


Привет всем! В этот вторник пройдет Codeforces Round #213, задачки для которого придумал я. Спасибо caustique, el_sanchez, KAN, malcolm, они тестировали задачи, помогали с составлением тестов и условий. Спасибо Gerald, который координировал работу и помогал в решении возникающих трудностей, MikeMirzayanov за создание возможности проводить соревнования и Delinur за перевод условий на английский.
Надеюсь, во время контеста не случится проблем с задачами и все найдут интересную для себя задачу (чтобы точно ее найти, советую прочитать как можно больше задач).
Контест закончился, можно поздравить победителей
div1:
div2:
Прошу прощения за косяки в условиях, которые вызвали тонны вопросов. Впредь я постараюсь внимательнее относиться к условиям.







scoring system?
Standard. Score distribution is not defined at the moment
The word is actually "standard". I've seen it get misspelled a lot on this site, it's about time I let people know how to spell it correctly.
[http://www.oxforddictionaries.com/definition/english/standard] [http://www.merriam-webster.com/dictionary/standard]
Thank you =)
This is a common bug for all Russians :) In fact, the word "standard" in Russian is spelled like "standartny" with "t" but not "d". And even if you know the correct English spelling sometimes it may be hard to remember the correct ending.
Cool, thanks! Now I know why it keeps happening! :)
el_sanchez onelove <ЗЗЗЗЗЗ
Oh,I smelt some special tricks..
I think we should careful with problem A. :)
yes ı misunderstood problem A. I thought digits bigger than k werent allowed :(
Yes. And I was spend for 15 minutes to thinking about sample test 2 util the announcement appear
I guess the problems will be short and interesting. Like this blog.
You know what's interesting?
Did you know facts are considered to be interesting. So this proves there are things that are universally interesting.
I don't understand your mind clearly. But I think interesting 's different with every pepple. With me, that 's tricky test and many solution has ben hacked! O_o
Как можно больше задач... Автор боится проблем с авторским правом, если вдруг посоветует прочесть условия ВСЕХ задач? =)
Я бы тоже боялся. Ты видел бицак у Sereja?
Пруфпик в правке =)
Выложи голого Sereja — основательно повысь свой вклад!
hope problems will be good..
don't even hope that problems would be so easy for you
A strange comment for a gray one...
Guy that writes gray code?
No.Guy who has the rating very small(of colour grey).You are purple, I guess
giygctr gotcs metrr o'le!!
wut?
giygctr gotcs metrr o'le!!
why is today's problemset so hard?
This round is similar to Round 144 Div1 результаты This round prepared by tunyash too.
look at Antoniuk at div. 1. He worked well :D
P.S : He is in last page.
this exam very suck for div 2 everyone have solved A and B and no one able to resolve the C , D , E
I can't agree with U. Problem C was just an exercise for Range Tree, main problem was to realize it(I wasn't successful in it ._.).
sum(x,y,z,t)= (s[x]+...+s[y])*(s[z]+..+s[t]) = a
you can solve this by fixed [x] and [y] and pre calculating [z] and [t]
nothing about Range Tree i guess.
Damn, U're right, it's easier way :)
Как "С" решалась? Динамика какая — та?
Можно заметить, что сумма чисел в прямоугольнике с такими координатами будет sum(x,y)*sum(z,t), где суммирование идёт по соответствующим индексам строки s. Нужно лишь рассмотреть все варианты таких сумм и аккуратно подсчитать те из них, которые могут дать в итоге a.
a должно быть равно произведению сумм на каких-то отрезках. Итого находим всевозможные суммы на отрезках, подсчитываем, сколько раз они встречаются, далее за линию от количества таких сумм подбираем подходящую пару.
Div.1, давай, до свидания! :)
Задачи A и B на внимательность)
Does anyone knows the 4-th test for B?
I think, something like — 5 0 0 0 0 0, answer is 5
I think 5 0 0 0 0 0 will output 2
No:)
0 + 0 = 0 .. so 5 zeros will yield answer 5
If anyone can tell me what is the pretest 3 for problem A div 2 I would be very thankful...
Show your code.
Here:
5162244
Upload it here.
Here:
http://pastebin.com/YhY9af03
The digit in number can repeat.
It's false.
UPD: It's true.
k goes from 0 to 9....
Why should I return false like that if I am already doing the repeated number exclusion with the set?
EDIT: By doing the vv.size()==k+1 I am assuring that my function also returns correct values, yes or no?
