


Внезапно, все задачи, кроме A и D, были придуманы мной. Автор A и D — MikeMirzayanov.
1234A - Очередное приравнивание цен
Разбор
Tutorial is loading...
Решение
#include <bits/stdc++.h>
using namespace std;
int main() {
#ifdef _DEBUG
freopen("input.txt", "r", stdin);
// freopen("output.txt", "w", stdout);
#endif
int q;
cin >> q;
for (int i = 0; i < q; ++i) {
int n;
cin >> n;
int sum = 0;
for (int j = 0; j < n; ++j) {
int x;
cin >> x;
sum += x;
}
cout << (sum + n - 1) / n << endl;
}
return 0;
}
1234B1 - Социальная сеть (простая версия)
Разбор
Tutorial is loading...
Решение
#include <bits/stdc++.h>
using namespace std;
int main() {
#ifdef _DEBUG
freopen("input.txt", "r", stdin);
// freopen("output.txt", "w", stdout);
#endif
int n, k;
cin >> n >> k;
vector<int> ids;
for (int i = 0; i < n; ++i) {
int id;
cin >> id;
if (find(ids.begin(), ids.end(), id) == ids.end()) {
if (int(ids.size()) >= k) ids.pop_back();
ids.insert(ids.begin(), id);
}
}
cout << ids.size() << endl;
for (auto it : ids) cout << it << " ";
cout << endl;
return 0;
}
1234B2 - Социальная сеть (сложная версия)
Разбор
Tutorial is loading...
Решение
#include <bits/stdc++.h>
using namespace std;
int main() {
#ifdef _DEBUG
freopen("input.txt", "r", stdin);
// freopen("output.txt", "w", stdout);
#endif
int n, k;
cin >> n >> k;
queue<int> q;
set<int> vals;
for (int i = 0; i < n; ++i) {
int id;
cin >> id;
if (!vals.count(id)) {
if (int(q.size()) >= k) {
int cur = q.front();
q.pop();
vals.erase(cur);
}
vals.insert(id);
q.push(id);
}
}
vector<int> res;
while (!q.empty()) {
res.push_back(q.front());
q.pop();
}
reverse(res.begin(), res.end());
cout << res.size() << endl;
for (auto it : res) cout << it << " ";
cout << endl;
return 0;
}
Разбор
Tutorial is loading...
Решение
#include <bits/stdc++.h>
using namespace std;
int main() {
#ifdef _DEBUG
freopen("input.txt", "r", stdin);
// freopen("output.txt", "w", stdout);
#endif
int q;
cin >> q;
for (int i = 0; i < q; ++i) {
int n;
string s[2];
cin >> n >> s[0] >> s[1];
int row = 0;
int pos = 0;
for (pos = 0; pos < n; ++pos) {
if (s[row][pos] >= '3') {
if (s[row ^ 1][pos] < '3') {
break;
} else {
row ^= 1;
}
}
}
if (pos == n && row == 1) {
cout << "YES" << endl;
} else {
cout << "NO" << endl;
}
}
return 0;
}
1234D - Запросы на различные символы
Разбор
Tutorial is loading...
Решение
#include <bits/stdc++.h>
using namespace std;
int main() {
#ifdef _DEBUG
freopen("input.txt", "r", stdin);
// freopen("output.txt", "w", stdout);
#endif
string s;
cin >> s;
vector<set<int>> poss(26);
for (int i = 0; i < int(s.size()); ++i) {
poss[s[i] - 'a'].insert(i);
}
int q;
cin >> q;
for (int i = 0; i < q; ++i) {
int tp;
cin >> tp;
if (tp == 1) {
int pos;
char c;
cin >> pos >> c;
--pos;
poss[s[pos] - 'a'].erase(pos);
s[pos] = c;
poss[s[pos] - 'a'].insert(pos);
} else {
int l, r;
cin >> l >> r;
--l, --r;
int cnt = 0;
for (int c = 0; c < 26; ++c) {
auto it = poss[c].lower_bound(l);
if (it != poss[c].end() && *it <= r) ++cnt;
}
cout << cnt << endl;
}
}
return 0;
}
1234E - Специальные перестановки
Разбор
Tutorial is loading...
