to an empty string, and the ones that are surely not the shortest. We know the shortest answer in the first group (dp[i - 1][j]), we know the shortest answer in the second group (dp[i][j - 1]) and we don't care about the third group. Thus, in this case dp[i][j] = min(dp[i - 1][j], dp[i][j - 1]).
Note: attentive readers may have noticed that what we consider an object in this problem is actually not just a string corresponding to two templates, but a combination of such a string and such correspondence (i.e., to which characters exactly are the '*' changed to form that string).
If only one of the prefixes' last symbols is a '*'. This is the most interesting case, where it is not obvious how can we know the answer given the answer for smaller subtasks. In such cases I recommend to forget about the rest and just ask yourself anew, what are the objects that we are looking for? Let's say that the first template's prefix is s[0]s[1]...s[i - 1], s[i - 1] = '*' and the second template's prefix ist[0]t[1]...t[j - 1], t[j - 1] != '*'. In this case we specifically want to find a string a[0]a[1]...a[n - 1] such that a[n - 1] is equal to t[j - 1] (or to any letter if t[j - 1] = '?') and a[0]a[1]...a[n - 2] fits the second template's prefix of length j - 1, and on the other hand with some prefix – possibly the whole string – fitting to the first template's prefix of length i - 1.
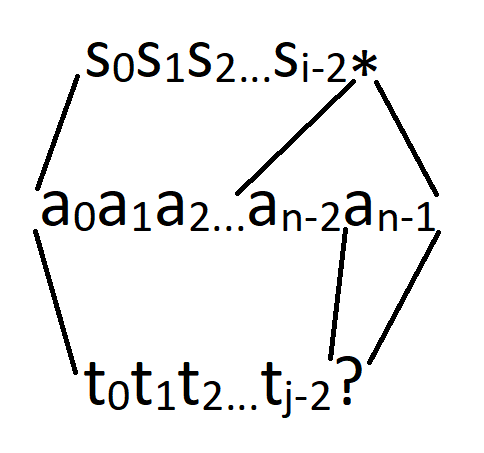
The first part of the statement is good: "a[0]a[1]...a[n - 1] fits the second template's prefix of length j - 1" means that we can address to some state dp[...][j - 1], but what to do with the second part? We can first try to take care of the obvious cases: when the '*' in the first template corresponds to an empty string within the answer – in this case the length of the shortest such answer is just dp[i - 1][j].
And what remains to handle is only the case where '*' corresponds to at least one character, i.e. a[n - 1]. But in this case a[0]a[1]...a[n - 2] fits not only the second template's prefix of length j - 1, but also the first template's prefix of length i, moreover, there is a one-to-one correspondence between the objects that we are left to handle and the objects corresponding to the state dp[i][j - 1], each of the needed strings can be obtained by taking some of the strings corresponding to dp[i][j - 1] and adding the letter t[j - 1] (or, let's say, letter 'a' if t[j - 1] is a '?'). This means that the final formula for this case is dp[i][j] = min(dp[i - 1][j], dp[i][j - 1] + 1).
The base states of the DP are those when i = 0 or j = 0, in this case dp[i][j] equals either 0 if every symbol in the prefixes is a '*' or inf otherwise. The time complexity is obviously O(|s| * |t|).
607B - Zuma There is a sequence of numbers, you can delete a consecutive segment of this sequence if it is a palindrome. Find the minimum amount of such steps to delete the whole sequence.
Given the constraints, we can assume that the parameters are l and r, where dp[l][r] is the answer for this problem if we only had the half-interval of the sequence from l inclusively to r non-inclusively. Now we need to think, how can we find this value knowing all the values for the interior intervals. First of all, we need to determine what an object is in this case. Of course, by object we mean a set of actions that lead to removal of the whole string. Sometimes it's helpful to draw the object visually.
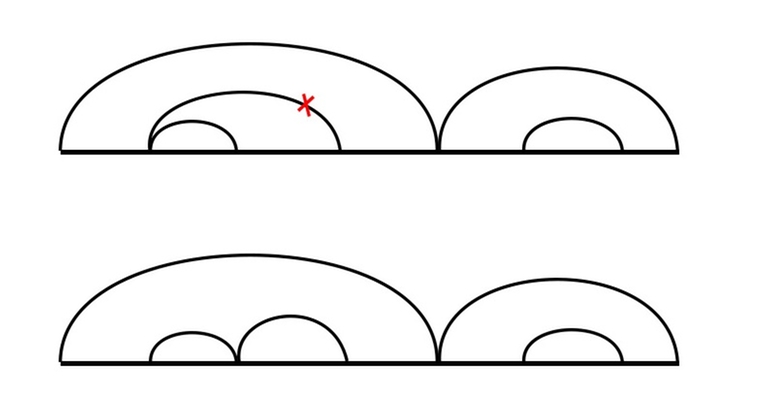
Let's draw an arc over the part of the sequence we are deleting. The arc will contain other arcs corresponding to previous removals of inner parts. Let's agree to not draw an arc from l to r if there is already an arc from l to r' (r' < r), in this case we could just as well draw it from r' to r (as the rest is deleted anyway). We do the similar if there is already an arc from l' to r (l < l'). This way we can ensure that the leftmost and the rightmost elements under the arc are deleted with the very action corresponding to the arc.
