


We will hold AtCoder Beginner Contest 170.
- Contest URL: https://atcoder.jp/contests/abc170
- Start Time: http://www.timeanddate.com/worldclock/fixedtime.html?iso=20200614T2100&p1=248
- Duration: 100 minutes
- Number of Tasks: 6
- Writer: evima, gazelle, kort0n, EnumerativeCombinatorics, YoshikaMiyafuji, yuma000
- Rated range: ~ 1999
The point values will be 100-200-300-400-500-600.
We are looking forward to your participation!






how to explain the first example of problem D?
thanks a lot.
ya same here , someone plz!!
Not during the contest. Definitely not here. You can request a clarification, maybe the Jury decides to give some further explanation, maybe they don't, but this is the only fair way to get explanation during a contest.
ok,I know.I'll be more careful.
omg, My code won't even give an o/p locally but when I submit, it got accepted in Q D. xD
How can i see judge test cases after a contest in atcoder ?
https://www.dropbox.com/sh/nx3tnilzqz7df8a/AAAYlTq2tiEHl5hsESw6-yfLa?dl=0
Problem F is the same as this
Editorial:
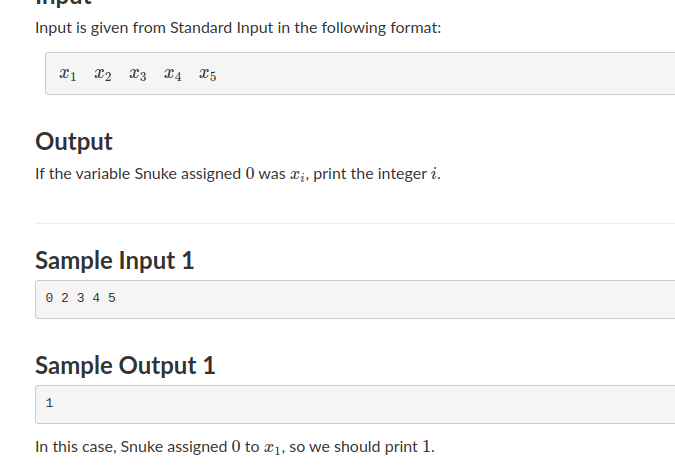
Just check if $$$x_i=0$$$
If the answer is "Yes":
check every integer between 0 and 101 (inclusive)
for each integer $$$X$$$ appearing in the sequence $$$A$$$,Set $$$AP_i=1(imodX=0,i>x)$$$
specially,if $$$X$$$ appears twice or more in the sequence $$$A$$$ ,$$$AP_X=1$$$
the answer is the number of $$$i$$$ that $$$AP_{A_i}=0$$$.
In $$$O(nlogn)$$$
Use a
priority_queuefor each kindergartens,then use a segment tree to achieve it.let dp[i][j] mean the smallest steps required to walk to [i,j].
In the beginning ,dp[x1][y1]=0.
Consider using dp[i][j] to update others:
dp[m][n]=min(dp[i][j]+1,dp[m][n]),only if :
m=i or n=j
the distance between them $$$\leq$$$ k
there isn't an '@' between them.
We can use 'shortest path' to achieve it,and use set to store the position that isn't updated in each line and row. In $$$O(H*W*log(H*W))$$$
https://atcoder.jp/contests/abc170/submissions?f.Task=&f.Language=&f.Status=&f.User=Gary
thank you for editorials!
i quite didn't get the heuristics you used in problem F: can you please write what happens when you move from dp[x][y] to dp[x + 1][y], how are your sets changing? how can your sets be defined? thanks.
When moving from dp[x][y] to dp[x + 1][y] only if dp[x+1][y] hasn't been updated yet,you can use sets to find it.
Then the cell->[x+1][y] is deleted from the set which represents column y as well as the one represent row x+1.Because [x+1][y] has been updated now!
In problem E multiset can be used instead of segment tree, because u need to know min over all array and can keep all top values in multiset.
In problem F, I don't understand how are you updating all possible [m][n] for state [i][j] which satisfies all three conditions, I tried it using loop from 1 to K resulting in complexity of O(H*W*K) :(
I just use set to store all of the states that are not updated yet.
For the D problem- Let us sort the array first. Now, let's iterate through the array from the beginning. After that, the idea is to maintain a map that will store all the values that have a)appeared in the array itself b)or are multiples of those elements that have originally appeared so far, that are less than 1e6. Time Complexity-0(N*(log(1e6))), which is equivalent to an O(N) complexity Here's my submission- https://atcoder.jp/contests/abc170/submissions/14321810 Also, for the E problem, do we have to maintain a vector of priority queues?
