


Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |






"All possible shifts of Alice's and Bobs' pattern periods are the multiples of gcd(ta,tb)"
Can somebody please explain this part? How do you prove this? Sorry if this is a silly doubt.
Here you go: https://en.wikipedia.org/wiki/B%C3%A9zout%27s_identity
Holy crap can't believe I missed this
Can you please explain how Bezout's identity can be used to prove the above point ?
https://imgur.com/a/e8lm6rY, Look at the image, we have two patterns length of 6(123456) and 4(ABCD), shift will be 2(6-4),4(12-8),6(18-12).... so on, Also for length a and b where (a > b), shift will be of form of x * a - y * b which is a multiple of GCD(a, b), hence every shift will be a multiple of GCD(a, b)
EDIT: What is a shift here? :
Look at the image and observe the indices of starting points of patterns (1)23456 and (A)BCD , 1 has indices 1,7,13,19 and A is at 1,5,9,13,17 , so shift is the difference of indices of starting points of the patterns, 1-1 =0, 7-5 =2, 13-9 =4 and 19-13 =6 ... so on
what is a shift??
Imagine as stacking on:
In the first stack: we adds pieces of size 4.
In the second stack: we add pieces of size 6.
If we add same amount to both, the second stack will get 2 more ahead each piece added.
Thanks a lot. :)
I solved problem D just after the contest, but I thought a little about my solution and found that it's wrong. Suppose next test:
Which answer would you prefer? "NO" or "YES a b"? My accepted solution 45540070 said "YES a c", but the strings won't be equal after applying this operation.
In other words, when i'm looking for the leftmost and rightmost indexes where strings
sandtdiffer, I check thats[i] != t[i]. After that I check that substring ofsis the same in all the strings where any characters differ, but I never check that stringsttaken with the same indexes are equal.Jacob please reply. I don't think it's ok.
I agree it's not ok, sorry about this. We somehow overlooked this opportunity to make a bug and didn't prepare tests against it. I have added your test to the upsolving.
Don't you wanna rejudge all the submissions? I'm sure I'm not the only who missed this.
Kuyan, Jacob, cdkrot, 300iq, MikeMirzayanov, I'm waiting for any response about rejudging.
I know it won't affect final standings much, but anyway there may be incorrect solutions which got Accepted when it's wrong.
We never rejudge submissions after the contest. I can add some tests to upsolving if you want.
But it gets ML immediately!! :(
Really, can you kindly explain reasons to prevent competitors from constructing trie explicitly?
Incidentally, my solution is just array traversal. Basically, when processing a bit, I have pairs of arrays (a, b) such that only all xor(element of a, element of b) are considered; these arrays are all concatenated and I just remember the positions where they start/end in the resulting array.
Processing bit b consists of counting how many pairs give a xor with bit b equal to 0, deciding what should be the b-th bit of the result and using that to split each pair (a, b) into 4 arrays a0, a1, b0, b1 based on the value of bit b in their elements and pairing them up, with some obvious anti-blowup rule like "skip pairs where one array is empty".
This can be implemented recursively, but also using just 2 concatenated arrays and 2 start/end-arrays for odd and even b. A convoluted approach that passes these limits...
Thanks for noting this, I've now added some explanation to the analysis that the trie should be constructed implicitly after sorting all numbers first.
Now I'd like to explain the reasoning behind memory limits in this problem. Some of the round testers actually prepared explicit trie solutions. Being written in C++ with rather heavy optimizations, they could pass the time limit but with a minimal margin (if ML was set to 1024Mb). Therefore, in my opinion, raising memory limit to allow explicit trie solutions would create additional "randomness" in this problem (we didn't want participants to spend too much time optimizing the correct solutions) and would give participants who code in C++ some advantage over Java (because in Java sneaking under the time limit with explicit trie is much harder, if not impossible).
The time limit and constraints of F really don't go well. I rewrote my clearly O(62n) algorithm using a
vector<pair<vector,vector>>into one withvector<long long>, vector<pair>(the point is memory efficiency, which really shouldn't be a factor when possible) and got AC in 2 seconds instead of TLE. Yes, AC is possible, but it might need heavy constant optimisations even with a good algorithm simply because the input is big. Twice as large TL or half as large input would make it still about some constant optimisations of stupid implementations, but not such heavy ones.We would probably wanted to have slighly larger TL, however this makes a log2 solution close to pass.
