


Предлагаю обсуждать здесь задачи прошедшего Гран-При.
Кто знает как решать C?
Есть ли у кого-нибудь нормальное решение на Java в K? Т.е. без суммирований double'ов от мелких к крупным, без упаковываний по 100 подряд идующих результатов в BigDecimal, etc. Ну и особо интересно, есть ли у жюри джава-решение, уклавывающееся в половину time/memory лимита.
Upd. Ссылки на решения задач в комментариях:







Откуда задачи div1? По логике — CERC, но у них 12 задач, и контест еще даже не закончился.
К тому же CERC — это центральноевропейский полуфинал, а здесь GP of Eastern Europe
Польские ограничения и польские слова в условии намекают.
Я уже нашел, 2013 Polish Collegiate Programming Contest. Оф.сайт
Во втором дивизионе добавили NCPC, это тоже не совсем восток. Кстати, задачи вообще не светились в рунете за последний месяц, ну вообще не светились.
Кстати, я как тренер команд, считаю это очень большой проблемой Открытого Кубка и других контестов от Снарка — он использует какие-то задачи, но в истории не сохраняется откуда конкретно были задачи.
Например, по этой причине на тренировках Codeforces я обновляю информацию после окончания тренировки, подробно указывая источник задач.
Похожая неприятность — например, Div. 2 контест этого кубка. Там часть задач из крутого польского контеста, который в результате запален для команды. С другой стороны, через годик-другой подкачавшись, он бы вполне по силам команде.
Хорошие качественные контесты представляют серьезную ценность и разрывать их на задачи почти никогда не стоит. Наверное, если контест уже устарел, то можно и то лучше указывать источник.
С этой точки зрения единственный хороший вариант Div2 — отдельный несложный контест, никак не пересекающийся по задачам. Но непонятно, откуда его брать: каждый набор Div1-задач соответствует некоторому онсайту, и кажется, что Div2-онсайтов, подготовленных на сравнимом уровне, меньше.
Например, FarEastern Subregional -во время Гран-При Сибири. Но претензии были в обратную сторону — "почему div2 совсем другой"...
Впрочем, из несложных Subregionals это единственный, который рассматривается как вариант Div2 Гран-При. Рыбинский ЧФ, к сожалению, расположен очень неудачно по времени.
Давать раздельные Div2 и Div1 тоже не вполне правильно — как минимум, когда такого рода варианты предлагаются, участники высказывают недовольство.
Что касается NCPC-2013, то этот контест ценности не представляет вообще (в качестве отдельной тренировки). На редкость неудачный подбор сложных задач в смысле их засвеченности...
Так может отказаться вообще от Div2?
Команды с уровнем пониже всегда могут найти достаточное количество тренировок, чтобы развиваться дальше.
Здесь два момента.
Предлагаю во всех контестах, где ты используешь задачи не специально подготовленные для твоего контеста (наверное, это почти все) указывать источник задач. Можно и после окончания. Причем источник должен становиться частью названия контеста, а не просто фигурировать в комментариях или как новость на сайте.
Ну не так и мало есть хороших несложных учебных задач. Например, цикл интернет-олимпиад. Да и просто подливать можно к устаревшим контестам.
В данном случае, я имел ввиду, что для Div.2 участников запалился отличный польский контест.
С другой стороны, Div2 участники решали упрощённую версию этого контеста "здесь и сейчас". И тоже для них это была полезная тренировка. А к моменту, когда эти команды "дорастут", идеи из основных задач вполне могут встретиться где-то ещё; при этом качественных новых контестов сейчас появляется достаточно (например, те же контесты в Петрозаводске).
При непересекающихся Гран-При проблема всё равно остаётся: обсуждаться здесь всё будет в единой ветке, так что идеи задач участники увидят; да и в дорешивании задачи появятся.
А ещё не решавшиеся ими Div1 Only задачи вставляются в какой-нибудь сборный контест (тематический или просто усложнённый) и даются этой команде. Проблема поиска контеста, "который не даётся целиком" и в котором есть хорошие задачи для составления сборных контестов, тоже существует.