Решение
#include <bits/stdc++.h>
using namespace std;
int main() {
#ifdef _DEBUG
freopen("input.txt", "r", stdin);
// freopen("output.txt", "w", stdout);
#endif
int n, m;
cin >> n >> m;
vector<int> a(m);
for (int i = 0; i < m; ++i) {
cin >> a[i];
--a[i];
}
vector<long long> res(n);
for (int j = 0; j < m - 1; ++j) {
res[0] += abs(a[j] - a[j + 1]);
}
vector<int> cnt(n);
vector<vector<int>> adj(n);
for (int i = 0; i < m - 1; ++i) {
int l = a[i], r = a[i + 1];
if (l != r) {
adj[l].push_back(r);
adj[r].push_back(l);
}
if (l > r) swap(l, r);
if (r - l < 2) continue;
++cnt[l + 1];
--cnt[r];
}
for (int i = 0; i < n - 1; ++i) {
cnt[i + 1] += cnt[i];
}
for (int i = 1; i < n; ++i) {
res[i] = res[0] - cnt[i];
for (auto j : adj[i]) {
res[i] -= abs(i - j);
res[i] += j + (j < i);
}
}
for (int i = 0; i < n; ++i) {
cout << res[i] << " ";
}
cout << endl;
return 0;
}
1234F - Очередной разворот подстроки
Разбор
Tutorial is loading...
Решение
#include <bits/stdc++.h>
using namespace std;
int main() {
#ifdef _DEBUG
freopen("input.txt", "r", stdin);
// freopen("output.txt", "w", stdout);
#endif
string s;
cin >> s;
vector<int> dp(1 << 20);
for (int i = 0; i < int(s.size()); ++i) {
vector<bool> used(20);
int mask = 0;
for (int j = 0; i + j < int(s.size()); ++j) {
if (used[s[i + j] - 'a']) break;
used[s[i + j] - 'a'] = true;
mask |= 1 << (s[i + j] - 'a');
dp[mask] = __builtin_popcount(mask);
}
}
for (int mask = 0; mask < (1 << 20); ++mask) {
for (int pos = 0; pos < 20; ++pos) {
if ((mask >> pos) & 1) {
dp[mask] = max(dp[mask], dp[mask ^ (1 << pos)]);
}
}
}
int ans = 0;
for (int mask = 0; mask < (1 << 20); ++mask) {
if (dp[mask] == __builtin_popcount(mask)) {
int comp = ~mask & ((1 << 20) - 1);
ans = max(ans, dp[mask] + dp[comp]);
}
}
cout << ans << endl;
return 0;
}
WA?
#include <bits/stdc++.h>
using namespace std;
int main() {
#ifdef _DEBUG
freopen("input.txt", "r", stdin);
// freopen("output.txt", "w", stdout);
#endif
int tt = clock();
string s;
cin >> s;
vector<int> dp(1 << 20);
vector<int> masks;
for (int i = 0; i < int(s.size()); ++i) {
vector<bool> used(20);
int mask = 0;
for (int j = 0; i + j < int(s.size()); ++j) {
if (used[s[i + j] - 'a']) break;
used[s[i + j] - 'a'] = true;
mask |= 1 << (s[i + j] - 'a');
masks.push_back(mask);
}
}
sort(masks.begin(), masks.end());
masks.resize(unique(masks.begin(), masks.end()) - masks.begin());
sort(masks.begin(), masks.end(), [](int x, int y){
return __builtin_popcount(x) > __builtin_popcount(y);
});
int ans = __builtin_popcount(masks[0]);
for (int i = 0; i < int(masks.size()); ++i) {
if (clock() - tt > 1900) {
break;
}
for (int j = i + 1; j < int(masks.size()); ++j) {
if (!(masks[i] & masks[j])) {
ans = max(ans, __builtin_popcount(masks[i]) + __builtin_popcount(masks[j]));
break;
}
}
}
cout << ans << endl;
return 0;
}







Fenwick appraoch for 1234D : Solution
Implementation similar to: CodeMonk Problem
Awesome contest by the way! :D
I used bitmasks and segment tree instead: 61684182
I also used a segment tree but I used sets instead of bitmasks: 62130226
Apparently it is too slow... Can anyone explain why? by how much? or if it has a worse complexity time than the tutorial or other solutions?