Let's follow our own advice and first take care of the obvious cases. What we can do is just apply all the transitions dp[l][r] = min(dp[l][r], dp[l][mid] + dp[mid][r]) (where l < mid < r), i.e. try to split the interval into two in all possible ways and remove them separately in an optimal way, fortunately the constraints allow us to do that.
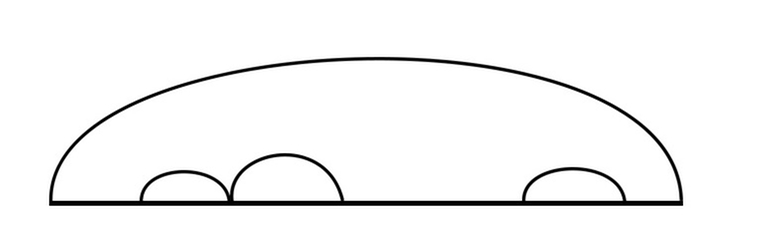
The objects we didn't cover are the ones that can't be split in two independent parts, that is the ones with an arc covering the whole sequence, or the ones where the leftmost and the rightmost elements are deleted on the very last step. First of all, this implies that the leftmost and the rightmost elements are equal, as we can only delete palindromes. If they are not equal then we have already covered all the cases with the transitions we've made. Otherwise, we still need to find the shortest set of actions that ends with simultaneous removal of the leftmost and the rightmost elements of the interval. The last action is fixed and doesn't depend on us. A general advise: if something doesn't depend on you, try to acknowledge it and digress from it.
Let's re-formulate what objects we are looking for, but now without mentioning the last action: a set of stipulated actions on the segment of a sequence that don't affect the leftmost and the rightmost elements and leads to the sequence's segment becoming a palindrome (so that we can then make the last action: delete the whole segment). In other words we want to know what is the minimal amount of steps to make a half-interval [l + 1, r - 1) become a palindrome. But this is of course just dp[l + 1][r - 1] - 1, because every object corresponding to dp[l + 1][r - 1] is essentially a set of actions that lead to the segment becoming a palindrome and then one more action to delete it. So the final transition that we need to apply in case if c[l] = c[r - 1] is dp[l][r] = min(dp[l][r], dp[l + 1][r - 1]) (do the same set of actions, but in the end instead of the removing [l + 1, r - 1) remove [l, r)).
Note: our logic breaks if r - l = 2, in this case dp[l + 1][r - 1] = 0, so we can't replace the last action in the set. In this case dp[l][r] = 1 (if c[l] = c[r - 1]).
The base states of the DP are those when r - l = 1, in this case dp[l][r] equals 1. The time complexity is O(n^3).
I hope I gave you some insight into how to easily come up with the transitions for a Subtask DP. If you enjoyed this post, please leave a like :)
If you want to know more, I remind that I do private lessons on competitive programming, the price is $25/h. Contact me on Telegram, Discord: rembocoder#3782, or in CF private messages.
Hello! I received a great response from the Codeforces community, so now I am starting a series of educational posts.
Today I want to tell about a very useful classification of dynamic programming problems that I came up with through the years of practice. I don't claim the authorship of this idea, but still I've never seen it expressed explicitly, so I will introduce my own terms. Let's call it "Subtask DP" (or "Regular DP") and "Process-Simulation DP". Today I will focus on the latter.
How were you introduced to DP? In which terms? When I was at school, I was explained that DP is just splitting a task into subtasks. First, you introduce parameters to your problem. A set of values for each parameter is called a state of the DP, which corresponds to a single subtask. Then you just need to find the answer for every state / subtask, and knowing the answer for the smaller subtasks shall help you with your current one. Let's look at an example:
AtCoder DP Contest: Problem L Two guys are playing on an array of numbers. They take turns in taking either the leftmost or the rightmost remaining element of the array until it's empty. Each one is trying to maximize the sum of elements he's taken. What will be the difference between the first and the second players' scores if they play optimally?
The solution to that problem is to introduce two parameters: l and r, with dp[l][r] being the answer to that exact problem if we only had the numbers from the interval [l, r). How do you count it? You just reduce a task to its subtask. There are two possible first moves for the first player: take the leftmost number or the rightmost number. In the first case we are left with the interval [l + 1, r), in the second case – with the interval [l, r - 1). But if we count the dp value for all intervals in the order of increasing length, then by now we must already know the outcome in both cases: it's a[l] - dp[l + 1][r] and a[r - 1] - dp[l][r - 1]. As the first player tries to maximize the difference, he'd choose the maximum of these two numbers, so the formula is dp[l][r] = max(a[l] - dp[l + 1][r], a[r - 1] - dp[l][r - 1]).
