


Сегодня состоялся основной тур Открытой Всесибирской олимпиады по программированию. На задачах этого же соревнования проходил этап Открытого Кубка.
Зайдя на http://olimpic.nsu.ru/widesiberia/archive/wso14/2013/rus/index.shtml, так и не увидел ссылки на текущие результаты в Новосибирске. Их не было в интернете или я просто не нашел?
Были ли команды, участвующие в Новосибирске, в ранклисте Кубка?
Предлагают здесь обсудить задачи и впечатления от онсайта.







Кто как решал 10? Очень напоминает задачу Hard Life, но если предполагалось подобное сведение — это ж полконтеста кодить...
Что за издевательство с задачей G? Мало того, что её очень тяжело придумать без гугла (и очень легко с гуглом), так там ещё и тесты против хешей в long'ах. Зачем добавлять такие маразматические приколы? Думаю, они уже всем участникам успели надоесть.
А как G нормально решать, "с гуглом"? Интуитивно очевидная идея — будем идти dfs по состояниям "номер строки-длина префикса", переходы — пытаемся приписать любую из входных строк, кроме текущей. Если длина результата меньше длины нашей строки, то переход к более длинному префиксу, иначе рассмотрим суффикс-хвост добавляемой строки, и перейдем во все состояния "новая строка — длина хвоста", у которых префикс совпадает с этим хвостом. Если получилось прийти в состояние, где длина префикса равна длине строки — успех. Можно проще?
Ну и да, WA23 из-за long long хешей — это подло. При том что обычные хеши по одному простому модулю 10^9+7 проходят без всяких проблем)
UPD. Если результат длиннее нашей строки, то нужно так же переходить в состояние "добавляемая строка — длина отрезанного префикса". Иначе WA11. С гуглом я вот уже нашел необходимое и достаточное условие Маркова, но не представляю, как его проверять за разумное время.
Есть теорема, которая вроде даже упоминается в университетских курсах, но её ж фиг вспомнишь...
Эх, всем бы такие хорошие университетские курсы!:)
На самом деле было так.
Автор задачи послушал про теорему Маркова на лекции и предложил задачу. Потом написал решение (каноническое из теоремы) и сделал тесты. Потом подоспело второе решение, которое оказалось быстрее и проще. Написали ещё парочку решений, подняли ограничения и перегенерили тесты.
Насчёт антихеш-тестов — это теперь холиварная тема. Лично я считаю, что в ACM-туре так делать нехорошо, и антихеш-тесты являются уделом соревнований с возможностью хачить. Однако последнее время (в основном благодаря Codeforces) народ в подобных соревнованиях участвует всё больше и больше. Антихеш-тесты стали "общеизвестным фактом" и "нормальным явлением". Теперь многие добавляют их в задачи ACM-туров и считают, что это нормально.
Ну те, кто считают это нормальным, должны тогда добавлять анти-Java-sort и анти-hashtable тесты, и заодно тесты против рандомизированных алгоритмов с популярными randseed'ами, против хешей по популярным модулям (выше пишут, что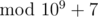 проходило), ... (список можно продолжать бесконечно). Надо либо быть последовательными и добавлять все трололо-тесты, либо не издеваться над участниками.
проходило), ... (список можно продолжать бесконечно). Надо либо быть последовательными и добавлять все трололо-тесты, либо не издеваться над участниками.
А какие randseed'ы наиболее популярны?
Из того что я видел, самое популярное: 0xdead, 0xbeef, 0xdeadbeef, 239, 239017, 42, 0, time(0). Наверняка можно накопать гораздо больше :)
Я в коде KADR как-то увидел рандсид 31415 и именно с ним у меня зашло. Теперь сам использую.
Состоящие из 4 и 7. Например randseed'ы 47, 774 — популярны, а 54 и 100 — нет.
а задача — боян
А ты умеешь «ломать» полиномиальный хэш по модулю 109 + 7 сразу для всех умножителей? Я так умею только для модулей, равных степени двойки.
Ну из общей теории по простому модулю нельзя построить пару строк, которая будет ломать хэш. Хотя бы потому, что у полинома степени n над полем не более n корней.
Верное наблюдение. Но это для двух сток. Когда попарно сравниваются n строк, получается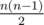 уравнений. Тем не менее, делать тесты против популярных простых модулей, если и возможно (а это зависит от задачи), то сложнее, чем взять известную последовательность Морса – Туэ.