I don't understood problems.
What if k == 0 and numbers on liste equals to zero too? Your programm return automatically 0 when k == 0 But for this input:
It should return 1 instead of 0
http://codeforces.me/blog/entry/9625#comment-151387
This input is invalid (1 <= ai <= 10^9)
The test would be like this:
Answer should be 1.
No leading zeroes are allowed, from my understanding:
"The first line contains integers n and k (1 ≤ n ≤ 100, 0 ≤ k ≤ 9). The i-th of the following n lines contains integer ai without leading zeroes (1 ≤ ai ≤ 10^9)."
So that wouldn't be a valid test....
No leading zeroes are allowed, so it can be like this:
Answer still should be 1.
MISTAKE: k-good number should contain each digits no more than k, but if number contains each digits no more than k AND other digits more than k, it still be k-good number.
case 2 0 0 0
answer =2 your code gives 0
Numbers can't be 0.......
1 0 10
interesting observation about k == 9, but k == 0 ...
Does anybody know what's the 5-th tests for C ? I would be very thankful
0 00 и 0 110
aaaand the naswer is 9
Kind of: 0 005 answer: 27
i am so f**ing idiot
Div 2. Problem C
The moment I realized I can't think better than O(n^3logn) or O(n^4) for MaxSum in a rectangle.
That was the moment I realized the array contained only digits so I could do it in O(n^2).
Most enlightening moment I got in a contest.
I had an O(n^2log(n)) solution that I couldn't finish coding. I'm not sure if it is correct though, because it uses O(n^2) space.
how do you do n^3logn?
where are the editorials/tutorial to div2 213?
not posted yet i guess
У меня по Е O(nmk) работало 15 секунд локально. Надеюсь, авторское не написано на указателях с кучей оптимизаций?
Авторское и тестерское разделяй и властвуй за N^2logNK отлично укладывается в TL
Хм, да, у меня то же самое. Я решил что здесь T(N) = O(N^2) + 2T(N/2), поэтому посчитал что логарифма нет. Так вот, оно у меня работает довольно долго без оптимайзов. Авторы в рекурсию массивы не передавали, я так понял?
Мое тестерское решение работает 10.2 с http://pastie.org/8493248 , у Артура оптимальнее написано.
В нем как видно есть лишние проходы по массиву и никаких оптимизаций не накручено. Массивы и правда в рекурсию не передаются, а к чему?
Ну офигеть, моя Е получает АС в дорешивании. Это при том что я ее долго пытался соптимайзить, потом плюнул и за минуту до конца послал, но забыл ввод раскомментить и она упала на 1 претесте, а перепослать уже не успел. Все из-за того, что на запуске стоит ТЛ 10 секунд, а локально она у меня работала 15. Кстати, прошла за 11.996, как и у единственного сдавшего ее на контесте, что очень странно. Зачем делать такой ТЛ, который даже нельзя проверить на запуске?
Жаль, что так получилось. Я не знал, что ТЛ в запуске 10 секунд. Вроде бы, моя реализация более-менее starightforward.
Кстати да, в Полигоне и на CF в дорешке тоже по-разному время меряется) Вот у меня теперь на секунду быстрее зашло.
Нельзя сказать, конечно, что TL был с запасом, но такие ограничения были, чтобы предотвратить решения за куб — зафиксируем две строчки, а дальше двумя указателями посчитаем количество отрезков с заданной суммой.
Или большинство тестов проходит тот же разделяй и властвуй, но где мы на фазе объединения ответов для фиксированной строчки не за O(k) прыгаем, а тупо идем и делаем break, когда набрали большую сумму. Такое решение фейлится только на таблице из почти всех нулей, но на этот случай можно другую заглушку поставить.
Но вообще я согласен, что немного Гера с Артуром перегнули — в итоге хорошую задачу почти никто не сдал, а твое норм решение тоже еле зашло, да и то не на контесте.
Кстати говоря, в оправдание, макстесты были в претестах — это претесты # 7 и 9. Почему бы после того, как завелось на сэмплах, было сразу не отправить? Ведь время на задачу все равно уже было порядочно потрачено, так что попробовать точно стоило:)
Да я все надеялся ускорить, а оно не работало. Потом за минуту до конца решил все вернуть обратно, сделал даже сабмит, но в нем не раскомментил ввод и оно упало на 1-м семпле. А заметил это когда было уже поздно.