Sets would be slower by a constant-ish factor (final complexity about $$$O(n \log n \cdot A \log A)$$$), since there are at most 26 distinct letters. This could be significant, as bitwise operations are one of the fastest hardware operations that a computer can do, compared to having to clear and rebuild trees every update.
Can you please tell me how you came with the intuition of using Fenwick tree?
From what I can tell it's the same concept as explained in the editorial, except that he's using a Fenwick tree instead of an ordered set for "does the character exist in this range" queries
Spheniscine Correct!
pyduper I am assuming you know basics of BIT :)
Notice that the question wants us to find if a character exists between the range l to r. ie. for all characters from a to z if their count(l to r) > 0 or not.
Which we can easily do by creating 26 BITs for every alphabet(and basically do what a BIT does)
So the ans for total distinct elements between l and r would be like :
Updating BITs :
Assume we need to change arr[index] to char ch what we notice here is that we have to decrease frequency in BIT[arr[index]] at index by 1 and increase frequency of BIT[ch] at index by 1
which would be like :
Also the complexity of the code would be : NlogN + 26*QlogN which is quite feasible :)
Thats it!
Thanks.. I accidentally down voted instead of up voted. I cannot change it now. I am really sorry.
funny thing that I saw a lots ppl like you, they knew a lots advanced things that I only heard about, like segment tree or fenwick tree or dp on tree, but the most important thing that you and they are the same, just only specialist. So the question I want to know that why you know a lots but you cant do anything gud in official time of a contest, and can I archive candidate master without knowing about segment tree or fenwick tree. I really need to know answer for this question, help me if you can, plz!
Well, it's just been a year since I knew about CP and if you see my rating graph I was not serious at all till april-may(mostly because I was into development at that time) so that makes about 7-8 months.
If you ask me the reason the obvious answer would be lack of practice(I have just solved about 400-500 problems (mostly easy-med) over coding websites all together).
looking at my graph I think I am kind of improving (maybe?)
important My personal thoughts: BIT should not be considered as hard as Segment Tree (according to me a person with 1400+ rating can easily understand and implement BIT).
BIT just requires 8-10 lines of code to implement. Also, I've never actually required to implement a seg tree in questions of rating < 1900 (mostly) but that's just my personal thoughts :D.
My opinion is that BIT is easier to code, but harder to intuit, while segment trees are the opposite. Segment trees are more powerful (it can solve any problem BIT can, and some problems BIT can't), but BIT tends to be faster constant-wise.
This problem is actually quite instructive about the difference, cause you need 26 sum-BITs, one for each character, but only one OR-segment-tree. Segment trees can work on any monoid (type/set with an identity value and an associative binary operation), but BIT has the additional requirements of the operation being reversible and commutative, hence working on + but not on OR (which is commutative and associative, but not reversible).
Hi Dsxv
1234D
I tried with an approach similar to the one mentioned in editorial. The only difference between the implementation is: I used array of sets while they used vector of sets. Could you please tell me what's wrong with my solution:
62051065
I think the 'lower_bound' in your code is working in linear time. Just replace it with ( it = contain[i].lower_bound(l) )
Thanks Ahmad7_7, it was the culprit, now I got AC. But can you tell me why those two are not of similar complexity?
You will find the answer here
Hey!!
What how will we solve the problem D if we are asked the count of distinct characters which occur more than two times in range??
Also can you suggest something where I can read about the BIT topic
My solution to E: https://codeforces.me/contest/1234/submission/61676673
Just consider how the distance of each pair in the array changes in permutations.
Let the smaller number in the pair be m and the other be n;
The distance increases by m-1 when i=m because m goes to the front and the distance increases 2m-n when i=n because n goes to the front and m shifts 1 backwards. For i from m+1 to n-1 the distance simply decreases 1 because one of the number between them goes to the front.
I hope my explanation makes sense as English is not my first language:D
can you please elaborate?
In the first to (m-1)th permutations the distance between m and n is constant. In the (m)th permutation, the number m goes to the front of the permutation so the distance increases by m-1. In the (m+1)th to the (n-1)th permutations, one of the number between m and n goes to the front so number m shift one unit back thus their distance decreases by 1. In the nth permutation the number n goes to the front while number m stays in the position of m+1 so now their distance is m+1-1=m. The distance used to be n-m so the change of the distance is m-(n-m)=2m-n In the rest of permutations, their relative position is back to normal so the distance doesn't change.