Here the subtask explanation works perfectly. And I won't lie, any DP problem can be solved using this terms. But your efficiency can grow highly if you learn this other approach that I will call process simulation. So what does it mean?
This approach is mostly used in problems that ask you to either "count the number of some objects" or to "find the best object of such type". The idea is to come up with some step-by-step process that builds such an object. Every path of this process (i.e. the sequence of steps) shall correspond to a single object. Let's have a look at an example.
118D - Caesar's Legions. After the formalization the problem will look like this:
Count the number of sequences of 0's and 1's where there are exactly n0 0's and exactly n1 1's and there can't be more than k0 0's in a row or more than k1 1's in a row.
Problems involving sequences are the obvious candidates for process simulation. In such problems the process is most usually just "Write out the sequence from left to right", one new element at each step. Here we have two possible steps: write down 0 or 1 to the right of what's already written. However, we need to allow only valid sequences, so we have to prohibit some of the steps. This is where we introduce the parameters of the process. This parameters must:
Determine which steps are valid at this point.
Be re-countable after a step is made.
Separate valid finishing states from the invalid ones.
In this case we have such rules:
No more than n0 0's in total.
No more than n1 1's in total.
No more than k0 0's in a row.
No more than k1 1's in a row.
So we have to know such parameters of the process:
How many 0's are written out already.
How many 1's are written out already.
What is the last written character.
How many such characters in a row are written out at the end right now.
If we know what those parameters are, we have all the information we need to determine if we can write out another 1 and another 0, and to re-count the parameters after making one of the steps. When using this approach, what we will store in the dp array is just some information about the paths of the process that lead into such state (where by state I also mean a set of values for each parameter). If we want to count the number of ways to fulfill the process, this information will be just the number of such paths. If we want to find some 'best' way to fulfill the process, we will store some information about the best path among such that lead to this particular state, f.i. its price or its last step, if we want to recover the best answer later.
And here is the main trick: every transition in a DP graph is a step of the process at some state. When implementing the transition from state A to state B you just need to handle all the new paths you've discovered by continuing the paths leading to the state A with a step that leads them to B. These are not all the paths that end in B, but the idea is that you have to discover them all by the time you start implementing the transitions from B. If what we store in dp is the number of such paths, then implementing the transition is just adding dp[A] to dp[B], that is add all the new-discovered paths that get to B via A to the overall number of paths that end in B.
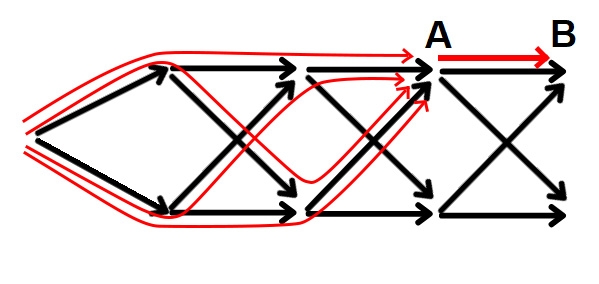
If you've heard about the forward-style DP and backward-style DP, you may have started to suspect that this is the same classification that I am describing here. However, I consider that forward-style DP and backward-style DP refer to implementation. The backward-style implementation is: "Fix the state that is not counted yet, implement the transitions leading into it"; where the forward-style is: "Fix the state that is already counted, implement the transitions starting from it".
In fact, after you've decided on the DP graph, it doesn't matter how you will implement the transitions. You can even have your own way of doing it, if you follow a simple rule: don't implement a transition from state A before a transition into state A. But still, the forward-style approach is much more suitable and meaningful for process simulation, just as the backward-style approach is for regular DP, so in 90% of the cases this classifications will coincide.
Let's get back to the problem and implement the solution. For that we need to determine what is the starting state of our process. Let's denote by dp[i][j][t][k] the state, where there are i 0s already, j 1s already, the last symbol is t and it was written k times in a row at the end. Obviously we start with i = 0 and j = 0, but what are the t and k? Technically speaking, if we start from an empty sequence, there is no such thing as "the last symbol". So let's just modify the description of our process and say that when we start, the last symbol is considered to be 0, but it's written out 0 times in a row. So the starting state is dp[0][0][0][0], and we can only start in one way, so dp[0][0][0][0] shall be equal to 1.
The rest is very easy and intuitive:
Obviously, the time complexity will equal the number of transitions in the DP graph. In that case it's O(n0 * n1 * (k0 + k1)).
