


В этой задаче нужно было догадаться, что существует только 3 корректные тройки:
1) 1, 2, 4
2) 1, 2, 6
3) 1, 3, 6
Будем жадно набирать их пока получается. Если остались какие то неиспользованные числа (в том числе 5 и 7, которые очевидно сразу являются плохими), то выведем -1. Иначе выведем найденный ответ.
Эта задача решается жадно. Будем всегда двигаться только по направлению от s до f. Причем, если в данный момент можно совершить действие, обязательно будем его совершать. Иначе не будем передавать записку соседу и оставим ее у себя (такой ход можно делать в любой ситуации). Очевидно, что такой подход приводит к правильному решению, остается его аккуратно реализовать.
В задаче нужно было аккуратно выписать формулу. Оптимальное решение укладывает шарики по два в ряд, пока это возможно. А потом сверху кладет еще один шарик, если это возможно. Основная хитрость и сложность была именно в последнем шаге.
В комментариях к посту были описаны формулы, как узнать, уместится ли в самом конце один шарик (в самую середину). А также был приведен красивый рисунок, который хорошо иллюстрирует ситуацию .
В этой задаче можно было как считать количество хороших расстановок, так и из общего числа вычесть плохие расстановки. В любом из решений нужно было уметь считать динамику по маскам, состояние (j, mask) — j — номер текущего полностью заполненного столбца, mask — маска того, что находится в последнем столбце (также этот прием называет динамикой по профилю). Это по сути известная задача о паркете (замощения поля доминошками). Как решать классическую задачу о паркете, можно узнать на известном сайте e-maxx.ru.
Чтобы получить само решение задачи я поступал так. Пробовал к клетке с кружочком приписывать с четырех сторох доминошку, после этого все три клетки закрашивал в черный цвет и считал общее количество способов. Однако, чтобы не учитывать один ответ несколько раз, нужно использовать формулу включения исключения для этих четырех направлений. Это также известный прием, который позволяет правильно считать ответ для многих задач и не учитывать один ответ несколько раз.
Задачу можно было решать несколькими методами. Самый простой из них — корневая оптимизация. Разобьем запросы на sqrt(m) блоков. Каждый блок будем обрабатывать отдельно. Перед тем как обработать блок одним обходом в ширину посчитаем кратчайшие расстояния от красных вершин до всех остальных. Далее, чтобы выполнить запрос на вывод ответа из текущего блока нужно взять значение полученное обходом в ширину и обновить его расстояниями до красных вершин из текущего блока, которые покрасились до текущего запроса.
Решение получается очень простым. Каждые sqrt(m) запросов запускаем обычный поиск в ширину и запоминаем для каждой вершины значение d[v] — кратчайшее расстояние от нее, до ближайшей красной. После этого, чтобы ответить на запрос типа 2, нужно взять min(d[v], dist(v, u)), где u — каждая новая красная вершина, которая стала красной именно в этом блоке длины sqrt(m).
Расстояния между вершинами dist(u, v) на дереве можно было считать, используя предпосчет для lca.







В некоторой степени альтернативное решение к С — отдельно просчитать, сколько мы сможем вложить в шкаф шаров, если будем складывать их только в два ряда:
и сколько мы можем вложить, если один ставим в самом верху:
После этого выводим максимальное из этих чисел.
Не могли бы вы разъяснить свои формулы?
Могу. Итак, первая формула. Достаточно легко заметить, что если вложить в самый верх шкафа два шарика, их центры будут находиться на линии перехода между прямой и полукруглой частями шкафа. Значит, на распололожение шаров по два нам будет доступна высота:
h + r/2;Поделим её на r с округлением в меньшую сторону, чтобы узнать, сколько шаров влезло бы в прямоугольный шкаф с такой высотой.
(h + r/2) / r;Здесь нам приходится делить целочисленное r на 2. Но мне это не очень нравится и поэтому я домножаю числитель и знаменатель на 2, чтобы было возможно оставить ответ в целых числах.
(2h + r) / 2r;Всё, что нам остаётся сделать, чтобы получить значение ans1 — это домножить полученное значение на 2, так как мы кладём по 2 шарика.