Ну, там не деоптимизировано, но без излишеств. Укладывается больше, чем в 2 раза
The bad description of problem D div2(problem B div1) really makes me mad!!!!
I read it more than 5 times and still don't know what are you talking about, until I found the Note at the bottom and read the Note more than 5 times.
How can you use nothing to exchange something?
You should say:
Set x can contain nothing.
Set x and Set y can't contain the same item instead of the shit of "Note that each item is one of a kind and that means that you cannot exchange set {a, b} for set {v, a}. However, you can always exchange set x for any set y, unless there is item p, such that p occurs in x and p occurs in y.".
"John knows that his city has n items in total." Ok, there are n items in the city, but how many items in the market?
For the second sample, why cost two days? why not three days? Input 3 5 1 2 3 output 6 2
first day =
{} -> {1,2}now assume he leaves
{1,2}at his home.second day =
{} -> {3}so now he has all of
{1,2,3}with him in two days.Thanks, I got it. It's hard to understand this problem of the poor description, but the solution seems not that hard.
Any Ideas for problem C , Div 2 ?
You observe that in a rectangle the sum is (Ax1+A(x1 + 1)+...+Ax2)*(Ay1+A(y1 + 1)+...+Ay2), where x1,y1,x2,y2 are the corners, and the maximum sum of a sequence is 9*n.
Range Tree. U just need to find all x1, y1, x2, y2: sum(x1, y1) * sum(x2, y2) == a. But you should do it smart: 1)Find all x, y: a % sum(x, y) == 0 2)for each of them find all x1, y1: sum(x, y) * sum(x1, y1) == a
It seems like this solution is )(n ** 4 * log(a)(because of Range Tree)), but it is O(n**2 * k * log(a)), where k is number of divisors of a(close to log(a)).
No range tree. You just need to factor n and n is equal to the multiplication of range sums that can be calculated in quadratic time
No.You just keep a vector ap where ap[i]=number of sequences of sum i, i<=9*n. For a subsequence [i,j], if A%sum(i,j)==0, you add at result ap[A/sum(i,j)].Take care at the case when sum(i,j)=0 and when A=0
Anybody home ? someone start system testing
Претест 2 задача С кто-нибудь знает?
По идее он есть в сэмле
К сожалению, на сэмплах работает верно, но выдает ВА на претест 2
In problem A
When writing
Let's call a number k-good if it contains all digits not exceeding k (0, ..., k).Here, doesn't it mean that a k-good number can't have any digit greater than k ???
So far I know, it means, a k-good number can have all digits without those which are greater than k. Any digit in that number can't exceed 'k'.
It has given me a lot of pain.
You cannot assume that it does not contain digits greater than k as long as it has not been mentioned in the statement.
Actually, you just cannot assume something when it has not been specified in the problem statement.
Nooo, finally found out one minute after the competition, that my C gave time limit exceeded because I forgot to print the final \n. First time I've had that bug :(
Сложный был раунд :(
Got owned for the 100th time by integer overflow for div1 A T_T
<epic fail>
in my code was:
typedef int li;...
#define int li</epic fail>
P.S. Of course, it must be
typedef long long liSame here, mistakes like this will kill me someday.
Hoping rating doesn't decrease much ...
Overflow too. T_T
Congratz lovelymoon for his E 5163338 :D (11.996s, TL is 12s)
Вот это решение висит на 5 претесте.
видимо поэтому до сих пор вместо надписи "результаты" висит надпись "системное тестирование"
У него в посылках уже 2 "полных решений" по этой задаче. Странно.
Спасибо огромное за раунд, очень крутые задачи! Надо было читать все задачи и решать милую D, а не пытаться конструктивно строить ответ в C:)
В C он нормально конструктивно строится. Ну как. Конструктив и немного random_shuffle :)
В C очень захотелось впилить какой-нибудь строгий вероятностный метод в стиле Алона-Спенсера. =)
А по-моему, в С очень хочется написать перебор и генерить разные числа при зафиксированном количестве простых.
Наверное, ее бы сдали больше, если бы поменяли 1000 и 1500 местами.
Вот если бы D и C поменять, то D бы точно больше посдавали! Ну, или хотя бы попытались посдавать...
Ты серьезно? Но ведь в C проходило что угодно, честно говоря, и локально тестить это было просто:)
Мне кажется, или мало кто следует советам авторов читать условия всех задач?