Priority queue won't be sufficient because we need to delete too from kindergarten. So I used multiset.
You don't need to delete an element from priority_queue any time some child leaves it. Instead each time you want to find maximum pick the largest element from priority_queue, check if the infant in question has leaved our kindergarden and if so erase it from queue and keep going. This still is amortised $$$O(n log n)$$$ since there are $$$n$$$ insertions and each element will be deleted at most once.
I did same but my solution is passing all testcases except 1. https://atcoder.jp/contests/abc170/submissions/14355498
we can also solve E by multiset(vector of multiset). link: Your text to link here...
How to solve F?
It's shortest path with the following optimizations:
1) You never want to go backwards
2) You never want to try something in the same direction, you could have just computed that before.
My submission for F
Are heuristics expected to pass for F?
submission
Was F bfs but I think time complexity will be more with BFS solution
Hi I am wondering the same thing, shouldn't it be O(nk). Ashishgup
yeah i tried the same thing ... but it fails 3 cases ... i don't understand why.. Here is the link
In problem D , i tried to solve by marking all multiples of numbers in array . But it gave TLE . I guess it is O(nlogn) (because it corresponds to harmonic series). submission
O(n*sqrt(n)) will also work
Yeah a similar concept to Seive
It is not O(nlogn) because a[i] may be not unique.
thanks .
Why not avoid using the same number to mark others?
yeah i should have done that . Later i solved by factorising the numbers.
Even I got WA and TLE , I think I misinterpreted the problem statement. Can you explain how output is 5 in test case 3.
Because 33,45,19,89,2 are not divisible by any other numbers other than themselves in the array.
I did the same You only have to take care that you do not do working for same number again
I have solved all problems in a contest for the first time. Hurray!!! Here's my idea for F:
Traverse nodes level by level. Let current level is i and all nodes of current level is saved in nlvl[i]. Sort those nodes by descending order of columns. Then from each of them try to go as right as possible. If you face a node which has level <= i, break the loop, which will ensure that you don't visit a node from same direction twice. Do similar things for other 3 directions.
My submission: link
Interesting idea. The reason this greedy modification works better than normal bfs is that every cell gets visited at max 4 times in your solution
E was a heavy implementation problem?
Upd : WA/RE teaches a lot.
Learned, why should we refactor our code. Make separate functions for the repeated tasks.
AC
:( ,I think it's more like a basic data structure problem.
I used sorted maps i.e (TreeMap in java ) for everything, maintained sorted lists for everything. But its just failing for 1 tc i.e random_case
Submission
I must have done many unnecessary things, cause it took me a hell lot of time code this.
Here are 2 small cases where your submission fails:
Input:
Expected output:
Your output:
Input:
Expected output:
Your output: RTE
Not all superheroes wear capes
Thanks ShafinKhadem.
AC
.
This is not a way to ask doubt you should not spam discussion with full code just post link of your code and try to explain your logic a little bit.
oh okay sorry ill get it removed
I created lot of treemaps and hashmaps in E and I was shocked that my code worked on the 1st go, the code got unbelievably complex though. In F, the naive BFS solution gave TLE on 2 test cases only. How to solve it efficiently?
Naive bfs complexity will be O(h*w*K), which will TLE. I have explained my O(h*w*4) solution in this comment.
You did not take sorting into account. It is O(hwlog(hw))
Keep
sets for unvisited cells (for each row and for each column), and remove cells when you add them to the queue. Then you would only look at every cell once. This introduces a logarithmic factor, but also removes the dreadful factor of $$$k$$$ in the naive solution.I solved F using a parent array which marks from where the element came into the bfs queue. Now when processing a nodes child if the node and it's child came from same parents then break the loop. This helps to solve it without the log factor and avoids moving in the same direction again and again. Solution link: https://atcoder.jp/contests/abc170/submissions/14351675
How to Solve F ?
I learnt after wasting 40 minutes in problem E that, multiset.erase() removes all occurrences of a given value from the multiset. To erase a single element, use this:
This is why I use map to store number of occurrences and erase the key once no. of occurrences becomes 0.