уравнений. Тем не менее, делать тесты против популярных простых модулей, если и возможно (а это зависит от задачи), то сложнее, чем взять известную последовательность Морса – Туэ.
Так вроде просто "ломается" для фиксированных модуля и множителя, например, так.
Я выбираю множитель случайно, а модуль фиксированно. Такое врядли можно сходу сломать.
Ок, при составлении тестов в своих задачах на строки я обязательно буду добавлять по одному тесту против каждого из 109 + 6 умножителей:)
В 10 задаче сделаем бинпоиск по ответу. Пусть мы хотим проверить, можно ли получить ответ <= X. Тогда нам нужно найти многоугольник у которого number_of_people / area < X, что эквивалентно number_of_people — X * area < 0. Построим граф, в котором ребра — это стены, а вес каждого ребра (i, j) — это people[i] + people[(i, j)] — X * vect(point[j], point[i]). Если мы возьмем какой-то цикл, то сумма векторных произведений как раз даст в сумме площадь соответствующего многоугольника. Тогда если в этом графе есть отрицательный цикл, то он и будет искомым многоугольником. Осталось заметить, что если мы многоугольник обойдем не в том направлении и у нас площадь выйдет отрицательной, то вес цикла будет положительным и мы его автоматически отбросим.
В G вроде сразу ясно, что нужно начать строить искомые строки с двух разных строк из инпута, а потом всегда нужно дописывать строку из инпута к более короткой из двух строк. Если в итоге мы получили строки одинаковой длины, то ответ "YES". И доказывать это вроде легко. Или там в доказательстве есть какие-то подводные камни и для их обхода нужно использовать приведенную теорему?
А, понял ваше решение. Я идиот — надо внимательнее читать условие, там же не только суммарная длина строк ограничена, но и их количество :(
Переспрошу, потому что моя реализация схожей идеи упорно ловит ТЛ. Вроде выше тоже самое сформулировано, но вдруг я где-то в мелочи ошибаюсь и получаю лишнюю константу или еще что-то. Есть текущая строка с индексом
indиз инпута. Есть позицияposв ней, префикс до которой мы уже составили. С помощью инпутовских строк, которые совпадают с оставшимся суффиксом (или его частью) переходим либо в состояние с текущим индексом, но сдвинутымposна длину какой-то совпавшей строки, либо в строку с другим индексом, префикс который совпал с суффиксом текущей строкиindи новой позицией равной длине старого "активного" суффикса. Т.е.("abc",1) -> "b" -> ("abc",2)или("abc",1)->"bcd"->("bcd",2). Реализация в лоб этой идеи, естественно с отсечением по уже пройденным состояниям должна получать ТЛ или я плохо написал?UPD: код
Так нужно подстроки за О(1) сравнивать, например, при помощи хешей.
чтобы было о(1) получается нужен предподсчет хешей. Не для всех же подстрок его выполнять? Или в каждом состоянии за линию вычислить массив хешей на префиксах текущего суффикса, а для исходных строк предпосчитать заранее хеши префиксов?
Чтобы сравнивать хэши любых подстрок двух строк:
1) предподсчитаем частичные суммы полиномиальных хэшей на исходных двух строках
2) сравним размеры подстрок, если не равны — подстроки не равны, иначе идём дальше
3) берём напрямую частичные суммы для подстрок первой и второй строки:
h1 = hash1[last1] - hash1[first1]
h2 = hash2[last2] - hash2[first2]
4) уравниваем степени, домножая хэш подстроки, индекс начала которой раньше, на множилку в степени разности между индексами начал двух подстрок
5) сравниваем напрямую получившиеся значения
Подробнее почитать можно, например, на e-maxx.
просьба объяснить минус. Есть ответ про полиномиальные хеши, которые действительно достаточно известны, есть на емаксе и про которые спрашивать не очень хорошо. Однако не знаю у кого как, у меня они в этой задаче падают в районе 10-20 теста с ВА (в зависимости от коэффициента, типа итп). Поэтому описал идею, которая позволяет использовать произвольный хеш, но что-то есть большая вероятность уже МЛ
Попробуйте брать по модулю 109 + 7, вместо того чтобы считать в long'ах/int'ах с переполнением. Собственно, про это был самый первый коммент в этом thread'е :) После эпичного поста многие авторы задач считают своим долгом потроллить участников и добавить этот тест.