Does this make sense?
Weak Example in F makes me WA on 5........ I want strong example QAQ (sorry to my poor English :D
How can we do C with dfs?
You will TLE
C can be solved by dfs by building a graph like this: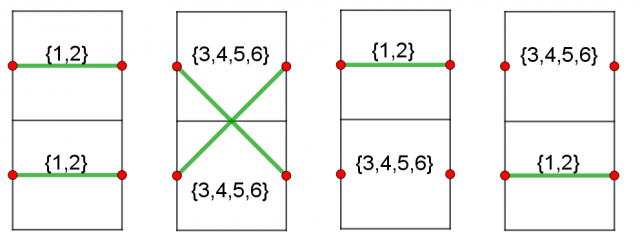
and check if there is a path.
Can you please explain how to do it with dfs with proper code and explanation?
look at this code https://codeforces.me/contest/1234/submission/61647685
what do the various directions specify in your code
direction in which water is entering.
I got accepted with dfs, the ideia is basically what MZuenni said:
Firstly you make two types of edges, {1, 2} and {3, 4 ,5 ,6}, and you can see that with edges {1, 2} you can only continue on the line that you are, going to the next column, and with edges {3 ,4 ,5, 6} you go to the next column changing your line (see the picture above).
If there is a path, then there is only one of them, by the "nature" of the edges, so the complexity is O(n).
Here is my submission: 61677625, hope to be clear enough.
It is obvious that because of dynamic programming we need to remove at most one bit from our mask to cover all possible submasks that can update our answer. What is this means ?
Now I understand it , becasue some dp[mask] may not init
I did the testing for F and found out few Test Cases. Surprisingly the WA code when ran on custom innovation, It gives same answer as that or correct code, But when it's executed locally or on some other online Compiler(other CP sites like codechef), the WA program fails on following Test Cases.
Test case Correct_O/P O/P_of_WA Code
obgtjbtlfbdmqksnq 12 10
pbfpdqlqsptfq 7 6
jlotbnjqoeqqll 8 7
dtrdlfighqlikdad 10 9
Though If anyone finds the reason behind the behaviour of WA code in Custom Innovation, do let me know. I'm quite curious about this.
That's because CLOCKS_PER_SEC in codeforces is 1000, but in other compiler (I used Dcoder) is 1000000. So clock() gives microseconds. Instead you should set , (clock()-tt) > (1.90)*CLOCKS_PER_SEC).
My code for problem C. https://codeforces.me/contest/1234/submission/61656247 Can anyone help me with that? I considered that the number of 3,4,5,6 type pipes should be odd and if a pipe is of 3,4,5,6 type in one row,it should be of the same type in the corresponding index of the other row.
Leave it,got the error
I also applied segment tree approach 61686336. But it's giving TLE. Can anyone please tell me where I went wrong?
@gaurav_iiitian check my code I used segment tree and it got accepted. My code was easy to understand..
link — https://codeforces.me/contest/1234/submission/61689286
Thanks @dhruv_garg for replying, But I think our implementations are almost same. The only difference being I coded in python. I think codeforces hasn't set time multiplier for python since my code is giving TLE in just 2s which should be 10s for python. @admin look into this please. I'm really disheartened to see this in codeforces and it's my early days here.
Same story, but I did it after contest by adding some optimizations. Firstly I used bit representation for each char: 'a': 1, 'b': 2, 'c': 4. We have an alphabet with size of 26. So 'z' is 2^25. And if you want to know the sum, you just do bitwise OR (
Node1 | Node2). Then I precalculated bit representation for every char and stored it in the dictionary. I added the popcount function (https://stackoverflow.com/questions/407587/python-set-bits-count-popcount) for [l, r] requests. Python got TL on 9th test, but PyPy got AC with 1980 ms. Here is the submission 61730030. Hope it will help.I also got TLE when I implement segment Tree with Python...@admin please have a look at this..
I used approach of tutorial D. Can someone please explain why lower_bound(s[i].begin(), s[i].end(), l) is getting TLE but same solution with s[i].lower_bound(l) instead, not?