Лично на мой вкус, задачи A, B, C сегодня были сравнимы по сложности и простой пропихон по D тоже придумывался — надо было просто поподгонять, сколько рандомных чисел мы можем зафиксировать, если нормальной идеи в голову не приходило.
Наверное, такой низкий процент сдавших задачу потому, что многие зациклились на B, хотя она была не самой очевидной:)
А кто-нибудь еще понял B так, что мы всегда обязаны менять все свои вещи?
Да, я так и понял. Потому что если в наборах, которые мы можем поменять, есть одинаковые вещи (на это был акцент в условии), то мы можем их не учитывать — все равно сможем поменять.
B? B про фибоначи было, а если ты про D, то там нормально сформулировано и примеры показаны.
Сиреневые, оранжевые и красные — первый дивизион(1700+). Ты во втором дивизионе.
А когда рейтинг будет подсчитан?
По идее, минут через 10-20.
What is the intended solution for Div1 C? Is it possible to prove it without testing all valid inputs?
UPD: Sorry, here was the solution for B, not C.
Correct. That is, however, the solution to Div1-B :)
Ah well, that makes sense:) Sorry
Well, since you already wrote it, you should probably leave it around, maybe in a separate thread.
I think this is solution for Div1 B, not Div1 C
I understand that the reduction works, but why does that mean that the restriction doesn't mean anything? Why can't the algorithm still find a move that is illegal?
Consider any two sets A and B, with c(A) + d >= c(B). Let their intersection be denoted as C, meaning A\C and B\C don't have anything in common.
c(A) = c(A\C + C) = c(A\C) + c(C) >= c(B) — d = c(B\C) + c(C) — d
c(A\C) >= c(B\C) — d
We can substitute set A\C with set B\C, thus turning A into B.
Therefore, for any two sets A and B such that c(A) + d >= C(B) we can turn one into another in one step.
Every step in our algorithm does exactly that, so every move we make is legal.
Does that explain it?
Yep, I got it now, thx.
I thought we have to swap whole set we have currently with some other set. Really poor problem statement. :(
Yes, I thought that too, until I analyzed the sample test cases.
Mmm. My solution constructs correct set with k' ≥ k elements. It's possible to prove, that we can obtain correct set for any k. But then I use statistic to prove, that I can obtain correct set with exactly k elements. I will write about it in editorial.
По С у меня успешно получается сдать решение, которое на самом деле WA. 5164319 не работает для чисел 318-326, 1657-1685. Если еще немного уменьшить одну из констант, которая на контесте подбиралась методом угадывания, то можно заставить его не проходить еще больше тестов, получая при этом АС.
А может тебе в профессиональные тестеры пойти? Постоянно ты заталкиваешь неправильные решения, особенно часто TL-решения на Опенкапе.
Спасибо, я подумаю над этим)
Но вообще это неблагодарное дело, вот составлю хорошие тесты к какой-то задаче — и потом столько людей недополучит свои АС из-за меня. Грустить будут. Оно мне надо?
Как решается div1 D? Что-то мне она не показалась простой)
Только что в дорешивание сдал такое: 20 раз возьмем рандомную пару из массива и посчитаем их gcd — g. Вероятность, что за 20 попыток мы возьмем 2 числа из половины, которая соотвествует оптимальному ответу, очень близка к единице. На каждой из 20 итераций теперь возьмем gcd(g, a[i]). Среди этих чисел — делителей g — надо найти наибольший делитель, на который делится хотя бы половина чисел. Будем делать это за квадрат от количества делителей, и по не совсем очевидным причинам наше решение зайдет.
А можно десять раз взять одно число.
Даже так :D Непонятно тогда, почему эта задача стоит как D, если это баянистая идея + straightforward решение. Правда не совсем очевидно, почему это заходит, ведь количество делителей у числа до 1012, казалось бы, обычно около 104, и решение работает за что-то около 109. Хотя у меня отсечения еще какие-то были, может без них не заходило.
А с каких пор 10^9 за 4 секунды не заходит?
Непонятно, почему если задача боянистая, то ее никто не посдавал:) Между прочим, автор предупреждал читать условия всех задач, но всем как обычно пофиг)
Ну вот я прочитал, только непредвиденное обстоятельство в шаблоне меня погубило :D
И вроде делителей должно быть примерно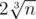 , так что это что-то в духе 2·109. А еще можно было предположить, что авторы сделали тесты, на которых количество делителей всегда получается большое, и тогда решение может работать намного дольше.