Естественно, прежде чем переспрашивать про хеши попробовал убрать переполненние и считать по модулю :) так и не зашло пока.
Ну тогда покажите код — наверное, у вас там бага.
код ва11
Там странное значение коэффициента, но пробовал разные. Заранее спасибо за просмотр кода.
Нуу, тут проблем несколько. Во-первых, у вас переполнения при вычислении хешей — произведение двух чисел до 109 + 7 в int не влезает. Далее, в строке 97 вы берёте разность хешей, и не берёте её по модулю (ну и во всех фрагментах, скопипасченных из этого).
В остальном вроде всё правильно, хоть и не самый чистый код.
Спасибо. По поводу переполненния на умножении — был там лонг одно время, не спасало. А вот вычитание из виду упустил, спасибо. Код переделанный из решения без хеша, поэтому грязноват, каюсь. Много чего пережил. Даже бинпоиск по словарю.
все тот же ВА11 однако
Не, ну как работает оператор взатия по модулю в любимом языке — надо знать. В таком виде — Accepted ;)
Тьфу. Пора отходить от экрана. Прочитал Ваше замечание про вычитание — мысленно перестроил, учитывая возможны отрицательный мод (со времен ЕГЭ и школьного Паскаля помнил, друзья теряли баллы, приходилось объяснять за что). А тут пока на планшете редактировал код — сам попался.
UPD: количество посылок таково, что Яндекс больше не принимал :) Еще раз спасибо за тыканье носом в детские ошибки.
Илья, мы на четвертьфинале тоже добавляли анти-хеш тесты. Я тоже люблю надеяться на удачу и пихать лажу) Но если есть тест, где решение работает неправильно и жюри он известен — то почему такие решения должны заходить? Напиши по одному или двум простым модулям. Если это уже ТЛ, то либо жюри перегнуло планку ТЛ (что редко и они ни разу не правы) либо есть более эффективные решения, которые либо работают абсолютно правильно, либо жюри не смогло завалить (например тот же хеш по простому неизвестному жюри модулю). Блин по мне это тоже самое что ныть, что завалили твою хорошую жадность в общем случае не верную)
Для любых хешей есть тест, где решение работает неправильно (и жюри известно, как его сгенерить). Я не понимаю, чем многим авторам задач не угодил модуль 2k. Да, он популярен, и против него есть красивая конструкция, но есть много других популярных модулей, которые почему-то никто не валит. Если уж добавлять в задачу геморроя — то надо делать это основательно :)
Это не относится к теме, но на практике для джавы жюри очень часто перегибает планку ТЛ.
Брать по модулю степени двойки на современном процессоре быстрее, чем по любому другому модулю, и способов взять по модулю тоже больше (
h % (1 << k)илиh & ((1 << k) - 1), вычисления с переполнением). Это преимущество такого класса решений, которое обеспечивает им особое внимание от составителей тестов.Заваливать же одни конкретные простые модули и не заваливать другие — уже может оказаться не очень честной идеей, так как может ставить в неравные условия различные школы. Преимущества степени двойки над простым модулем, когда они есть, универсальны и общеупотребительны, в отличие от использования конкретного простого модуля типа 109 + 7.
Илья, у конструкции для 2k и тестов против конкретных хешей разная мотивация.
Хеш — это пара (модуль, точка в полиноме). Ты действительно для любой пары можешь подобрать тест, на котором решение сломается, но подобные тесты будут ломать исключительно те решения, для которых жюри их сгенерит, грубо говоря, нужно по тесту на решение. Подобные тесты символизируют лишь то, что рандомизированный алгоритм в относительно малом числе случаев даёт неправильный ответ и то, что жюри при желании может подобрать контртест.
Отличие конструкции для модуля 2k в том, что он вырезает гораздо больше решений, а именно все, независмо от выбора точки в полиноме. То есть ключевая идея этого теста, в отличие от тестов против конкретных хешей, заключается в том, что неасимптотическая оптимизация, берущаяся из скорости выполнения битовых операций в процессоре, принципиально неверна.