Only difference is way of using lower_bound.
see this
Thanks a lot. Understood the reason.
Why does ceil(double(sum)/n) give a wrong answer on but (sum+n-1)/n doesn't.
refer this thread, https://codeforces.me/blog/entry/70185?#comment-547110
can someone help in finding issue in this code https://codeforces.me/contest/1234/submission/61661254. it's failing on 1 test case on codeforces compiler. but locally it passes
Решение в $$$E$$$ ломается, потому что в пересчёте длин предполагается, что второй элемент будет оставаться на месте, что не верно в случае $$$x_i = x_{i + 1}$$$.
Да, я понимаю, из-за чего это, и где именно ломается формула, но просто решил важным сообщить, что именно это может быть ошибкой.
D можно решить с помощью дерева Фенвика/ отрезков + использовать что-то похожее на префиксные суммы. Сделаем несколько наблюдений: 1). Если мы меняем конкретный символ, то значение префиксных сумм(количество элементов на префиксе) на подотрезке с pos до конца строки уменьшится на 1.
2). Для нахождения ответа на 2 запрос следует проверить, что на подотрезке с r по l-1 был хотя бы один символ (то есть значение префикс.сум[r]-префикс.сум[l-1] было больше 0)
3). Чтобы хранить значение префиксных сумм всех 26 букв английского алфавита, будем использовать двухмерный мас сив (при этом не только префиксные суммы, но и дерево отрезков/Фенвика)
4). Обновляли значение конкретных символов на подотрезке — (в Фенвике/ДО добавлял и в случае,если меняли на данный символ, вычитали, когда меняли данный элемент) — префикс.сум[r]-префикс.сум[l-1]+(значение в дереве[r]-значение в дереве[l-1]) (на подотрезке с pos до длины строки вычитали на 1 в случае уничтожения(изменения) данного элемента, прибавляли на 1 в случае изменения на данный элемент)
Теперь осталось реализовать ДО/Фенвик и использовать данные наблюдения.
Well. I have a deterministic solution for F. vovuh I don't know where your solution will break. But intuition is not coming. My approach:
dp[mask][len] will store maximum starting index for all the submask of mask with length len. then we can simply find the answer for it's complement for all length. link to my solution:
61694665
As you can see, my main solution is deterministic too (and it solution is described in the editorial). Moreover, my second (possibly WA) solution is also fully determined (except the order of masks with the same number of ones).
vovuh I don't understand how you are making sure that the mask will not override...
UPD: got it. silly me. Thanks
Damn slow python... Got TL with Segment Tree
I also got TLE when I implement Segment tree in D problem ...I guess they did not give enough time for python
Use Fast I/O in Python input=sys.stdin.readline
and Submit it using PyPy3
Refer this to get an AC-- https://codeforces.me/contest/1234/submission/61749285
I already use Fast I/O and I tried it in PyPy3 ... but actually I got my mistake there was no problem of time given
For extra masochism, try solving heavy bitmask problems with JavaScript :P
Very Nice Explanations and Clear Editorials.
I wonder why I got TLE in pronlem D when using Segment Tree......(61656622)
(sorry for my poor English x(
My solution got tle in D in system testing and the same solution is accepted on submitting after System testing
https://codeforces.me/contest/1234/submission/61710080
https://codeforces.me/contest/1234/submission/61641496
Your accepted solution took 1996ms which is too close to limit of 2s. difference of few ms in runtime can happen due to various factors.
Thanks
I think this is not as simple as before
After the contest I tried to write B2 with STL deque,but when I use unordered_map it got TLE but map got AC.In my previous conciousness map should be slower than unordered_map,what's wrong with unordered_map in B2?
The unoredered_map version TLE:61711501
The map version AC:61711675
You can read this
If you use unordered_map, your time complexity may up to O(n).
(and, sorry to my poor English
SquareRoot Decomposition approach for D: 61667541
Need help in this. https://ide.codingblocks.com/s/137727 for problem D this solution is getting WA for test case 2 https://ide.codingblocks.com/s/137726 I just switched line 91 and 92 got AC for all the test cases. Why am i getting this. I created 26 sum query segment trees and for every alphabet if the sum of segment is greater than 0 then there is that distinct character in it and I increased the answer for that query. Why does swapping two line get me WA?