An alternative, if you don't want to worry about whether or not the value is present in the multiset:
Yea I also learned this today in problem D
or s.erase(s.find(value));
-->For d solution i came up with this solution
-->Created a map for count of given integers,for any number check whether its divisors present in map (or) when its count is >1 function returns false else increment count
-->solution :link
-->it passed 27 test cases and wa for 22 can any one tell what i have missed??? or corner test cases i have missed??
Try this test case
21 1the answer should be 0 but your code's output will be 1
another test case where your code will fail
45 5 5 25the answer should be 0 but your code's output will be 1
Accepted code link
https://atcoder.jp/contests/abc170/submissions/14329950 https://atcoder.jp/contests/abc170/submissions/14331317
The first submission for problem D gives me TLE, but when I replaced at line 172, MAXN = 10^6 with the real maximum of the input, second submission got accepted and actually the difference in time is huge. Why is that? It seems really strange to me. I spent too much time on that and I was kinda lucky to come up with that replacement because I was sure that the complexity is sufficient.
Thank you !
How to solve problem E of todays contest ?
Maintain a multiset for each kindergarden and one multiset for the maximums of the kindergardens. Now at every query you just need to insert/erase only from three multisets.
In problem d I thought checking all the factors will give TLE. but when 10 min was left I thought maybe I should submit the solution with TLE but rather it got accepted.
lesson learned : analysis of time complexity should be done carefully.
O(nlogn) so why tle?
osthir_brogrammer it's O(n*sqrt(n))
I was thinking the same but it's not correct, I think ??
can you explain how ??
here is my approach: I took the frequency array, when the element was greater than 1 I ignored the element and when it was equal to one I checked all it's factors and checked if any of them were present or not.
iabhishek15 Your approach is correct
you can preprocess divisors of numbers from $$$1$$$ to $$$Max$$$ using this way in $$$O(MaxlogMax)$$$
Div[x] stores divisors of x.
`
I think now I understand the time complexity :) and this is a nice way to preprocess all the factors.
Did anyone solve D in O(n * sqrt(n))?
I did
can you give the link to the code/submission?
Link
Useful Code in case if you find hard to read my JAVA template,
You can check out the C++ implementation of the same here! Submission for D
Lesson learned from D:
std::unique does not change vector size! must change it by myself.
is memory limit exceeded will show as RE at atcoder ? PS. I am getting RE for the only 1tc in problem E i.e random_10, can someone give me some corner cases? But I feel as setter must have added those corner cases in test files,this RE must be because of Memory Limit.
Submission
Messed up big tym n now, messing up on atcoder has become a habit :-(
Approach for Problem D — create frequency array for all elements and then check for each element whether any of its divisor is present in the array or not
Gives tle in one case and few wrong test cases
Link : https://atcoder.jp/contests/abc170/submissions/14362767
Any Suggestions ?
I did the opposite, I marked every multiple of each element till $$$ 10^6 $$$ and stored it in an array. Complexity would be like $$$ O(n\ log\ log (10^6) ) $$$
For the TLE part:- Just change your map to array.
Accepted code link
In Problem F, I understand the solution where one can keep a set for every row and column, to prevent visiting a single cell multiple times.
But, after looking at some codes, I realised some solutions broke their loop if
dist[cr][cc] + 1 > dist[r][c]where(cr, cc)is the current cell and(r, c)is the cell to be visited, from the current cell.For, instance checkout this submission.
I understand the correctness of the solution, but I do not understand how this solution will pass the time limits.
Here's an explanation.
when will they release the English editorial?
In 1-2 days, in the same editorial pdf, there will be an English version in the end.
It's there now
Can someone explain how the complexity of D is O(N*logN) (or O(N*sqrt(N)) from what I saw in other questions)? Shouldn't it be even bigger than N^2 (e.g. when I check for multiples of 1)?
For the O(NlogN) solution for outer loop you are going from 1 to n,for each i from 1 to n, you are marking it's multiples, we run inner loop on all numbers N/1 + N/2 + N/3 + N/4 + ..... + N/N times which equals O(NlogN)
you can find here proof for why N/1 + N/2 + N/3 + ... + N/N is O(NlogN) https://stackoverflow.com/questions/53240625/formula-for-the-sum-of-nn-2n-3-n-n
For the N*sqrt(N) soln you calculate all divisors of a number in O(sqrt(N))time ,you can refer this Primality tests and you do this for all N numbers Hence it is O(N*sqrt(N))
I got it! Thanks!