И да, если уж быть последовательными, то надо добавлять тесты против сортировки и hashmap в java, против стандартной библиотеки C#, и много чего ещё. Никто это не делает, и что-то мне подсказывает, что на анти-2^k-хеши через несколько лет тоже забьют. Но сейчас эта идея популярна, и многие авторы идут на поводу у моды...
Результаты всесиба на момент заморозки
Команды со Всесиба в таблице Гран-При Сибири и Дальнего Востока присутствовали (в размороженной они представлены с результатами на 4:00).
В Division 2 были задачи с FarEastern Subregional 2013 (прошёл 2 ноября).
Спасибо, ожидал увидеть эти данные на офиц. сайте доступными по ходу соревнования.
Я не знаю всех тонкостей, но окончательные результаты, вроде, будут только завтра. Т.е. даже участники (как я понимаю, ибо пароль не у меня, а у сокомандника) не знают размороженной таблицы.
Я не могу ничего сказать о технической реализации этого дела, но видимо организаторы не смогли сделать (или не захотели) сделать монитор вне системы тестирования.
Про окончательные результаты всё понятно. Вопрос о текущих результатах первых 4-х часов соренования.
Как решалась задача Н? Писал жадность, но дальше 9-го теста дойти не смог.
9 тест — это одна стопка вида 1010, где 1 — это черно-белая фотография, а 0 — цветная. Здесь ответ -1. Вообще решалась так: посчитаем количество групп подряд идущих одинаковых фотографий. Пусть это количество равно К. Тогда если у нас где-то встречается (сверху вниз) группа черно-белых, а затем группа цветных, то ответ К-1, иначе ответ К. Доказать можно конструктивно, рассмотрев несколько случаев.
Ну если 9-й тест такой, как ты написал, то у меня работает. Мое решение очень похожее, может где-то набажил. Спасибо.
У нас ва9, но на стопке 1010 выводится -1.
На самом деле, там не обязательно это. Мы в начале выводили -1 для стопки вида 101 и получили ВА9, а потом поняли что -1 будет только для стопки 1010. Может здесь наоборот, тест 101, а у вас выводит -1.
9 тест вида с bw c, 10 тест вида bw c bw
Ну у меня они проходят, а все равно выдает ВА 9
В обеих тестах ответ 2 — так, на всякий случай)
Может быть, ты одинаковые как-то криво сжал? В 9 тесте точно n=1, и после сжимания групп одинакового цвета точно получается то, что я написал выше — установлено методом проб и ошибок.
Тестирование с тупым решением сильно помогло — по ифу на каждый частный случай ><
Я, конечно, понимаю, что это будет интересно скорее участникам очного тура, но предлагаю также поделиться стратегиями с тура первой номинации.
Для остальных: кроме результатов итогового турнира (в ужасном виде, правда), по ссылке также есть (в папке materials) условие первого тура и все, что нужно было для создания решений.
Я подумал, что этот топик лучше оставить для обсуждения ACM-тура и написал про первый тур в отдельную тему.
Как решалась D из div2?
Сдал бинпоиском по ответу. Если количество рулонов фиксированно, то легко посчитать, сколько полос какого типа должны приходиться на каждый рулон. Дальше ясно.
Я тернарником подбирал соотношение коротких и длинных полос в одном рулоне. Стабильно получал ВА14) Интересно, что же там за тест....
расскажите, плиз, как решать F про скобки
Заведем стек из блоков открывающихся скобок. stack В xxx будем хранить количество открывающихся скобок каждого типа. Если идет блок закрывающихся скобок ты пытаемся закрыть скобки из вершины стека. Если не можем обнулить вершину или текущий закрывающийся блок ответ 0.
вот тест может наведет на мысли если что не ясно
(([)[)]]
P.S. Когда я писал cin >> string; моя программа TLилась. после замены на scanf, все прошло, было очень неприятно.
У меня на контесте был ТЛ11. Поубирал лишние создания векторов, stack заменил на самописный на массиве — зашло. Теперь отправляю то же решение в дорешку — ТЛ11. Пойду дальше оптимизировать)
Upd. победный костыль — сначала проверим, что строка теоретически может быть хорошей, считая баланс скобок без учета их типа. Только если эту проверку строка прошла — начинаем решать со стеком. Теперь и в дорешке зашло.