Besides, the TimeLimit was not very strict in fact. We even had the model written in java!
Java isn't a magic constant-time slowdown. How a program works depends on what it does, not what language it's written in.
This gets TLE. The time complexity is O(62N) and it doesn't use any special STL functions, apart from vector<> push_back and copy-constructor. You don't have to explain to me why it gets TLE, but you could explain if that's intended to fail.
Yes, we found that during testing. We believe that the constant factor of this implementation of the solution (unfortunately) is so large that it is even not very much possible to cut it from O(log2).
There is some slightly other approach however, which doesn't have so many memory operations.
Yeah, my "slightly different approach" is just working with a concatenation of all those arrays + vector of their (start, end) pairs instead. Still, understanding why this works is something I consider beyond the scope of a sane problem in an algorithmic contest — I only learned about such things when I started working. It's not super difficult knowledge, but tangential knowledge.
That's the problem with trying to distinguish between log and a constant in competitions. In my experience, it's not worth doing because you'll only end up with this situation — people passing because of an implementation they chose by chance. The same applies to strict limits in interactive problems. Of course, there are exceptions, but they're very specific and usually just see that it's a problem where you can push things further.
I'm not even outright opposed to constant factor being a factor (lol), but when it's clear that a constant matters, it's best to admit it and put a warning in the statement or something.
Why is it the third problem I encounter during last month, with your involvement in its preparation and which has such kind of issues?..
Reminder: 1054H - Epic Convolution, 1043D - Mysterious Crime
P.S. I suppose it would be enough to just lower numbers to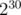 to both still cut off binary search and
to both still cut off binary search and 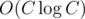 solutions, but not cut off
solutions, but not cut off 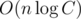 memory and not have such constant-optimization issues... Am I wrong?
memory and not have such constant-optimization issues... Am I wrong?
I agree, that you have a point on 1043D, it was not very nice indeed
As far as I've seen, you are wrong about 230
I'd like to ask about C problem.I'm dense, sorry. I thought that ta and tb is LCM, in the contest. Why is gcd, not lcm? I think that lcm is because ta and tb are period. Thank you.
LCM also works, but GCD is more useful to us. It's not too difficult to see why you would repeat every LCM tiles. But here is intuitive way to show GCD will work.
First define A' = A/gcd(A,B) and B' = B/gcd(A,B) and now realize lcm(a,b) = A' * B' * gcd(A,B)
And now group your data into chunks of size gcd(A,B), and you will notice every A' * B' chunks will repeat.
xo|oo|oo|xo|oo|oo|(repeating) here x's are 6 apart
xo|oo|xo|oo|xo|oo|(repeating) here x's are 4 apart
A |B |C |D |C |B | (repeating) the pattern ABCDCB will repeat (what I decided to label chunk patterns as)
(Try writing it out and drawing lines at every gcd(6,4) = 2 characters away, A'*B' = 6)
But actually it doesn't matter what A'*B' is, we only care that the pattern can be contained within gcd sized chunks. Because it can, we can just move down both left indices to the first chunk (say, by doing l=l%gcd) while maintaining correct bounds
This is actually enough observation to pass the tests: https://codeforces.me/contest/1055/submission/45546142 (ignore the weirdness of the gcd function, just leftovers from another idea)
I think, if you use lcm you'll get the interval after which patterns get same corresponding values, if you use lcm instead of gcd , shifts will not have any effect
Can you tell me what does shift mean?
http://codeforces.me/blog/entry/63099?#comment-470272
The solution for F described here is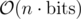 . Was it intentional for the hash map solution of the same time complexity to time out?
. Was it intentional for the hash map solution of the same time complexity to time out?
Hash map has big constant. My solution(45530383) is the same as yours, but I use sort instead of hash map. Asymptotically it is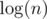 times slower but in practice it is faster.
times slower but in practice it is faster.
Overall I think trying to not let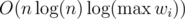 solutions pass in this problem is bad, because the difference in time is not big enough.
solutions pass in this problem is bad, because the difference in time is not big enough.