, так что это что-то в духе 2·109. А еще можно было предположить, что авторы сделали тесты, на которых количество делителей всегда получается большое, и тогда решение может работать намного дольше.
А еще Артур говорит, что максимальное количество делителей 6700. Можно как-то пострессить или погуглить, но предлагаю поверить ему на слово.
Я как тестер написал такое решение, оно зашло за 3 секунды и мы его считали хоть пропихоном, но нормальным.
Кстати, на GNU C++ заходит (а в Полигоне только GNU), а вот на MSVS почему-то нет:(
А, ну это вполне логично.
А за сколько оно на джаве работало?
А на джаве мы решения не писали. Но мое решение http://pastie.org/8495137 не использует никаких специфичных конструкций C++ так что может быть легко переведено и скорей всего отработает за то же самое время. Может быть ты напишешь решение на Джаве?
Ну вот повезло и 7 итераций зашло: http://codeforces.me/contest/364/submission/5179270
Вот я 7 итераций соптимайзил и тоже зашло: http://codeforces.me/contest/364/submission/5179297
Ну я проверил, зайдет ли 8, не повезло и WA: http://codeforces.me/contest/364/submission/5179302
А вот я ещё дурью помаялся, быстрее не стало, но повезло и 8 зашло: http://codeforces.me/contest/364/submission/5179333
Ну то есть 10 я не представляю как на Джаве сдавать.
А почему до сих пор не существует общепринятого правила писать авторское решение на джаве?
Помимо того, что это позволит правильно выставить TL и избежать негативных откликов после контеста, это еще и обеспечивает надежность решения. Решения на C++ ненадежны, т.к. в этом языке можно творить что угодно, и оно может при этом работать. До определенного момента. Например, до получения вердикта взлома "Неизвестный вердикт:OTHER".
Вообще предполагалось решение в таком духе: возьмем случайное число, посмотрим на все его делители, возьмем gcd со всеми остальными и теперь можно посчитать для каждого числа количество кратных ему за O(d) операций (d — количество делителей). Получалось O(iter * n log R + iter * d^2). Вообще это долго, если делать количество итераций не впритык, а с запасом. Поэтому авторское решение делает на итерацию примерно в 10 раз меньше действий, оптимизируя обе части асимптотики. Можно, например, вместо того, чтобы считать все перебором за d^2 считать все за d*2^(primes), где primes — количество различных простых в разложении текущего числа. Легко видеть, что оба сомножителя одновременно не достигают верхней оценки. Первую часть можно оптимизировать, используя статистику. Получается считать gcd за O(primes) К сожалению, я не придумал, как одновременно сделать в авторском решении количество итераций с запасом и не дать зайти решениям без оптимизаций =( Но как-то все равно задачу сдали всего два участника.
Nice contest and interesting problems.... Like your other contests....thanks!
Is there an alternate solution for Prob:C Div2 ? Something using Data-Structures ?
k-good numbers input 1 0 1000000000
Output
1
really 1<0?
It must contain all digits who doesn't exceed k, so if 0 wasn't present, the number was invalid. But it can contain digits who exceed k, that's not a problem. So, yes , 1 > 0, but 1 0 1000000000 should get for output 1
very bad translation, it is k-good if it contains all of (0,..,k) was better, I'm not American by the way
kind of know the reason. "the number contains all digit from 0 to k " is not equal to " the number only can contains all digit from 0 to k.". I should not have this assumption.
Actually problem is in "not exceeding k (0, ..., k)". There was no need of this portion.
When writing
Let's call a number k-good if it contains all digits not exceeding k (0, ..., k).it means, a k-good number can have all digits without those which are greater than k. Any digit in that number can't exceed 'k'.Anyway which happened it was to be happened. No doubt, short description of last contest was nice to see. But we also hope better translation from this great community.
tanks for the contest. this was to this date my best contest and I don't think I am ever going to get a better rank in codeforces. I didn't like problem C, I solved using simple backtrack. problem A and B and D were great.
That moment in which you get WA #115 on Div1-D because you forgot that rand() only goes up to 32767... :(
Can you describe your idea?
Suppose you know GHD divides some element a[i] of the array. You can then take the gcd of a[i] and all other elements, and count how many times each of the divisors of a[i] also divides other elements of the array (should be easy to do in n log n). The largest one that appears more than n/2 times is the GHD.
Now, the question is finding such an element a[i] quickly. But as GHD divides at least half of the a[i]s, the chance that you take an a[i] that has the required property is over 50%! So just take a[i]s randomly until you run out of time.