А какое чтение было? Просто странно. Решение же за линию. На джаве с стандартным стеком от собственного класса (что как правило медленнее, чем 4 стека интов) зашло с 3х запасом (0,61с из 2с). Ну только чтение разве что быстрое.
На контесте getline. В дорешке отправлял с cin и с getline.
а если исходное решение (с STL стеком) пропатчить scanf? Тоже ТЛ? у нас просто вторая команда тоже сдавала на плюсах, и тоже был ТЛ. Все-таки очень похоже на чтение. Ну чистая же линия, даже раскрутка стека не даст серьезной константы.
По-умолчанию стандартный C++ stack имеет под собой deque, который в ряде случаев может (и совсем не стесняется) работать заметно медленнее. Можно это исправить путём замены параметра шаблона контейнера или просто используя vector как стэк (у него есть операции push_back(), pop_back(), empty() и back()).
Практически полностью тормознутость C++-style ввода/вывода (cin/cout и компания) лечится строкой "std::ios_base::sync_with_stdio(false);" в самом начале функции main(). Стоит отметить, что после неё нельзя пользоваться C-style вводом/выводом (scanf, printf и т.д.).
Причина минусов конструктивна? Я глуп, возможно — нужно объяснение.
Я обещал выложить: Та самая статья с решением задачи "Коварный изоморфизм" через прямое применение леммы Бернсайда.
UPD: Наверное, зря я на неё сослался. Там всё написано очень математическим языком (через производящие ряды) и по большей части состоит из ссылок на некие "известные" математические результаты.
Как решать 4-ую адекватно (без вольфрама)?
Напрямую через OEIS?))
Ну а вообще, статья есть комментарием выше. Хотя понять там, видимо, сложно.
А как решать I из Div.2?
Там было настолько вырвиглазное условие и кривой 2-ой тест (не совпадали длины строк a и b), что чтобы понять, что там на самом деле нужно сделать, мне потребовалось аж 7 неверных попыток :). Еще 7 попыток я пропихивал динамику за O(N^4) на Java, но так и не смог. Как ее решать лучше чем за O(N^4)?
А в чем была проблема? O(N ^ 4) спокойно проходит, нужно было лишь подогнать под ML. В Java наверное есть аналог vector'у, с помощью него оптимизим память до ~48 MB и все.
А как решать C из Div.2?
Сначала пробегаем по строке от 0-го до (М — 1)-го символа и заводим в мап вида <string, int>, в нем храним количества вхождений всех подстрок длинны L для нашей подстроке от 0 до (M — 1), так же заводим второй мап в вида <int, int>, в котором мы ведем подсчет того сколько раз повторялось каждое количество вхождений. (Не знаю как написать это лучше, но возможно яснее станет с примером M = 9 L = 2 ololoasaslol, as, ol и lo встречается два раза и oa один, значит во втором мапе будет <2, 3>, <1, 1>). И при этом находим максимальное количество вхождений строки длинны L для нашей подстроки. И теперь бежим по всей строке с шагом в 1 и очевидно, что мы будем терять и получать только одну новую подстроку, и в любом случае максимальное количество вхождений либо увеличится на один либо уменьшится на один, или же останется неизменным, я думаю, вполне очевидно как обновлять эту структуру на каждом следующем шаге.
Как решать Е? Почему не проходил обычный перебор с заменой нулей на единицы?
250000000 быстро работает?
Поясните за (I) Геометрию пожалуйста. Как ее решать.
Спасибо авторам за интересный и качественно подготовленный раунд!
Качественно подготовленный? Вы видели условия на английском? Куча опечаток и урезанность по сравнению с русским вариантом. В задаче С нет ограничения на W, поэтому я думал, что оно до 10000. В H не сказано, в каком порядке в инпуте даются фотографии. А задачи интересные, да
А разве оно не до 10000? Правда, на наше решение это не влияло, у нас жадник, но я знаю людей, у которых рюкзак зашел.
Открытый Кубок уже не в первый раз дает мне понять, что у меня проблемы с жадностью)
А можно подробней про жадник?
Вот у нас есть корневое дерево, в котором изначально у каждой вершины вес 1. Давайте посмотрим на вершину, у которой все дети — листки. Всех ее детей, кроме тех, которых удастся пихнуть к ней в один список в раскрытом виде, придется описывать отдельным списком. Значит к ней нужно пихнуть как можно больше, то есть посортить по весу, и брать в порядке возрастания, пока можем. Потом пересчитали для этой вершины вес; она стала листком; вернемся к первому шагу.