Теперь вторая формула. Располагаем один шарик в самом верху шкафа по центру. Это будет выглядеть примерно так: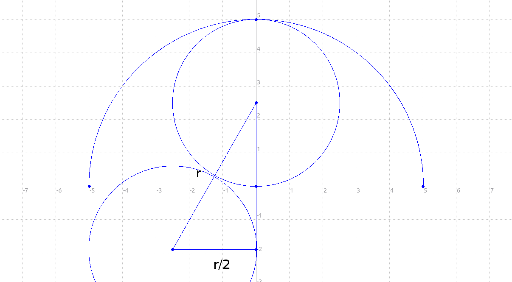 По теореме Пифагора высота этого треугольника равна:
По теореме Пифагора высота этого треугольника равна:
sqrt(r^2-(r/2)^2) = sqrt((3/4)r^2) = (sqrt(3)/2) * r;Отсюда выходит, что на вставку оставшихся шаров у нас будет:
(h + r/2 - (sqrt(3)/2) * r + r/2) = (h + r - (sqrt(3)/2) * r);(Чтобы было понятнее, как получается числитель, скажу, что мы сначала находим высоту центра верхнего шарика от пола:
h + r/2, потом находим высоту центра нижнего шарика:h + r/2 - (sqrt(3)/2)rи, наконец, находим высоту верхней точки этого шарика, вновь прибавляя r/2:h + r/2 - (sqrt(3)/2)r + r/2)И снова целочисленно поделим эту высоту на r, чтобы узнать, сколько мы сможем вместить шаров (с округлением в меньшую сторону, естественно).
Как и в прошлом случае, чтобы избежать мороки с делением целого r на 2, мы умножаем числитель и знаменатель на 2 и выносим r за скобки в числителе и получаем:
(2h + r (2 - sqrt(3) ) ) / 2r;В ответе у нас уже изначально есть 1 шарик и, так как дальше мы кладём по 2 шарика, нам остаётся, как и в первой формуле, лишь домножить полученную формулу на 2 и прибавить результат к ответу.
"Пробывал к клетке с кружочком..." исправьте на "Пробовал..."
Из-за слабых тестов E можно было решать "втупую" (запускать bfs после каждой перекраски).
Вот решение, прошедшее все тесты: link
А вот — генератор, который валит такое решение: link
Получается граф — "бамбук", который приходится слишком много раз обходить BFSом
У нас был похожий тест, но в нем было мало запросов на вывод. Видимо, из-за этого Ваше решение работает быстро. Наша ошибка. Большое спасибо за замечание.
Помогите, пожалуйста. Не понимаю, как надо принимать данные через стандартный вход. На своем компе запускаю, в консоли ввожу числа "5 4", жму enter, ввожу следующую пару. Всё работает. А тут runtime error
Ввод:
Вывод:
13-ый символ считался — это заметно по сообщению. А вообще это извращение — читать вот таким образом с помощью System.in.
А почему именно 13-ый? А каким способом не извращение?
Перевод строки под виндой имеет вид
0x0D 0x0A. К тому жетак что тут очевидно все.
BufferedReader + StringTokenizer например, работает быстро, писать удобно.
Can someone please explain problem D in more detail, I am not able to understand anything from what is posted.
Thanks
Solution is simple. let me explain it with a examples:
suppose we have filled all the empty blocks from column 0....i-1 and on ith column we have filled some of the empty blocks which is stored using mask 0,1,...,7
suppose if mask is currently 0 and i=2, so configuration could be something like this.
blocks with A are already filled.
now we have two options, we might use some vertical block or not:
now we are almost ready with solution and need to check while putting block if that box was empty earlier and which we put block near 0, we need to note this also.
I think, you should be able to understand my code now.
Could you please post the link to your solution.
I got the algorithm but I am lacking clarity over some points like considering the state (i,3), How does one keep track of whether a single vertical block was placed or 2 horizontal blocks covering the squares were placed.
Anyways, thanks for your explanation.
solution: http://codeforces.me/contest/342/submission/4424666
it does not matter whether it was vertical block or 2 horizontal block. (i,3) tells that all the blocks in first i-1 columns are filled and in this column there is only last row left to be filled.
.d.
Assume that you have the distances from vertex with index 1 to every vertex u in a vector d[].
Define lca(x, y) the lowest common ancestor for vertex x and y. You must find out the distance from v to u.
The result is d[u] + d[v] — 2 * lca(u, v) because you add twice the distance from vertex 1 to lca(u, v) (that's where the 2 roads intersects). You can draw a tree on a paper and and work with some examples, it will be clearer.
Could you please tell me the complexity of the Problem E?
Here is my solution: http://codeforces.me/contest/342/submission/4509629 The complexity seems to be O((n+m)*sqrt(m)). But it still gets TLE.
O(n*sqrt(m)*log(n))
\begin{equation}m \cdot\sqrt{m}\cdot\log_2{(n)}\end{equation}
You can precalculate the lca of nodes in Mlogn
In E problem , there isn't any boundary case like chain. Then O(N*N) solution can get AC.
did u code in cpp?