Я извиняюсь, а Вы писали сегодня опенкап? Или просто очаг горит?
Писал, LNU Motorbreath — команда, состоящая из... Из меня)
А при чем здесь "горит-не горит"? Возможно, горело бы, если бы я писал div2. А по поводу div1 я вообще ничего негативного не написал.
Кстати, а можно попросить координатора всё же указывать состав львовских команд?
Написал ему.
У нас K зашло в BigInteger. Но все равно я кучу времени убил, так как сразу не решился так сделать.
А зачем там BigInteger? У нас вроде бы решение подходит под критерий "на Java, без суммирований double'ов от мелких к крупным, без упаковываний по 100 подряд идующих результатов в BigDecimal, etc", но все равно пришлось сильно постараться, чтобы в TL зашло.
А как решать? :D
Посчитаем для каждого прямоугольника суммарную площадь пересечения со всеми остальными прямоугольниками (если по какой-то клетке пересекается с несколькими прямоугольниками, то посчитаем эту клетку несколько раз). Это число влазит в лонг. Теперь поделим его на n*(n-1) и просуммируем по всем прямоугольникам. Это и есть ответ.
Как, собственно, считать это число для каждого прямоугольника? Будем хранить дерево отрезков по х-координате (так, чтобы для некоторого отрезка по х мы могли узнать общее количество клеток, которые лежат ниже текущего y). Будем идти по увеличению y-координаты и делать следующее. Если начался некоторый прямоугольник, то посмотрим в дереве отрезков, какая сумма уже накопилась для отрезка, который соответствует х-координате прямоугольника и вычтем ее из ответа для этого прямоугольника, а также добавим сам прямоугольник в дерево отрезков (мы добавляем линейную функцию от y). Когда прямоугольник закончился, опять посмотрим в дерево отрезков и добавим к ответу для прямоугольника то количество клеток, которое уже накопилось и удалим прямоугольник из дерева отрезков (вычтем ту же линейную функцию и добавим высоту прямоугольника).
Чтобы на джаве это зашло в ML и TL, сожмем координаты и заменим дерево отрезков на дерево Фенвика.
P. S. последний шаг очень увлекательный! Когда мы сжимаем координаты, то теперь у каждого Х есть свой вес, который нужно учитывать в дереве Фенвика. Ну а чтобы уметь модифицировать в дереве Фенвика некоторый отрезок сразу, можно воспользоваться трюком, который описан здесь.
Для загона в ТЛ и МЛ не обязательно переделывать на Фенвика — сжатия координат достаточно. Правда, дерево отрезков в лонгах работает впритык, и ТЛится в зависимости от погодных условий. Мы заменили лонги на даблы, это работало быстрее, но точность немного терялась. После шаманизма со сложением даблов от мелких к крупным (который позволил нам пройти до 32 теста вместо 30), мы таки вернули лонги и посабмитили ещё пару раз :) В итоге зашло.
Вообще, просить выводить 14 точных знаков double — то ещё издевательство. Хотя, вполне в духе польских контестов — там всегда всё впритык.
А кто может объяснить, почему это решение tunyash с контеста получает ML 1? http://pastie.org/8487107
Казалось бы, памяти тратится 222·(4 + 8) + 200000 * 2 * 4 = 50 * 106 б = 50 Мб при грубом подсчете. Но ML ведь 128!!!
Попробуйте вывести sizeof(in) + sizeof(out) и всё поймёте :)
Ого, оказывается пустой вектор занимает 20 байт и даже clear() не помогает!
Это же грабеж посреди бела дня! С этим как-то можно бороться?
*Фигню написал. А с чем бороться? Вектору size + capacity + указатель на начало нужен же.
А можно поподробнее?
size_t — это 4 байта, void* — это видимо тоже 4 (хотя может и 8 на 64-битной системе?)
Откуда тут sizeof(int)?
Получается 8 или 12 байт
Под 32-битным компилятором получится 12 байт. Под 64-битным — 24.
Ну у меня на 64 битной тачке sizeof(vector) = 24 : 2*sizeof(size_t) + sizeof(void*), на 32 битной 12, всё логично.