Более строгое доказательство:
17:19:00 Нияз: блин, у Гены в С тоже жадность
У нас с ней прикол вышел. В блокнотике от Parallels была табличка, куда можно записывать соображения по задачам. Так вот один в нее взял и написал "жадность", почему типа фиг знает, не оставлять же клетку пустой. Потом неожиданно встряли на шестеренках, про эту забыли. SirNickolas читал с конца, дошел до нее, офигел от надписи "жадность", но мы были заняты, так что решил поверить. Написал, accepted.
Блокнотик-то был от СКБ Контур :)
Контест хорош, жюри молодцы. Вероятно, английскими текстами занимались не они.
Мне кажется довольно странным наличие на этапе Открытого Кубка задачи на формулу из OEIS: http://oeis.org/A001372/b001372.txt Вроде, использование интернета запрещено, но вводить в такое искушение участников кажется излишним. Все ли решившие эту задачу сдали ее без помощи энциклопедии?
Обычно же (если очень хочется дать такую задачу) всегда можно чуток обобщить задачу, чтобы она перестала быть формулой из энциклопедии: здесь, вероятно, можно было ввести ограничения на степень входа в вершину или ввести ограничение на кол-во истоков — таких u, что не существует такого v, что φ(v) = u, длины циклов. Да мало ли что еще можно придумать, чтобы исключить простой поиск формулы в энциклопедии.
Еще забавно, что задача совпадает с той, я давал на далеких зимних сборах в Петрозаводске почти 10 лет назад (ограничения были поменьше, но авторское решение использовало похожие идеи).
На онсайте достаточно долгое время (точно не меньше часа, может, даже два) была проблема с задачей 6 (про скобки). У жюри было неправильное решение (и, соответственно, неправильный ответ на тест). После того, как задачу не сдали мы, Москва, ИТМО, зато сдали ПетрГУ и еще кто-то совсем странный, жюри-таки проверило тест руками.
А там можно было написать наивное решение и, убедившись что оно дает только OK или TL, не попасть в такую ситуацию? Если да, то это большая недоработка авторов :(
Вроде бы можно было, так как Слава стрессил свое решение, когда схватил ВА.
Мы честно поискали баги, не нашли, посмотрели на монитор, решили, что баги у жюри и их когда-нибудь найдут. Так и произошло. То есть с этой задачей для нас было не фатально, но неприятно.
Спасибо за то, что опустил, назвав нас "совсем странными" :)
Кроме того, почти эквивалентная задача была в одном из раундов Facebook HackerCup 2013
Почти эквивалентная она только в том, что там тоже были скобочки. В остальном задачи разные и решались по разному. HackerCup решался 2 счетчиками сколько должны закрыть и сколько можем закрыть.
Я имел ввиду задачу про неизоморфные функции и задачу про неизоморфные деревья из 3 раунда HackerCup.
Где можно написать виртуальный контест на этих задачах?
Если у вас есть доступ к олимпиаде под названием что-то типа "Очный тур Всесибирской олимпиады" в системе на olimpic.nsu.ru, то возможно там. В любом случае, если вас устроит подорешивать, то там же в олимпиаде "Тренировки" есть соответствующий тур.
Насчет других мест я не могу сказать ничего.
Какое нормальное решение у І из второго дивизиона? Я написал прекальк всех ответов за О(N^4) и дальше отвечал на запросы за О(1) (просто брал нужный мне ответ из массива), оно у меня в дорешке довольно стабильно получало TL16, упихивал где-то полчаса, пока не зашло с солидным набором костылей. Это должно нормально проходить? Или есть более быстрое решение?
Я пропихивал ее на контесте на Java за O(N^4). На С++ точно такой же код зашел без всяких проблем. Костылей там и не было, разве что можно считать динамическое создание массива костылем. Потом я из принципа запихал ее и на Java. Правда там пришлось уже поизвращаться, сделав из 4-х мерного массива — двумерный и парочку тонких вещей, чисто для Java.
Мне кажется тут ничего лучше и не придумаешь. Просто автор решил компенсировать безыдейность задачи жесткими ограничениями и дурацким условием.
Any hints concerning B div2?