For B2:
Changing from unordered map to map gave AC. The unordered map is faster than the map then why did I get TLE?
Thanks.
https://codeforces.me/blog/entry/62393
I dont think prob E is a 2000-difficulty problem, just like a 1700 or 1800 problems in a div2 contest. I also saw a quite easy task in another div3 before that had 1900-difficulty. I feel weird when there are a lots overrating problems in div3, so I wonder how ppl rate difficulty for problems
Yeah that's true. It's probably because many high rated coders just solve the last problem and leave the contest. And the algorithm thinks they couldn't solve that problem. I am not sure about this. I am just guessing
Problem rating are decided by relativey how many official contestants mangage to solve it during live contest. Majority of people do not get time to even read last 2 questions hence they could not solve. Ultimately, that leads to over-rating.
Anyone can explain why using std::set gets AC but gp_hash_table (policy based data structures)(https://codeforces.me/blog/entry/60737) gets TLE? I'm very confused.
AC: 61716953
TLE on test 20: 61712878
dont use hashtable, its overkill in this case, and also hashtable sometime is not a gud choice because of hacks. Consider using a deque instead, this task is all about how to work with a double end queue and nothing else
Yeah, i just used hash table to check if elements existed in queue or not.
But I can not understand why set + deque = AC but gp_hash_table (as I know it's 4x faster than normal std::map) + deque = TLE. It's weird.
I am not sure but what he mean is that it can be hacked. refer this blog
I used a segment tree for problem D. I tried the segment tree that had unordered_map(61658230),set(61650912) and map(61656330) as elements of its nodes but all three showed TLE. Can anybody help me figure out where is the mistake in my code.
As C have only 2 input strings, I zipped them, and used regex with eval, analyzing pairs of symbols (columns). An alternative to if-else blocks. Perl code 61668008 (or shorter without zip: 61669016)
Alternate approach for E, any two consecutive elements of the array x and y contribute abs(x-y) to all f(pi(n)) where i is less than min(x,y) or when i is greater than max(x,y). x and y contribute abs(x-y) -1 to all f(pi(n)) when i lies between x and y.
Using a Segment tree with lazy propagation we can do the above contributions/range updates for all pairs of consecutive elements. Answers will be the ranges i,i for i: 1 to n
Here is the code : https://codeforces.me/contest/1234/submission/61666909
In problem E, I have this stupid question which I cannot figure it out on my own -_- .
In the code provided above:
So why res[i] += j + (j < i) here. I thought when we move the element i to position 1 then the cost should be res[i] = j-1 + (j < i), shouldn't it?
Thanks in advance <3
I don't sure my answer what exactly do you mean but if I understood you correctly, that's because $$$i$$$ and $$$j$$$ are $$$0$$$-indexed in the code.
He has decremented values of a[i] initially that's why res[i]=j+(j<i).
Problem D: I implemented editorial's solution in JAVA. For that I had to use TreeSet for lowerbound() function. Here's my JAVA code: 61727406
Can somebody explain me problem F's soln? Sorry but i am unable to understand the editorial?
Need DP idea of Problem C.
check out my submission
can anybody explain, what does this mean ?
"Let dp[mask] be the maximum number of ones in some mask that is presented in the given string and it is the submask of mask" , here what does the submask of mask mean?
The submask has fewer or equal number 1s than the mask and the position of all the 1s in submask coincide with the 1s in mask (the mask includes the submask)
For example : 010011 is the submask of 011011
This is my opinion so correct me if I'm wrong <3
can you please explain how the submask is helping in dp , I have understood till the point in editorial that we have to find two non-intersecting mask in the string and the one of the pair with max sum from both mask will be answer, but I can't understand beyond because of not able to understand the role of submask in dp further from here.
So the point the submask is important is :
$$$dp[comp]$$$ will be the maximum number of 1s from all the submasks of $$$comp$$$ (include the mask $$$comp$$$ as well)
We don't know if the " $$$comp$$$ " mask is really present in the string or not, so we need to take the max of the submasks so that it is added to the answer.
For example:
--> $$$comp$$$ is ...011001 ($$$comp$$$ may or may not present in the string). So if we don't take the max of the submasks then $$$dp[comp]$$$ will be 0 then. But let suppose there is a substring (which is a submask of $$$comp$$$) ...010001 (...ae...) then $$$dp[comp]$$$ will be >0 (say, 2) and the answer is larger.
