


Hi everyone!

Tomorrow, on the April 25-th, 2018 at 17:35 UTC we are holding Codeforces Round 476 (Div. 2) [Thanks, Telegram!]! The round will be rated for the second division participants, members with higher rating can take part out of competition.
I give the floor to MikeMirzayanov to announce the round:
This round opens a series of thanks-rounds to those who significantly supported Codeforces in the crowdfunding campaign for the 8th anniversary. Although Telegram is not explicitly present on the list of donators, for us this is the first and most important friend. We express our gratitude to Telegram and personally to Pavel Durov for the constant support and send regards from programming contest community. Now that the medieval inquisition against Telegram and all the free Internet has been declared in our country, I admire and express support for Pavel's principled position on protecting our rights and freedoms. Thank you, Telegram!
I join the thanks to Telegram, and also want to thank FalseMirror and Livace who helped me with the problems for the round. Also many thanks to vintage_Vlad_Makeev, GreenGrape and 300iq for their help in round preparation, and arsor for translation.
Good luck!
Congratulations to winners!
Div. 2:
- Akylbeek — solved all problems!
- kolkulator
- reeWorld
- 16bit075
- teamskiy
Div. 1:
The analysis is here.







Codeforces Div-2 Rated Contest after more than a week. Now, It's like oxygen for me.
How many problem will be there?
C'mon It's Bayern vs Real Madrid tomorrow, move that round one/two hours earlier please :(
I agree, why the unusual time anyways?
CS Academy Round might be the reason.
Real will win because it always bribes the referees. Any self-respecting people shouldn't watch this match.
cmn, are u really believe in that ?
Yes
I even have a video
After today's game I doubt tomorrow's will be half as interesting
Isin't it obvious Liverpool will win the champions league this time ?.
Thanks Telegram!
Thanks Codeforces!
I started to feel bad for my hair
don't worry
HAHA I was just kidding :)
Here it says contest time is 17:35UTC, but on the contest page it says 12:35UTC. Is there something I am missing?
Might be a timezone is wrong when creating a link. That should be Moscow time which is https://www.timeanddate.com/worldclock/fixedtime.html?msg=Codeforces+Round+%23476+%28Div.+2%29+%5BThanks%2C+Telegram%21%5D&iso=20180425T2035&p1=166&ah=2
Not a good time for East Asia participants.
Yeah, I'm in China and I didn't take a close look at the lime when I registered. Then I realised it actually starts in midnight (1:35 in the morning). I mean, come on, you wouldn't expect me to stay up for 6 hours just for a contest?? I need to go to school too...
I know I can start a virtual contest, or I can just solve the problems in the problemset, but I've never participated in a CF contest before and it should be my first one if it doesn't start in midnight :(
just sleep first and set an alarm =.=
HF & GR...
This round opens a series of thanks-rounds
No time to sleep!
It's 2:30a.m in Bangladesh !
Isn't it 11.30PM? Your time zone is UTC+6, right?
Yeah! But aforementioned link shows 2:30a.m !
The link shows time converted from 20:35 UTC. Perhaps the author edited the text appeared in the blog entry, but forgot the link, by mistake.
KAN, perhaps you should have a look.
It seems now the link is correct. Contest starts on 17:35:00 (UTC).
It is correct now.
Thanks for the response!
Wow,3 awesome things in one day(Avengers:Infinity war,Read Madrid vs Bayern and round #476).
Remembered a good old song "Telegraph".
I heard that Russia is forcing out Telegram. But seems not every guy agrees to do so...
Every contest is very late for me in China. I have been stayed up late for about five times to enter the contests and always felt sleepy... (And this contest is later than usual)
However, I think the contests is very good for me and it improves my coding a lot! Thank to Codeforces!
How many problems will be there?
Most likely 5, unless they will mention something else
It would be nice if you posted no of problems and score distribution :)
Now that the medieval inquisition against Telegram and all the free Internet has been declared in our country, I admire and express support for Pavel's principled position on protecting our rights and freedoms.
Is that safe to say?
[Thanks, Telegram!]
It is so tiring for staying up late.
how to solve C?
What I did was for each value d between 1 and D, calculate with binary search minimum x such that there won't be more than d "rounds". Once I know that value, do another binary search to find maximum x such that there will be exactly d rounds. With that value I'd get x * d candies. Keep the maximum among them all.