My final in-contest submission did the same: 45535363. Unfortunately while your code was just under 4000 ms, mine ended up barely over the limit. The same code passes by adding fast I/O to save a few hundred ms: 45571940. Agreed on the difference not being big enough.
The intention of rather severe constraints and time/memory limits here was to differentiate the binary search from the solutions with the correct (intended) complexity, because the binary search in this problem is probably too simple. In our case a reasonable (not very optimized) solution in Java implemented in the way described in the analysis worked in about half of the time limit, and significant part of that was just I/O. There is also an obvious room for 2x speedup in the actual computation by exploiting the symmetry and reducing the number of states in half. This means that likely your solution indeed has a very high constant factor.
Representing a trie node by a range of indices in a sorted array is a heavy optimisation.
In detail: depends on implementation, but it will most likely have an extremely low number of cache misses, pipeline stalls and write buffer stalls (if the architecture has write-through cache). If trie nodes were actual node pointers, it would be much worse.
I think it's acceptable to distinguish linear from log-linear. However, in practice what actually happened here is that many linear solutions failed, and some log-linear solutions still passed, so in the end it really just became a constant factor contest.
Just because there are people that want to know more about problem C and that the editorial isn't very eloquent, I'll give a more detailed analysis.
First of all, if one can make an Alice's interval and a Bob's interval coincide (in the sense that both begin in the same number) then the answer is just min(rb - lb + 1, ra - la + 1) (the length of the shortest interval).
However, this may not be possible (for example, if Alice's pattern is +++--- and so on, and Bob's are -+++-- and so on, they will never begin at the same place).
Something important is to remark that in particular in a "maximal overlap" one of the intervals beginning will be inside the other full interval (it means that Bob's beginning lies on an Alice interval, or the opposite).
So let's analyze what happens with a maximal overlap in the case that Alice's interval beginning lies on Bob's interval (note that Alice's interval may be longer or shorter than Bob's).
The only possible values for Alice's beginning are of the form la + kta, and in particular, we want to know the least possible value of y such that lb ≤ y ≤ rb and that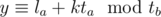 .
.
Note that for such an y to exist, it's neccesary that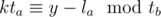 . And as k is immaterial at this point, this means that the congruence
. And as k is immaterial at this point, this means that the congruence 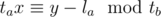 has to be solvable, which means that
has to be solvable, which means that 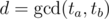 must be a divisor of y - la. So, we want to know the least y in the interval [lb, rb] such that y - la is divisible by d.
must be a divisor of y - la. So, we want to know the least y in the interval [lb, rb] such that y - la is divisible by d.
The naive approach would be to iterate from lb to rb, but this is very slow in the worst case. But if one calculates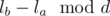 one can see how many steps are needed to achieve a
one can see how many steps are needed to achieve a 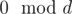 .
.
Once this y is calculated, as we pointed at the beginning of the comment, one has to calculate the minimum between ra - la + 1 (Alice's length) and rb - y + 1 (the "remaining" part of Bob's interval).
Of course, then one has to proceed interchanging the roles of Alice and Bob, and then print the maximum of the two calculated values.
" ...the congruence has to be solvable, which means that d = gcd(ta, tb) must be a divisor of y-la" . How did you reach this conclusion about d ?
First common point in two ap.
https://math.stackexchange.com/questions/1656120/formula-to-find-the-first-intersection-of-two-arithmetic-progressions
Thank you very very much. :)
Thanks. :)
I understood the whole idea but just need a little bit more clarification over the line
"if one calculates one can see how many steps are needed to achieve 0 % d"
Can you please tell me that it calculates the smallest y that is in the range [lb,rb] such that d|(y-la) ??
i.e. y=(lb-la)%d ?
if (lb - la)mod5 = 2, it needs 3 steps to make ((lb + 3) - la)mod5 = 0
Should there be the word "multiset" in the problem E statement?
Can someone explain the O(log N) solutions for C some people had?
I'm not sure I can explain, but maybe you're wrong. in the analysis told the solution for log (N) (gcd works for log)
Oops yeah gcd works in log N... still I meant the solutions that for example the top 5 people submitted, they don't look like the solution explained in the editorial
Can someone post a more detailed solution of problem D ? I am still not able to catch the core idea to crack the problem...