Ну там же ещё 4 миллиона пустых векторов создаётся (а некоторые из них — даже непустые). Каждый из них байт 20 дополнительно даёт (ну или того порядка).
Илья, а мы считали целую часть у дроби 100*числитель/(n*(n-1)/2). А это уже отлично влазит в long long.
Проблема в том, что на джаве дерево интервалов в лонгах медленнее даблового (и не очень хорошо влезало в ТЛ), поэтому даблы уже из дерева выходили...
Мы делали по-другому, но также с использованием дерева отрезков: посчитаем для каждой клетки количество прямоугольников, которым она принадлежит, пусть это fxy. Тогда ответ — это сумма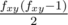 по всем x, y, поделенная на
по всем x, y, поделенная на 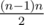 . Будем идти сканирующей прямой по x и поддерживать дерево отрезков по y с операцией изменения на отрезке, в каждом узле которого мы храним число клеток в этом узле — sum0, сумму значений функции fxy — sum1, и сумму величин
. Будем идти сканирующей прямой по x и поддерживать дерево отрезков по y с операцией изменения на отрезке, в каждом узле которого мы храним число клеток в этом узле — sum0, сумму значений функции fxy — sum1, и сумму величин 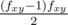 — sum2. Нетрудно убедиться, что при добавлении на каком-то отрезке ко всем значениям ф-ции fxy числа k эти величины изменяются по следующим формлуам:
— sum2. Нетрудно убедиться, что при добавлении на каком-то отрезке ко всем значениям ф-ции fxy числа k эти величины изменяются по следующим формлуам:
Далее, при обработке каждого события мы сначала прибавляем к ответу значение sum2 в корне дерева отрезков, деленное на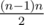 , затем добавляем/удаляем 1 на каком-то отрезке. Наконец, вспоминаем про сжатие координат)
, затем добавляем/удаляем 1 на каком-то отрезке. Наконец, вспоминаем про сжатие координат)
UPD: и тут тоже даблов не хватает((( хорошо, что в c++ есть long double
А вот у нас так получилось ТЛЕ 21 и времени не было исправить. http://pastebin.com/7sWzXzY1
Мне кажется, все-таки сжатие координат необходимо. Если что, вот наш код: http://pastebin.com/AumL8N6c
Такое же решение проходит без сжатия координат, если использовать __int128_t под 64-битным компилятором(с long double — TLE 21) http://pastebin.com/DVf1sNWa
Писали ровно то же самое на С++, WA17. В чем дело — без понятия, перечитывали код несколько раз. Магия какая-то.
А как А решать?
Авторские разборы контеста
Нихера непонятно, не по-русски как-то написано.
По-польски не читаешь?
Мы сдали следующее:
заметим, что для фиксированной длины прыжка x легко проверить ответ, так как каждая пара соседних задает отрезок в котором может лежать начало — просто смотрим их пересечение. Теперь, если бы мы знали хоть какое то значение при котором ответ да, то могли бы найти ответ бинарным поиском. Тут попутно использовалось что область возможных значений связна, но я думаю это достаточно очевидно.
Для нахождения такого значения воспользуемся тернарным поиском по длине отрезка возможных начал для фиксированного x, разрешив этой длине быть отрицательной (просто независимо считаем правую и левую границу).
Если посмотреть на формулу для двух соседних, то видно что их max (или min для правой границы) выглядят как выпуклые оболочки.
(disclaimer: не знаю, заходит ли, у нас времени что-либо кодить не было, благодаря K)
У нас есть 2 double'овых переменные (начало и шаг) и линейные неравенства с этими переменными. Линейные неравенства задают полуплоскости, их можно пересечь за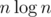 , а в полученной области уже найти что просят, перебрав вершины.
, а в полученной области уже найти что просят, перебрав вершины.
На самом деле, в этой задаче нет "параллельных" неравенств, а также неравенства (как полуплоскости) тривиально отсортировать по полярному углу. Более того, известно, что решение есть. И, кажется, множество решений ограничено.
То есть получается решение за линейное время, причём не сильно сложное.
У нас зашло. Мы правда линейное рандомизированное писали. Оно как раз самую высокую точку находит. И когда пересечение точно непусто кода совсем мало.