I think that the easier way to look at this is:
N/1+N/2+N/3+N/4+N/5+N/6+N/7+... < N + N/2+N/2 + N/4+N/4+N/4+N/4 +.. = N + 2*N/2 + 4*N/4 + .. + N*N/N = NlgN
Can Anyone explain me D Part pls?
First try to solve it for distinct elements.Traverse the multiples of every element and check whether this multiple is present in your array or not. If it is present then mark in your visited array that this element will not contribute in my answer. Your answer will be the n — sum(visited, visited + 1e6)
Is it possible to find english editorials for AtCoder contests? I want the editorial for E and F.
Just copy the Japanese text, and google translate it! I did the same, I think it's manageable
check the editorial now, they have added english editorial too
Can someone provide some test cases for problem F?
Here is my submission (though i don't think it will help), I've used a dijkstra-based approach here.
My solution passes all TCs except 3, so i suspect that it may be failing on a corner case.
Any Help is appreciated.
A small test case where your solution fails:
Input:
Expected output: 2 Your output: 3
Thanks man!
Where can I get editorials for the contest in English?? Specially for problems E and F!
Here. English editorial starts from page 7.
Problem F is the same as 877D - Olya and Energy Drinks!
For Problem D:
It could be done so easily using dp and sieve method. Couldn’t realise on contest time :') Though dp is really <3 . Submission
Test cases of the contest are not seen on dropbox. It shows that the file extension is not correct. Please fix it chokudai.
I had faced a similar problem to open test case file on other contests too.
It's accessible. You can check it here https://www.dropbox.com/sh/arnpe0ef5wds8cv/AACojGo4PhS93VqRGOYIT9tGa/ABC170?dl=0&subfolder_nav_tracking=1
Here is my submission for problem E. I used the approach of having vector of multisets and erasing the maximum and inserting again for every kindergarden using the approach mentioned in the tutorial, but i am getting TLE. Can someone help me why i am getting TLE.
Why my solution is wrong for problem D?
For input:
Your code outputs 3, output should be 2.
What's wrong in my F submission?
A small test for which your solution fails:
Input:
Your output: 8
Expected output: 7
Can someone provide me the link to that AC code for problem E in today's beginner contest which has used ordered multiset ( i.e. they should have used policy based data structures ) ?
It would be of great help.
I have solved the question using STL's multiset....but it's just that I'm curious about using them.
My accepted solution for Olya and Energy Drinks gives wrong answer on 2 testcases of problem F while the one using
std::setapproach passes. Why? :/A small test where your solution fails:
Input:
Expected output: 10
Your output: 11
MikeMirzayanov It seems like the problem 877D - Olya and Energy Drinks has weak test cases.
My AC submission on codeforces also gave WA on AtCoder. An example of a failed test case is the following one provided to me by dush1729:
4
The following submission of mine outputs 5: 47925337, but it still gets AC on codeforces. I request you to add the above test case to 877D - Olya and Energy Drinks
EDIT: Here's another test case which ShafinKhadem has mentioned in the comment just above mine:
10
My AC code 47925337 outputs 11 on this.
Why my submission for F works corectly locally, but CE on atcoder ?
Which compiler are you using to compile locally? Your code gives me compile error locally, when I use GCC 9.3.0.
gcc 5.1.0, is my version too old ?
I won't say too old, but I think it's better to use updated version.
Thanks, I'll update it.
Hi, I just tried compiling your code using GCC 5.1.0 too in godbolt. It gives compile error there. But in codeforces custom test, it compiles successfully. Which operating system are you using? Maybe your code gives CE only in linux.
I think you're right, my operating system is win7.
I found the reason! There is a header file called mathcalls.h in Linux and it has a function declared as double y1(double), so we cannot use #include<bits/stdc++.h> and declare y1 as a global variable at the same time in Linux!
A solution to this: add
#define y1 yyyy1in your templateThanks a lot!
Can someone please tell what is wrong in my code for problem F? Link to my submission-->Link Any help will be highly appreciated.
Thanks!
Hey ! Please provide copy button (for sample test case in Tasks for printing).
It's already provided. (Actually, twice each)
I was talking about tasks for printing section
I see. Perhaps it's no use writing here, and there's no official place to make suggestions, so maybe you have to write a UserScript or something...
If anyone need Problem D explanation with complexity analysis Here
Can someone help me with the code of problem F?
first second
I dont konw why the second code will get wrong answer.The only difference between them is the transfers about direction.I think it just needs more time to run but not to mislead the answer. Can someone help me plzzz?Thanks a lot.