Sorry if the analysis is a bit unclear. I can give some example:
Suppose you need to rename variable "ababaca" to "abcbdca". The core of the replacement is "aba"-"cbd". If this is the only variable that you need to change, you may expand the pattern to the left ("ab") and to the right ("ca").
If you have another variable "cbabacaba" that you need to rename to "cbcbdcaba", then the right expansion may remain the same (because in this variable there is also "ca" to the right of the core), but to the left you need to shorten your expansion to "b". So now after this your replacement pattern looks like "babaca"->"bcbdca".
Thanks for replying. Please edit 2nd variable replaced name as "cbcbdcaba" instead of "bcbdcaba". What would be the proceeded approach in case where you had one more variable "babaca" with replacement same as original string that is "babaca"?
On the first pass if you encounter the variable that does not need to be renamed, then you just skip it. Later when you verify that you found the solution (the second pass) you will of course need to check that this variable doesn't match the pattern that you constructed.
Cool...I got it...Thanks
Here is a more intuitive and simple explanation for solution to Problem C which i found after struggling for a day,
Pre-requisite : Understand what we have to do
First of all, if one can make an Alice's interval and a Bob's interval coincide (in the sense that both begin in the same number) then the answer is just min(rb - lb + 1, ra - la + 1) (the length of the shortest interval).
However, this may not be possible. Sometimes it isn't possible for them to perfectly overlap ever(think about it, if you don't get it, continue reading anyway).
We intend to choose lucky intervals(one of alice, one of bob) so as to minimise the difference of the start points of the intervals of alice and bob. Now convince yourself that this will give maximum intersection.
Now the easier part, the solution :)
Consider the start points of two general intervals (one of alice, one of bob).
For alice, start point of general lucky interval is : la + k1 * ta
For bob, it is : lb + k2 * tb
Difference of start points, diff = lb- la + (k2 * tb) - (k1 * ta)
Now, I want you to focus on last two terms of the above expression, they are : (k2 * tb) - (k1 * ta) where k1, k2 are general integers. That's a linear combination of t1 and t2 which always happens to be a multiple of gcd(ta, tb). In fact any multiple of gcd(t1, t2) can always be written as a linear combination of t1, t2(see Bezout's lemma for both these facts).
So we can say that the difference is of the form :
diff = lb- la + k * gcd(ta, tb), where k is yet another integer.
We intend to minimise the absolute value of diff; so we solve the equation, diff = 0(minimise diff) for k. (Note that it may be not be possible for integer value of k, i'm coming on it)
We get after rearranging,
k = -(lb- la) / gcd(ta, tb) (Don't do integer division here).
Of course, since diff = 0 isn't always possible because the start points of alice and bob may never overlap. So this k we have here must be calculated as a float value (use long double), its floor and ceiling are two integer candidates one of which will make the diff value minimum.
So with ceil(k) and floor(k), we obtain two different diff values. For both of these diff values, we calculate the intersection length of intervals [la;ra] and [la + diff; la + diff + (rb — lb)] and print the maximum intersection length for two diff values. (If you don't get this last part, think about it, it's easy, you can ask if you don't get it)
You can refer to my solution here. 45568612
Thank you so, so much — this was helpful, I think I finally have an understanding of the problem.
If you are aware, can you recommend a few more problems on Bezout's lemma? It is the first time I have encountered this topic, and I would like to practice it more.
Thanks for your briefs. However, even this ceil/floor trick works here (and lot of other places), i think it isn't required and we can do it neatly in one computation. It would be great if anyone can tell how to do it? My implementations are getting WAs.
I believe it would be possible. One approach i thought was to binary search for this k(linear search might timeout). But it was adding extra complexity and extra debugging required. If anyone has a neater way, please share it.
L = L%gcd(ta,tb)
Shift R values accordingly
And then you can choose k for ta or tb from [-1, 1] which is 9 configurations in total
https://codeforces.me/contest/1055/submission/45572634
Sorry, I might be blind, but where does it say that any multiple of the GCD can be written as a linear combination? Thanks!
Write Bezout's identity, multiply any constant you want to both sides, you should have a multiple of gcd on one side; on other side distribute the constant. I think you will see it.
Can someone please explain how exactly can a trie be built implicitly for question F. I haven't had luck in finding implicit implementations for tries online. A link to an explanation will do too.