А мы свели к поиску максимальной суммы не отрезке в массиве. Переход к такой постановке нетривиальный был.
Когда дорешивание будет?
в Yandex.Contest можно дорешивать.
Мы сразу же после получения логина поменяли пароль, поэтому доступа к Яндекс.Контесту у нас нет.
Обратитесь к координатору сектора. На его Яндекс почте лежит информация о всех паролях сектора.
Кажется, сейчас дорешивание поднято, но что бы то ни было у меня получает WA/PE test #1. Видно, поднято не до конца.
Похоже уже поправили + реджадж всех посылок сделали.
Забавно — в задаче F через секунду после сабмита осознал, что моё решение выводит на тест "1 2" ответ "0", что является полной чушью. Однако, оно зашло.
Правда, что в G все сдавали разного рода переборы, основанные на идее, что кучки в итоге разобьются приблизительно пополам (с учётом отдельно обработанных 0, 5, 7 и 1)?
Мы так и сдали, впрочем, то, что нужно делить почти пополам казалось бы доказывается без особых проблем.
То есть, количество какой-то цифры в обоих множествах будет отличаться на О(1)?
Если имелось ввиду что эта величина ограничена сверху числом не зависящим от входных данных, то ответ да.
In upsolving the first test on I is incorrect: N>1e6
А правда, что раньше можно было виртуально решать прошедшие опенкапы? Куда делась эта фича?
Расскажите кто-нибудь кто знает, как решать сложные задачи H и B. Думаю, это всем интересно.
Ну B вроде совсем простая — у нас есть планарный граф. Скажем, что грани, на которые он разбивает плоскость, — это вершины. При удалении ребра в исходном графе проводим ребро в новом. Теперь ребро было мостом тогда и только тогда, когда при добавлении ребра в новом графе мы проводим ребро внутри одной компоненты связности. Всё, что нужно в задаче, — уметь писать DSU и находить координаты клеток, лежащих по разные стороны от удаляемого ребра.
Спасибо большое. Может быть ты еще знаешь как решать H?
H. Разобьем каждую вершину в несколько, так, чтобы у каждой вершины был ровно один интервал времени, когда в нее можно приходить. Тогда ребро будет, если времена расположены достаточно удачно относительно друг друга.
В этом графе квадрат ребер, но они ведут из вершины в отрезок вершин. При этом для всех вершин кроме первой в отрезке получается оптимальный теоретически возможный результат. Поэтому можно сделать переход в первую отдельно, а во все остальные, доставая из сета те из них, для которых результат еще не оптимальный. Тогда переходов первого типа мало, потому что просто мало. А второго мало, потому что их 1 входящий в каждую вершину.
P.S. Самое главное написать забыл. Переходы имеются ввиду в Дейкстре.
Решение H:
У вас с Пашей отличная командная работа:)
in I why does queue implementation fail with MLE verdict? every object in queue is added and removed only once : \
На сервере явно что-то не так с 64-битной Java. На контесте я сдавал под ней и получал нелогичные TL по задачам F, I и D. F и I я еще пооптимайзил и запихал. А вот D запихать так и не смог, сдал только с 8-ой попытки после переписывания на С++. Сейчас в дорешке ради интереса решил послать те же TL-ные решения, только под 32-битной Java. И по всем ним получил AC.
Я надесь, многоуважаемый Snark прочитает это сообщение и попробует что-нибудь исправить.
речь про еджадж или яндекс? Я просто вообще ловил CE при компиляции 32 джавы на яндексе... Первый раз прям на контесте... Написал вопрос с указанием номера посылки — игнор. Сейчас в дорешке тоже самое, причем и для 6 и для 7 джавы
потестил сам. Один и тот же код taskD:
Решение с сортировкой массива объектов хранящих информацию о концах отрезка (остальная часть решения линейна * O(1) для HashSet).
Мы даже избавились от хэшсета, и все равно ТЛ 11. В дорешке сейчас на ejudge x32 — АС.
Судя по 32битной джаве предполагаю, что сдавали на еджадже. Ради интереса, пошлите ТЛ решения (которые были ТЛ на 64битной джаве еджаджа) на яндекс...
