


There was a problem 1400E - Очистите мультимножество in Educational Codeforces Round 94 (рейтинговый для Див. 2) (yesterday's contest) and it got difficulty 2200.
Why is it strange? It wouldn't be, IF...
Get look at this 448C - Про покраску забора. Yeah, these problems are same! In fact, even editorials for them are same.
As you've already guessed difficulties are different. Actually 448C - Про покраску забора got only 1900!
It looks like that such a huge difference is a result of their positions in problemset (E and C exactly).
Of course, this situation is rare enough to be a huge problem. But more tasks more similar situations. Anyway for now it's just a strange fact.
Also I want to thank sevlll777 as a person who found 448C - Про покраску забора.
What do you think about this?






Really strange, yeah
agree
дизагри
Auto comment: topic has been translated by tem_shett (original revision, translated revision, compare)
Yes, it is clear that C will try to solve more people than E, and they will have more time to do it. In any case, it's a pretty cool fact, but it seems even funnier to me that the author originally made an English text with Russian names of tasks. I in no way want to humiliate the author, I also had similar failures, it's just really funny :)
Yeah, the article firstly had only russian version, because I use russian version of codeforces. But it also strange that problems included by id don't translated to english with english version of cf. Maybe it need to be fixed. MikeMirzayanov
Many problems with later positions have a very high difficulty despite not being very hard. 571D - Campus has 3100 but is quite easy. However getting it right in 2 hours together with all the previous problems is very hard, indeed there are I think 4 ACs during the contest.
They are just artifacts of the way the difficulty system works.
Pleassse, don't say "easy" about problems. For you maybe it quite easy, but for many others not. Just say "easier than it's difficulty says".
I didn't say "easy", I said "quite easy". And I think the meaning of "easy" was obvious from the context.
It is same problem as described below. See rating the top users are 2600-2760. So 3100 is extrapolation error.
I don't think it is. The argument below would predict the problem to have a lower rating, wouldn't it?
It is rating inflation. When 448C take place Div.1 started from 1700. So 1700 was rating for top users from div.2. See rating change. And if you calculate rating for task.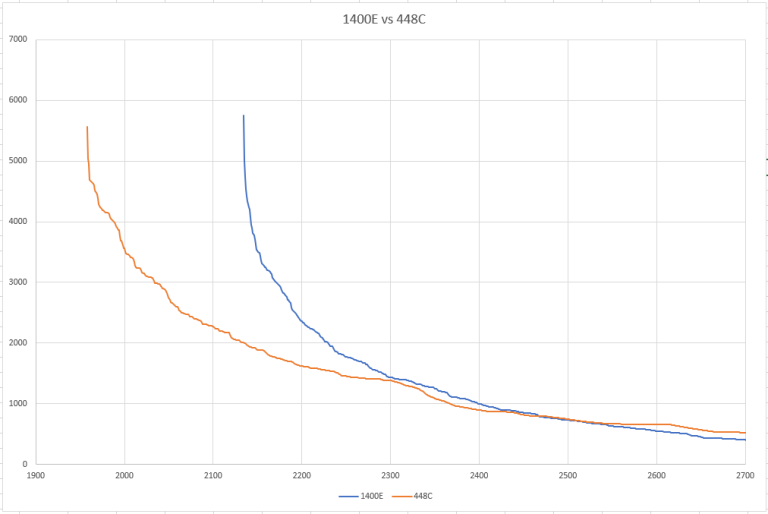 you will see that rating calculated correct based on CF formula. But it has limitation based on user rating in competition.
you will see that rating calculated correct based on CF formula. But it has limitation based on user rating in competition.
So it's calculated correct but not relevant to nowaday.
So you want to say, that old problems are harder the new with similar difficulty?
old problems at the top of div2 yes. For other rating it require more research.
The correct answer is. When task rating is higher than rating of people in competition than it calculated incorrect (CF formula is bad for extrapolation). All we know is 448C was too hard for 1700 and 1400E is near ok for 2100.
I'm pretty sure ratings are completely based on the # of people who solve the problem during the contest, so later problems are usually more inflated as most people start from the beginning, leaving less time for the end problems.