P/s: if $$$comp$$$ doesn't intersect with $$$mask$$$ so the submasks of $$$comp$$$ doesn't also
Didn't understood the tutorial of E could someone pls elaborate on making prefix arrays.
My approach is somewhat different:
Let $$$F_j$$$ represent the $$$j$$$-th answer value, i.e. $$$f(p_j(n))$$$.
Now consider each consecutive pair in array $$$x$$$, i.e. $$$x_i$$$ and $$$x_{i+1}$$$. We want to consider this pair's "contribution" ($$$|pos(p_j, x_i) - pos(p_j, x_{i+1})|$$$) to the final values in $$$F$$$. Let the smaller of the pair be $$$l$$$ and the greater be $$$r$$$ (if they are equal, their contribution to all values of $$$F$$$ are zero, so we can skip it)
It turns out that we can split these contributions to five regions:
Now the problem reduces to the "Array Manipulation" problem from HackerRank, i.e. we need to find a way to efficiently add values to entire ranges of indices. It turns out that there's a simple solution: instead of working on the final array $$$F$$$, we work on another array $$$D$$$ instead, where we want the eventual value of $$$D_i$$$ to equal $$$F_i - F_{i-1}$$$. We can then extract $$$F$$$ from $$$D$$$'s prefix sum.
So if we want to add e.g. value $$$x$$$ to $$$F_{a..b}$$$, simply add $$$x$$$ to $$$D_a$$$, and subtract $$$x$$$ from $$$D_{b+1}$$$.
Sample code (Kotlin): 61688222
How did you come up with those five contributions ?
Edit: Nevermind, that's simple observaton. Got it.
Problem A can also be solved using binary search :: Solution : https://codeforces.me/contest/1234/submission/61633785
but its not need
【Problem E】 I did not understand what tutorial says. please tell me what cnt[min(x[j],x[j+1])+1] and cnt[max(x[j],x[j+1])] stands for.
Because all the number from $$$min(x[j],x[j+1])+1$$$ to $$$max(x[j],x[j+1])-1$$$ will have their presence increase by 1 so $$$cnt[min(x[j],x[j+1])+1]++$$$ and $$$cnt[max(x[j],x[j+1])]--$$$. From the number $$$max(x[j],x[j+1])$$$ till on doesn't increase so we decrease 1 at $$$cnt[max(x[j],x[j+1])]$$$
Has someone solved D with a segment tree with bitmasks, or am I alone dumb?
If you mean problem D, yes I did it that way too (after contest time though, cause the contest time wasn't convenient for me, but I solved it blind)
Lol, I forgot write problem which I meant, anyway thx for answer
F. Yet Another Substring Reverse ( with explanation )
Check out my solution for more detailed explanation : 61824886
Thanks a lot :) Great Explanation!
Умные люди можете объяснить почему это так: "...нам нет смысла рассматривать такие пары xj и xj+1, что xj=xj+1...". Ответы: "Так написано в разборе" не принимаются)
what is __builtin_popcount??? i don't know it
it counts the set bit in a number
ohh thanks very much you are so nice
F is beautiful problem
I have a question about pipe. In the context we could reasonably assume that the we are searching in 0th pipe and 1st pipe. If we encounter 3,4,5,6, we will make cur = !cur or cur ^= 1 The logic is simple, but when I tried to use an array of dimension 2 x n, the test 2 is always failed. Then I switched to string array dimension of 2, by the same algorithm, my answer was accepted. What is the difference?
I guess I find a counter test case you mentioned in Tutorial-1234F.
The answer should be 20, but may got 19 when using WA?-solution. counter test case like this
Problem A should had to be explained more clearly and easily with notes
Did Problem E, With segment tree lazy propagation Solution 88938957. For detailed explanation comment below.
I loved the question D..
D can be solved in a very straightforward way with Segment Tree and bitmasks. Each node should contain a bitmask detailing which letters are present in it's subtree. During calculation, nodes can be combined using bitwise OR, and the final result can be read with
__builtin_popcount().i solved problem F using SOS dp. it is my first problem where i used SOS dp when solveing problem randomly.