Проверить, к сожалению, не смогу. У меня нет логина для опенкапа на Яндекс, а на дефолтном аккаунте я не вижу ссылок на этот контест или дорешку.
Проблема уже обсуждалась: дело в том, что у 64-битной Java client vm отсутствует (java -client). 32-битная же запускается именно в client vm.
Мне кажется вопрос не в этом. Это понятно, что вердикты между x32 и x64 могут варьироваться между OK, TL, ML.
Из наблюдений Jovfer следует, что тестирующие машины для Яндекс.Контест и старой системы отличаются. Это так? Кажется, что это не совсем честно и правильно. Ведь в этом случае пользователи одной из систем получают преимущество.
А вот
кажется вообще багом конфигурации.
Можно все-таки прояснить, будет ли что-либо делаться с задачей D? (я не очень знаком с процессом). Нужно ли подать аппеляцию? Или мы сами виноваты что в 64х битной джаве отослали решение? Хотя учитывая проблему у других участников с джавой и на Яндекс.Контесте — все вообще кажется очень странным.
В общем хотелось бы каких то разъяснений. Спасибо.
Про то, что 32-битная java из-за наличия client vm работает на многих задачах быстрее, было сообщено в прошлом году (когда и был добавлен компилятор), а также обсуждалось здесь, на форуме Codeforces.
К сожалению, отправка решения не под тем компилятором не является поводом для изменения вердикта.
Я понимаю, но если бы мы решили в Яндекс.Контесте? Все возвращается к вопросу Майка, о том, что между системами существует разница и эта самая разница может давать преимущество. Я не прав? К сожалению не могу проверить вчерашнюю посылку в Яндекс.Контесте пока, чтобы можно было делать какие то выводы.
А разница (пусть и минимальная) неизбежно будет существовать. Более того, решение "на грани" может в одной и той же системе при последовательных посылках давать разные вердикты.
Учитывая, что реально вы участвовали не через Яндекс.Контест, а в ejudge была возможность выбрать правильный компилятор, никаких оснований для пересуживания вашего решения, отправленного в ejudge, нет.
В Яндекс.контесте Ваше последнее решение по задаче D на Java 7 (OpenJDK 64bit) проходит более-менее такое же время, как решения на javac-32 (OracleJDK 32 bit) в ejudge (1.616 на javac-32 на ejudge и 1.9 на Java 7 в Яндекс.контесте). То есть в обеих системах возможность выбрать правильный компилятор и получить OK на Вашем решении была.
Возможно, в описаниях компиляторов при выборе языка на ejudge надо будет добавить "preferred" к "javac-32" и "slow" к "javac"
Минимальная? Судя по сообщению http://codeforces.me/blog/entry/9609#comment-151143 разница на этом конкретно взятом раунде опенкапа — была более чем существенная.
З.Ы. Я не требую зачесть нам эту задачу, просто правды хочется. А то в последнее время олимпиадное (спортивное) программирование превратилось набор знаний по алгоритмам + знание всех известных хаков компиляторов(антисортировка тесты, антихэш тесты и т.д.). Скоро дойдет, что будем думать, в какую версию Java отправить задачу в u40 или в u25, например.
По Вашему решению — 1.62 против 1.9.
Что же касается сообщения выше, то оно изучается и к Вашей ситуации (в которой всё ясно — очевидная ошибка команды) никакого отношения не имеет. И проблема там вовсе не в TL.
Наличие 64-битной java на ejudge для тех случаев, когда решение на ней быстрее (то есть когда замедление из-за использования server vm компенсируется другими преимуществами), является дополнительной возможностью.
На Яндекс.контесте опция "Java 7" также даёт приемлемую скорость.
А можно информацию по времени запуска в 64х битной джаве на Яндекс.Контесте?
Там же вроде ТЛ 5 секунд, т.е. на 32х битной все влетает за 2 секунды и меньше, а на 64х битной — не влезает в 5 секунд?
Решение на Яндекс.Контесте запускалось как "Java 7".
Это значит что на Яндекс.Контесте наше решение отправленное на 64х битной джаве получило бы АС?