One thing I want to add here. Apart from one being C and the other being E, the problem E version has $$$a_i = 0$$$. My submission 90938786 passed the tests during the contest (where I did not handle the case). But after system testing, it got Wrong Answer. I guess many other contestants did similar mistake. That might have contributed a bit to the rating of this problem.
I checked it. There are no much falls during system tests, so you're wrong.
I checked too: 200 solutions failed in system tests and 150+ solutions got hacked.
It's not much (only 7%).
7% of what excuse me?
There were only 750 successful submissions during the contest
350/1100 does not seem like 7%
There are also some other weird things also about problem rating.1400D - Zigzags from educational round 94 has difficulty of 1900. So, if an expert solves 4 problems in time, he should obviously get positive rating change. Isn't it? But, there are experts who solved 4 problems and got negative rating change. Why?
Task rating 1900 is after ceiling. Task D rating without ceiling is ~1821 (according to my calculation). Rating to solve 4 tasks (with maximum penalty) without rating change is 1786 (you can check it here).
Then, isn't D worth of 1786 at most. Maybe it's less. Cause there are participants who solved D but couldn't manage to solve 4 problems. Then, D would be at max 1800. Isn't it?
No if those participants have rating less than 1786. There are many participant with rating <1700 who solved D but not solved B.
this problem is the harder version of the 448C problem (ai = 0) XD
Maybe at that time,everyone has a lower rating than now. So the difficulty is calculated lower.
U mean at that time problems with same rating as of now is tougher compared to now ??
I don't think so. In fact, sometimes I observe that some old (say from round 200 to 400) contest problems are overrated. (In fact, I just solved 899E - Segments Removal which is 2000 rated which took me less than 10 minutes to think and around 20 minutes to code which is definitely much faster than I do recent 2000 rated problems.)
I also think that gaining rate now is as tough (if not tougher) as ever. This observation is based on the virtuals I have given.
Although the solution to both the problems are same but reducing 1400E to 448C is not straight-forward, I'm still not sure how can I prove that both the problems are basically same.
You can just submit your code of any of that problems to another. And it will pass, so they're equal.
Proof By AC:).
AC = accepted (for people, who didn't know)
First note that in 1400E, the order in which operations are performed is irrelevant. Give disjoint and nested the obvious meaning for type-1 operations (those that remove one occurrence of each number from $$$l$$$ to $$$r$$$).
Given two type-1 operations $$$(l_1,\, r_1)$$$ and $$$(l_2,\, r_2)$$$, if they are not disjoint then the pair of operations $$$(\min{\{l_1, l_2\}},\, \max{\{r_1, r_2\}})$$$ and $$$(\max{\{l_1, l_2\}},\, \min{\{r_1, r_2\}})$$$ is equivalent, but is nested. By repeatedly making such substitutions for many pairs of type-1 operations, it is possible to arrive at a sequence of operations in which every pair of type-1 operations is either disjoint or nested.
Given such a sequence, it is easy to see that the nesting relationship allows one to describe the type-1 operations as several rooted trees. Then, we can translate a type-1 operation $$$(l,r)$$$ at depth $$$d$$$ in its tree in 1400E-speak to "paint a horizontal strip covering planks $$$l$$$ through $$$r$$$ between height $$$d-1$$$ and $$$d$$$" in 448C-speak. A type-2 operation $$$(i, x)$$$ gets translated to "paint a vertical strip covering the highest $$$x$$$ meters of plank $$$i$$$ that are not already painted."
The reduction of 448C to 1400E should be easy using similar ideas.
This is certainly due to their position in the problemset, many people would not have had the time to solve it and some might not have even opened it because it is "E" and not "C".
My opinion about problem ratings: These are calculated based on the rating of participants, since nowadays participation is more than ever, so codeforces has more data to process and to calculate problem ratings. Since larger is the data more is the accuracy, so i think nowadays calculation of problem ratings is much more accurate.
Thinking a lot about this now
Problems on Codeforces are rating-inflated.
Yeah, you're absolutely right