I see such chuck of your code. It doesn't seem to be O(NlogN) as announced in your short editorial, it's rather O(NlogN + (number of divisors of a[i])2 which consumes much more time.
Can you tell how you're going to process this part of solution in O(NlogN) time?
Maximum number of divisors for a number up to 1012 is less than 7000. So it is not considerably worse than O(NlogN) part I think.
It's true assumption when one is trying to code working solution during a contest but what if the numbers will be up to 10^16? You still we be able to factor one number quite quickly and to calculate all GCDs quickly but the part with 2 loops to traverse list of divisors will be bottle-neck in such solution.
I'm just trying to figure out better approach to solve this problem.
vector d represent the divisors of a[idx] which is theoretical have at most 2*sqrt(a[idx]) elements. but practical it is much less.
What a weird solution !
thank you.
that too, it was the last test! really unfortunate!
please update ratings! thank you so much
Не люблю моменты когда не проходит по времени только из-за того, что поставил long long вместо int!
Просто в этой задаче можно обойтись без сортировки 8 миллионов чисел — тогда даже на Java все спокойно зайдет за 78мс.
Поздравляю с красным цветом:)
Спасибо.
Трудно было представить лучший подарок на 20-летие :).
Поздравляю еще и с Днем рождения! Так держать на полуфинале:)
И еще раз спасибо! :)
Вот интересно, сколько человек в A div 1 решала задачу, которая написана в условии, т.е. с ограничением
x ≤ y, z ≤ t? Это ограничение ведь читается какx ≤ y; x ≤ z; y ≤ t; z ≤ t!Автор явно не читал это.
Кстати, да, запятая шрифта формулы, а не текста :) !
x ≤ y, z ≤ t (всё в одних долларах)
x ≤ y, z ≤ t (две формулы в разных долларах — более правильный вариант)
В PDF-ке после текстовой запятой пробел между формулами был бы ощутимо больше, но для HTML «правильный» вариант тоже плохо подходит, его трудно отличить. Лучше вставлять какой-нибудь текст — или точку с запятой, как советует droptable.
Кстати, если уж придираться к условиям: в задаче E пять примеров, и из них ни одного не квадратного. (Не то чтобы это сильно помогло бы решить конкретную задачу...)
Ух, да, вы правы. Но, надеюсь, никто так не воспринял.
I hope Petr rise again :)
:)
I just found the "problem revision"(30) in the detailed submission page.
But What is the problem revision? Thanks for help!
Problem Lang Verdict
365D — 30 GNU C++ Wrong answer on test 8
This contest is very great, with so many rand() needed and some hard problems :-P
Задачи были интересными! Автор ждем от тебя еще контестов...
Editorials please !! :)
hi everyone, for problem B,
why this verdict???
1 1000 Answer 1 Checker Log wrong answer Answer contains longer sequence [length = 1], but output contains 0 elements
You don't print anything. Look at if(n==1)
Could anyone have a look on my submission 5162269 for Matrix problem? I don't understand why I am getting a run time error...
It looks like you divide by zero in this string.
i think it maybe because you are trying to compute
a%(it->first)anda/(it->first), but the value ofit->firstmaybe zero if the string contains a0character.Thanks for the contest, Finally I became blue!! :D ..
at the very beginning i got problem A,B done within half an hour while just before the contest end,i wrongly took the lower bound of ai as 0 and think i may be able to hack some careless guys who also didnt handle the data 0,so i quickly submitted problem A again with speical judgement for the case when ai is 0,...then the system reply tell me ai must be >= 1.and my rank in room suddenly drop from 8 to 16.. it really proves that evil will be rewarded with evil.ToT
A and B 's very easy. But C 's so hard. (Just with me :) )
i liked the problems, though i could not participate
Is there someone fix the description of problem D. Free Market? How to understand this statements: "Note that each item is one of a kind and that means that you cannot exchange set {a, b} for set {v, a}. However, you can always exchange set x for any set y, unless there is item p, such that p occurs in x and p occurs in y.". For the samples, second one, why 2 days? one change a day, at least three days? input 3 5 1 2 3 output 6 2
How could those get AC?
link to previous comment
Разбора не будет?
+
I look forward to editorial
it has been published here
Thanks for beautiful problems.I enjoyed so much :)
Unbelievably lucky! lovelymoon's (div1 winner) E problem takes 11996 ms (TL is 12s) on the maximum test case :)