Если Java 7 сейчас сконфигурирована как 64-битная, то да.
Upd. Java 7 там действительно 64-битная (OpenJDK). На ejudge стоит OracleJDK u45 для 64 бит (server mode) и OracleJDK u13 для 32-бит (client mode).
То есть, получается, что решай мы на яндекс.контесте, мы бы в одной версии java вердикт получить не смогли бы из-за ошибок конфигурации, а на второй получили бы OK? И несмотря на это вы не хотите зачесть нам решение?
Тем не менее, Вы решали в системе, где выбор компилятора был и где существовал выбор, при котором задача сдаётся.
Так что выбор не того компилятора — исключительно ваша ошибка.
Наличие нескольких компиляторов даёт дополнительные возможности, в то же время оно даёт дополнительные возможности сделать ошибку. В случае с C++ выбор ещё больше (g++ 32-битный, g++ 64-битный, clang). И если решение было отправлено под clang и не прошло, но прошло потом под g++ на Яндекс.Контесте, где clang отсутствует, это не повод засчитывать это решение.
Выбор другой системы решения (не Я.Контест), тоже наш выбор и тоже наша проблема?
как я понимаю, "проблемы индейцев шерифа не волнуют"
Вердикт меняется только в случае какой-то ошибки со стороны жюри (будь то ошибка в задаче или в настройках системы). Поэтому вопрос переформулируется так: если в системе выбор компиляторов больше (и шанс выбрать не тот вариант больше), чьей ошибкой является выбор не того компилятора?
Более того, ситуация эквивалентна следующей: участник случайно отправил правильное решение задачи не под тем компилятором (например,Perl вместо C++), после чего или получил Runtime Error, которая повлияла на итоговое место, или просто не смог отправить задачу правильно, так как всё происходило на 299-й минуте контеста. И вопрос в том, какое решение должно быть принято в этом случае.
Стоп-стоп.
Ситуация не эквивалентна, потому что мы час вылизывали код (т.е. разговоры о 299 минуте контеста здесь совершенно не применимы), чтобы он зашел, а не просто один раз мимо ткнули.
Да, если бы была одна система — edjudje — я склонен согласиться с Вашими аргументами — выбор был, сами виноваты, но у нас было 2 системы, и во второй системе наше решение зашло (про кривую настройки 32х битной джавы на Я.Контесте я вообще молчу (это ли не ошибка со стороны жюри?))
Каким образом настройки 32-битной Java в другой системе повлияли на ситуацию c Вашей задачей во время контеста?
Кстати, на Яндекс.Контесте используется не Oracle JDK, а OpenJDK. Возможно, что дело в этом...
Единственный выход, который я сейчас вижу, и при котором вопрос с пересуживанием будет решён по-другому — пересудить все несданные решения на javac как javac-32, так как название компилятора в системе могло ввести в заблуждение (то есть по умолчанию решение на java сдавали на javac).
Да, это было бы оптимально — перетестировать несданные решения всех команд, использовавших javac. Спасибо.
Каким образом настройки 32-битной Java в другой системе повлияли на ситуацию c Вашей задачей во время контеста?
Они могут коренным образом влять на работу приложения. Начиная от настроек типа Garbage Collector'а и размеров Heap'а до опций всяких сжатых ссылок и прочее. Одна опция -Xint может "загубить" решение на Java. Это все, конечно, из области фантастики :) Моя позиция проста: разные JVM опции реально влияют на работу Java-приложения.
Кстати, на Яндекс.Контесте используется не Oracle JDK, а OpenJDK. Возможно, что дело в этом...
Возможно вы имели в виду Oracle JDK vs. Iced Tea. Поскольку, как известно, начиная с Java-7, разработка Java платформы ведется через open-source проект Open JDK.
Не читаем коммент @ пишем ответ?
Каким образом "настроки типа Garbage Collector'а ..." на серверах Яндекс.Контеста могли повлиять на программы, работающие на ejudge'вских серверах?