543A - Writing Code There are n programmers that need to write m lines of code and make no more than b mistakes. i-th programmer makes a[i] mistakes per line. How many ways are there to do it? (Two ways are different if the number of lines that some programmer writes differs).
Let's define a process that builds such an object (a valid distribution of m lines of code among n programmers). In the problem's statement this object was represented as a sequence of numbers v[1], v[2], ..., v[n] (with v[i] being the number of lines written by the i-th programmer), as if they hint us that this is just another sequence-building problem. Let's try to define the process's step as "writing out another element of the sequence", from left to right.
In order for the sequence to be valid, these rules must hold:
The length of the sequence is n.
The sum of the elements equals m.
The sum of a[i] * v[i] for the elements is no more than b.
Thus, we need to know such parameters:
The amount of elements that have been written out already (the number of programmer fixed).
The sum of the elements that have been written out already (the number of lines of code written).
The sum of a[i] * v[i] for the elements that have been written out already (the number of mistakes made).
The number of the states for such a process will be around n * m * b. But from every state there will be around m / 2 transitions on average, that is: "write out 0", "write out 1", "write out 2", ..., "write out m - s (where s is the current sum)". So the overall number of transitions will be O(n * m^2 * b), which will not pass the time limit. This teaches us that sometimes we shall not use a building process that was described in the statement, but to think outside the box.
Let's come up with some other process. Maybe instead of going through programmers, try going through lines? That is, for every line define which programmer will write this line. In order not to count the same distribution twice, let's say that first programmer writes first v[1] lines, the second one writes v[2] next lines, etc. So if a line is written by a programmer i, the next line can be written by i-th, i + 1-th, ..., n-th programmer. Then there must be such parameters:
The amount of lines that were already written.
Which programmer wrote the last line.
How many mistakes were already made.
And again we have the same problem: there are around n * m * b states, and around n / 2 transitions out of every state on average; that is: "next line is written by the same programmer i", "next line is written by the programmer i + 1", ..., "next line is written by the programmer n". So the time complexity will be O(n^2 * m * b), which is again too long.
If we think for some time, we can see that we clearly need all of these three parameters: something about the number of programmer, something about the number of lines and something about the number of mistakes. So in order to pass the time limit we need to decrease the number of transitions out of each state, make it O(1). We clearly need at least two transitions: one to increase the lines-parameter and one to increase the programmers-parameter. If we think about it, we can come up with such a process: "In the beginning programmer 1 is sitting at the desk. At each step either the current programmer lines another line of code, or the current programmer leaves the desk and the next one sits down instead of him". The parameters are:
Which programmer sits at the desk.
The amount of lines written.
The amount of mistakes made.
The starting state is: first programmer sits at the desk, 0 lines are written, 0 mistakes are made. The amount of transitions is finally O(n * m * b). In order to decrease the memory consumption, I use the alleged parameter trick (which means I only store the dp table for the current value of the first parameter, forgetting the previous layers). Implementation:
AtCoder DP Contest: Problem D There are n objects, i-th one has a weight of w[i] and a value of v[i]. What is the maximal sum of values among all sets of objects, where the sum of weights is no more than m?
The process's step is just: "Look at the next object and either ignore it or take it". The parameters are:
How many objects we've already looked at.
The sum of weights of the taken objects.
Again, the first parameter will be alleged, so we will only store one layer of the dp table corresponding to the fixed value of the first parameter. The value of dp is the maximal sum of values of the taken objects among all processes' paths that end up in that state. Implementation:
There are a lot of other examples, where this approach significantly simplifies searching a solution, but I can't list them all here. If you enjoyed this post, please leave a like :)
If you want to know more, I remind that I do private lessons on competitive programming, the price is $30/h. Contact me on Telegram, Discord: rembocoder#3782, or in CF private messages.
Hi, everyone!
My name is Aleksandr Mokin. I've been teaching competitive programming for 3 years as my main job.
I was a winner of the All-Russian Olympiad in Informatics in 2012, an awardee in 2011 and 2013. In 2018 I became a finalist of the ICPC world programming championship.
In 2019 I started teaching and have helped dozens of people to make progress and reach their goals (see people's feedback). Since then I've developed my own approach. I don't just guide people through notorious algorithms, but also teach concrete techniques on how to solve real problems and quickly write a working code.
Now I've decided to try bringing it to another level. I want to reach the worldwide audience: feel free contacting me on Facebook, Telegram, private messages or e-mail: [email protected]. My base rate is $30/h.
If I get enough feedback, I promise to create a YouTube channel devoted to CP, write articles, create free courses and textbooks. So if you don't need private lessons, please still upvote this post, so someone can find a tutor and Codeforces can get a full-time contributor. Otherwise, the world will get another boring FAANG employee.
Competitive programming is my passion – help me fulfil my dream!






