


Problem: http://www.spoj.com/problems/CRICKDP/
I tried doing it by finding the minimum removal cost for each score in 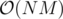 and then using this to calculate the maximum total score by DP, but this is too slow. Any other ideas will be appreciated. Thanks.
and then using this to calculate the maximum total score by DP, but this is too slow. Any other ideas will be appreciated. Thanks.