Вообще, я не понимаю претензии mysterion. Есть две системы, в каждой есть две джавы. В одной их решение для разных джав выдаёт TL и OK, во второй — CE и OK. Т.е. все претензии сводятся к тому, что на Я.Контесте было бы лучше писать, т.к. там из-за бага для одной из джав выдавался CE. Странное утверждение, ИМХО.
прошу прощения, был взволнован
Не совсем так. На одной системе TL и OK, на другой OK и CE. Почему я акцентирую внимание на "порядке мест слагаемых": мне кажется важным, что на одной системе 64-битная посылка заходит, а на другой — нет. Если Олег Богданович исправляет СЕ на Я.А, то это второй ОК (два из двух на одной из систем), а из вашего сообщения может показаться, что тот же TL
Олег, согласно opencup.ru, на ejudge тестируется, используя Core 2 Quad Q6600/8Mb (2Mb per kernel), 4 Gb RAM под управлением Linux (Fedora Core 17), kernel 2.6.38.8, Java 1.7.0_03. Это правильная информация?
Что используется на Яндекс.Контесте? Видимо, на http://contest.yandex.ru/ информации нет.
А не пора перейти на единую систему? Что мешает полностью перейти на Яндекс.Контест (вроде же он должен прийти на смену ejudge)?
Ой, не надо. Ejudge (IMHO) гораздо удобнее и привычнее.
Вопрос адресован не мне, но...
lperovskaya говорила мне, что на Яндекс.Контесте используется AMD Opteron 6172, другие параметры я не узнавал.
а разве на сервере для скомпилированных решений используется одна и та же версия JVM? Мне казалось логичным, что для компилятора javac-32 используется 32-битная JVM, а для javac-64 используется 64-битная JVM. Получается, что различие не только в компиляторах.
Для javac-32 используется 32-битная Client JVM. Для javac-64 — 64-битная Server JVM (по причине отсутствия Client JVM для 64-битной архитектуры)
А почему для 64-битной Java не используется mixed-mode (C1/C2), который по дефолту запускается?
P.S. Мне вообще не понятно, зачем использовать Server JVM в олимпиадном программировании, если изначально Server JVM нужны для программ, которые рассчитаны на долгую работу (backend какого-то сервиса, например)?
Запуск в 64-битной версии так и происходит по дефолту. При этом запускается server. Кстати, начиная с какой версии эта mixed-mode есть?
Sry for misguiding. Я имел в виду не mixed-mode, а TieredCompilation: совмещение C1 и C2. Чтобы ее включить надо использовать -XX:+TieredCompilation ключ при запуске.
Ее ввели начиная с Java 7.
P.S. Скорее всего если попрофилировать на TL-тестах наше решение и посмотреть, как JIT работает, то будет видно, что в случае Server JVM — JIT-компиляция случилась только в конце или ее вообще не было.
P.P.S. А я правильно понимаю, что решения на Java прогоняются 2 раза, чтобы прогреть JIT, и время берется от второго запуска (где-то такое читал)? Или это мои необоснованные фантазии? :)
Я на 99.9% уверен, что это необоснованные фантазии :) И ИМХО, так делать не надо — мало ли что там внутри у всяких JIT'ов, может, они видят, что исполняется тот же самый детерменированный кусок кода с тем же самым входом, и оптимизируют его сразу выводить ответ.
У вас неправильное представление о том, как скоро заканчивается интерпретируемый режим и быстро наступает режим исполнения байт-кода.
Зачастую те оптимизации, которые проворачивает server mode перевешивают то время, которое тратиться чтобы подготовиться к ним. Я неоднократно видел, что обыкновенный Java-код решений задач под server mode работает значительно быстрее client mode.
Короче, тезис о том, что server mode не нужен для решений задачек не верен.
Более того, как я понимаю в 64-битной jvm уже -server стал поведением по-умолчанию, ибо расходы на него не так велики, а порой он оказывает сильный профит.
К сожалению, однозначно сказать какой из режимов лучше подходит для тестирования решений нельзя. Надо еще поэкспериментировать с Tiered Compilation, может правда неплохо работает.
Я неоднократно видел, что обыкновенный Java-код решений задач под server mode работает значительно быстрее client mode.
Я тоже такое видел. Сегодня тут писалось выше, что конкретно в этой задаче так не получилось...