I don’t even remember what I had for dinner last night and you’re here asking me about a code I wrote 6 years ago. That’s like a lot of months :)
That can be answered with what language u used to code with... But anyway you have a point... and I got the ans after stalking your profile... Thanks
Any online solutions for problem E ? Or different solutions to E?
My solution uses Heavy-light decomposition and segment trees. Complexity is O(N log^2 N). http://codeforces.me/contest/342/submission/6999318
Could you explain your idea ?
very good. It was really helpful.
We can achieve O(NlogN) if we store each "heavy chains" in separate segment trees. For each operation, all queries and updates, except the beginning one, are on the whole chain, and only takes O(1). Therefore, each operation takes O(logN)*O(1)+O(1)*O(logN)=O(logN)
My solution (it doesn't run faster in practice though)
in problem E, the complexity must be O(N * sqrtN * logN) ... log N because of the LCA implementation it doesn't pass ! how did you handle this??!!
in problem E, the complexity is O(N * sqrtN * logN).... logN because of the LCA part it doesn't pass the time
how did you handle this !!?
You can precalculate the lca of nodes in Mlogn
oh 7 years to get an answer...that was really too fast! :D
Что-то мне подсказывает, что самое простое решение на 342E — Ксюша и дерево — центроидная декомпозиция дерева.
Подскажите пожалуйста, где можно почитать о центроидной декомпозиции дерева)
1 2
Спасибо огромное :)
Такой вопрос : в конспекте ЗКШ в певром алгоритме построения в 17 строке написано dfs2 (v, size , center , v), разве оне не перейдет сам в себя? Я правильно понимаю, что там должно быть dfs2 (x, size , center , v) ?
Да, опечатка.
Deleted
For problem 342E - Xenia and Tree, I came across a centroid decomposition solution 23224047. I have gone through the solution, but I am not able to convince myself about the correctness of the algorithm and the reason as to why query method is correct(or works). Please help!
PS: HolkinPV, can you please help?
I'm a bit late but the solution is explained here.
How to solve Div1,C if we have to return the maximum distance to any red node instead of min distance...?
"Distance between two nodes dist(u, v) can be got using preprocessing for lca." - Xenia and Tree
Can anyone explain me how to do it?
Notice that
dist(u, v) = dist(root, u) + dist(root, v) - 2 * dist(root, l), where l is the LCA of u and v1) Use a DFS to find the distance from node 1 (the root) to every other node. Let
rootDist[n]by the distance from node 1 to node n. The DFS should also find the parent of each node, and the depth of each node from the root. Letparent[n]be the parent of node n anddepth[n]be the depth of node n.Example DFS code:
2) Build a sparse table.
sparse[u][i]stores the 2**i-th parent of u, or-1if that parent doesn't exist. Note thatsparse[u][0] = parent[n]. The sparse table can be built by:3) To query the lca of u and v, we do the following steps:
Here is the code for the query:
And finally, to put it all together, to query distance
Building the LCA sparse table takes
O(n log n)time while querying takesO(log n)time(I wrote this from memory; please tell me if there are any mistakes or if any part is confusing)
Source/Additional reading
Thanks for your help. You explained very well.
How to do this - Calculate minimum distances from every node to the closest red node using bfs.
Store all nodes which are currently red in a vector redlist. Create an queue bfslist for bfs, and create a array
dist[v] = Distance from v to the nearest red node, 0 if v is itself redand initialize an empty queue. Now for all red vertices v, letdist[v] = 0and push all the neighbours u of the red vertices which are not red into this queue, and for all such u, letdist[u] = 1, isdiscovered[u] = 1. Now it's just regular bfs: while the queue is nonempty, pop the first elementwfrom the queue, and add all the neighboursyofwnot already discovered to the queue, and letdist[y] = dist[w] +1, isdiscovered[y] = 1. Here's a code implementing it:Hi, can anyone please help me debug this code for Problem E.
https://codeforces.me/contest/342/submission/39819558
It has been days and I've not been able to find the error.
I used 'Centroid Decomposition'.
Thanks in Advance!
In problem Div2 E, can someone share the code implementing the sqrt optimization trick. Are there any resources for this technique ? In what all cases can this technique be applied ?
https://pastebin.com/cCYBLvjs
https://codeforces.me/contest/342/submission/75643716
For Div2 C, what comments?
Can somebody help me with problems 342E. Here's my source code: https://codeforces.me/problemset/submission/342/157723527
I still don't know why I got TLE. Thanks so much!!
...