


Hello, Codeforces!
We are going to host a new contest at csacademy.com. Round #79 will take place on Wednesday, May/09/2018 15:05 (UTC). This round will be a Div. 2, affecting users with a rating below 1800.
Contest format:
- You will have to solve 5 tasks in 2 hours.
- There will be full feedback throughout the entire contest.
- Tasks will not have partial scoring, so you need to pass all test cases for a solution to count (ACM-ICPC-style).
- Tasks will have dynamic scores. According to the number of users that solve a problem the score will vary between 100 and 1000.
- Besides the score, each user will also get a penalty that is going to be used as a tie breaker.
About the penalty system:
- Computed using the following formula: the minute of the last accepted solution + the penalty for each solved task. The penalty for a solved task is equal to log2 (no_of_submissions) * 5.
- Solutions that don't compile or don't pass the example test cases are ignored.
- Once you solve a task you can still resubmit. All the following solutions will be ignored for both the score and the penalty.
Don't forget to like us on Facebook, VK and follow us on Twitter.







This round featured easiest D ever, a simple simulation AC'ed in 124ms!
That's because tests were incredibly weak. If you did the same I did, it will time out with proper test set. Depending on your algorithm, either of the two following test cases will time out.
I strongly believe that you are wrong.
Both of these test pass extremely quickly for the solutions you call slow.
For example, if you just check whether for each group whose representative is contained in the query, exist all the other people in that query and also just continue if the size of the group is greater than the size of the non-representative people in the query, in the worst case the algorithm will run in a linear square rootish complexity.
If you however still disagree with me and think you are right, prove me wrong and post a case with all the constraints less than say 9, for which the solution above would've actually been quadratic. This should be a non issue for you with your confidence.
I'm anxious to read official solution for problem D. All solutions I checked time out with a proper test case, even those from the top of the scoreboard.
For example, Benq's solution fails with this case...
Every query can be processed with sqrt dec.
Let S be the set of bands that have its representative in the query. Only bands in S can be disolved.
The idea is to keep the number of members of every band in S.
Let's call a person heavy if it belongs to more than sqrt(1e5) bands. Note that there can be at most sqrt(1e5) heavy people. So we can iterate over every band and remove all its heavy members given in the query.
For light people we can just iterate over all the bands to which he belongs.
So, top of the scoreboard is top-1.
Sqrt-decomposition on the size of the query. If the size of the query is less then B, then check only those groups, whose representative is deleted, and if the size of the group is greater than the size of query, than it certainly cannot be deleted. Query of size sz is processed in O(sz2) time, total time is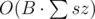 . Otherwise, just check all the groups.
. Otherwise, just check all the groups.
Also you can see that second solution isn't necessary, because first one also works in that time.
You don't write validators or what? How can it be that tests were incorrect?
Please forgive setters for having a weak mind :)
On a more serious note, that ussually happens when setters doesn't use a good tool like polygon ...Sometimes constraints change and you forget to run validator again
For C my solution gave 1 2 3 4 10 9 8 7 5 6 for test case 4 (10 14) which is correct but still it says incorrect. :|
The question requires the permutation that is the smallest lexicographically. In this case, there is a lexicographically smaller permutation: 1 2 3 4 9 10 8 7 6 5.
Will the editorial be posted? I haven't seen any editorial in this contest