В целом, я согласен с MikeMirzayanov с тем, что тут боль в том, в каком режиме и с какими JVM опциями надо тестировать решение. Это открытый вопрос.
P.S. btw, посмотрел — оказывается на topcoder'е Java запускают на 32-битной Fedora только в -client режиме. Пруф линк
snarknews, планируется ли какое-то решение этой проблемы?
Мне кажется, все пытаются подойти к решению проблемы не с той стороны. ИМХО, правильный (и не зависящий от языка) подход — наличие решений жюри на всех основных языках (как минимум Java и C++), укладыващегося в ТЛ хотя бы с двухкратным запасом на всех компиляторах (т.е. если есть openjdk java 64, то и на нём должен быть двухкратный запас). При этом решение разумеется должно быть без изувер-хаков вроде ассемблерных вставок или издевательств над java-кодом с целью помочь JIT избавиться от range check'ов.
Да, с таким подходом гораздо тяжелее делать жёсткие ТЛи, но если в задаче тяжело отделить асимптотически правильные решения от неправильных — может, это проблема задачи?
А я все же считаю, что навязывать правила подготовки контестов всем плохо. И если проводится контест на задачах, где в оригинале не требуется java решение, то и для OpenCup его никто писать не будет. Все знают особенности польских контестов, и по названию было понятно, из какой страны авторы. Может лучше пропускать такие контесты, а не кричать потом, что мое решение на java нужно было упихивать. Тем более, что по правилам OpenCup в зачет худший результат все равно не идет.
Кроме того не во всех коллективах авторов есть приверженцы java (а где-то и C++), а когда эти же авторы вынуждены переписывать свой код на java, для формальности, потом им еще приходится слышать "а где тут код на java, это опять ваш C++, так никто не пишет". К чему это все? Я понимаю, что на официальных соревнованиях обязательно нужны перекресты на разрешенных языках, однако подстраиваться под все языки из OpenCup локальные авторы не обязаны, да и не должны.
Конечно никто не обязан подстраиваться, но 1) если авторы напишут решение на джаве — хуже от этого точно не станет, 2) с задачами сторонних контестов иногда можно взять решения команд с контеста на нужном языке и выставить ТЛ по ним.
Лично меня результат на контестах давно уже не интересует, я просто получаю удовольствие от решения интересных задач. Жёсткий ТЛ это удовольствие портит, что особо печально, учитывая что многие задачи в этот раз были действительно интересными. Что бы стало хуже, если бы ТЛи на этом контесте были в 2 раза выше? Лажа с такими ограничениями всё равно бы не зашла, зато куче команд не пришлось бы заниматься упихиванием...
Ага, нам вчера в одной задаче пришлось ответ выводить весь сразу, комбинируя его StringBuilder'ом, иначе не запихивалось.
Про С вопрос актуальный. Я на контесте что-то придумал, с кучей случаев и очень не красивое, а так как всегда было что писать, мы решили, что это мы писать не будем. Как ее решать верно?
Мы решали так. Для каждой клетки таблицы насчитаем, а насколько можно от нее в каждом из четырех направлений "нарастить" треугольную шахматную доску. Например, UpRight[i][j] = 1, если клетка (i, j) имеет с (i + 1, j) или (i, j + 1) одинаковый цвет, или UpRight[i][j] = 1 + min(UpRight[i + 1][j], UpRight[i][j + 1]) в противном случае. Путем "вращения мира" можно добиться того, что первый треугольник ориентирован UpRight. Сделаем бинпоиск по ответу и переберем также цвет угловой клетки. Осталось некоторое множество треугольников, нам нужно определить наличие двух непересекающихся среди них. Для этого заметим, что для каждой ориентации выгодно оставить только "экстремальные" треугольники: с минимальным/максимальным x, y, x + y угловой клетки. После этого все пары кандидатов проверяем честно.
А если для каждого размера треугольника отдельно хранить минимумы и максимумы, то вроде можно и без бинпоиска обойтись.
Видимо, да, но в любом случае, не думаю, что это проще в реализации. Там и так кода получилось не очень-то мало, а линейное решение не требовали.