Notice, than d <= min(n, 1000), so we can do like this: for(int i = 1; i < d; i++){ cnt = i * k + 1 — how many people will get candies, i — amount of cycles we make (+1 — Arkady) x = n / cnt — how many candies will get each person if(x > m) continue; answer = max(answer, x * (i + 1)); } if(d == 1) cout << m; else cout << max(m, answer);
it works on Pretests, but hopefully on real tests to.
:P im sorry man . Congrats on becoming Expert :)
Thank you, man :)
How to solve E?
What's pretest 5 for C? :'(
I guess pretest 5 checks integer overflow.
Can anyone provide me a solution for E?
I'm thinking of Trie and some greedy sorting for the string list, but not very sure about the accuracy of this approach...
Trie and BFS failed
I tried to hack myself but failed.
Can you give a counterexample?
5 aba ac aca acaa acaaa
I sorted the strings based on their length and used a greedy approach using trie. Can you plz tell bug in this method. Thanks in Advance.
i wish i knew
You can make trie and use multiset for saving all current depths for answers (initially each depth is equal to string length). After this, for current node in trie you will try to put some element from its subtree ( make some prefix shorter than before) — you will put one with biggest depth. For good complexity, you should always merge bigger multiset to smaller. Total complexity O(nlog2(n))
I used long doubles in the third task, I believe it will be enough precise :)
Very nice problemset ! Thank you !
Why putting element with biggest depth will be always correct?
Well I think that is really easy. You will put one with biggest depth becuase it will decrease answer for the biggest value ( I know you are not stupid ). But if you think we could put maybe that one somewhere up in the trie, that is also correct, but actually there is not difference which one is in node x and which one is in node y. Just sum of depths of occupated nodes should be smallest possible.
I know that still I didn't tell you something crucial. But maybe you do not understand my algorithm, I am going down -> up and updating current node with furthest in its subtree.
Sorry If I am unclear, but I do not know to explane better. Somehow it is obvious to me.
not necessary to merge smaller to bigger, because every end of the string occurs in that string only, so total complexity O(sum of words sizes)
Good point !
I spent extra 10 minutes for this :)
What is pretest 5 in C,any idea?
10 2 2 2
It should give 2, but it might give you 6, if you don't check that your x > M.
no that's wrong if x = 2 then number of times to get x > D
because D = 2
I think answer is 4.
M*k*D>=n
there is no such test case
This is the weirdest order I've ever solved problems in. (the reason i failed A was because I set max in binary search as 10 million instead of 100 million)
(the reason i failed A was because I set max in binary search as 10 million instead of 100 million)
Wow, system tests in C got almost everyone!
When you've given up all your hopes, but you returned and realized other people's system test failures gained you nearly 220 additional ranks.
Can someone please tell me where I am logically going wrong in C code
Thank you
The function f is not an first increasing then decreasing function. Therefore you cannot use ternary search.
Actually if you plot it, it looks something like this: link
Thanks Jakube.I will try it once again.
Can anyone please help why this code is wrong on Pretest 4 for Problem A.Thanks in advance http://codeforces.me/contest/965/submission/37614312
If you only put the code inside of your if, I think you'll get AC.
Yes thanks its same but still why? Very discouraging couldnt move forward,why its giving wrong still it will give right..?
You can't put in else: if(ans%p!=0)
Like in if statement, you need some variable to rember ans before you divide
Here is fixed submission for your problem
For B it could be bigger constraints, e.g. n = 500. To let solve it with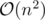 .
.
You could've even solved B with O(n^3) because n<=100
After system alalysis, my C question failed. and I thought it's very easy to implement in python. and so many boundary test cases to be handled in c++ .
But, guess what, Just changing long long to long double , gives you correct answer.
http://codeforces.me/contest/965/submission/37606838
http://codeforces.me/contest/965/submission/37620212
My solution to E: put a priority queue with first element no of tries and then how much do we try to shorten the word. {a,b} If we can shorten the top element on priority queue, then we do it, and we insert {{a+1, 1},shortened_string} back. If we can't shorten the top element, then we insert {{a+1,b+1},string} back. However, it gives WA #7. Can anyone hack it with a simple test case, pls, so I can understand? 37620587