


Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3993 |
| 2 | jiangly | 3743 |
| 3 | orzdevinwang | 3707 |
| 4 | Radewoosh | 3627 |
| 5 | jqdai0815 | 3620 |
| 6 | Benq | 3564 |
| 7 | Kevin114514 | 3443 |
| 8 | ksun48 | 3434 |
| 9 | Rewinding | 3397 |
| 10 | Um_nik | 3396 |
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 155 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 10 | nor | 152 |






for problem D , after an O(N) preprocessing , check(mid) for binary search can be done in N/mid complexity , the worst case would be (N/(N/2)) + (N/(N/4)) + (N/(N/8)) + ... = N/2 + N/4 + N/8 ... = N , so the actual complexity comes out to be O(N) instead of O(NlogN).
Can you please elaborate as to why check(mid) will be O(N/mid)? I'm unable to understand the complexity.
In problem G... We can use interval tree to maintain the sequence , instead of segmenttree. Each node of the interval tree represents a lazy tag. To modify , we firstly split the sequence and then processes the modification. Note that in one split operation , the numbers of intervals only increases by 2. Thus there is no need to use sparse table... This data structure operates at time Complexity O( n + q( log( k + q ) + log( n ) ) And it costs O( n + k + q ) memory.
To achieve this complexity you need to keep your interval tree balanced, for example by using a splay tree. I looked at your submission (26724827) and it seems it will time out on a case such as:
Because the test cases are pretty naive... I passed this problem without maintaining the balance of the tree...
Sorry, I know this is an old post, but can you explain to me the difference between a segment tree and an interval tree? I thought they were the same.
They are the same.
Silly question! Realised my mistake!
Problem A, Python3, TLE #15, 22MBytes. Problem A, the same code, C++ MSVisualStudio2010, AC, 260 ms, 3.6 MBytes.
Welcome to "Python isn't so fast, as C++" club!
For some reason, I WANT to use Python. Probably, because Python fashionable...
Then learn how to optimize your python solutions. If you write it like this, it passes in 400 ms.
I don't see any big differences! http://codeforces.me/contest/803/submission/26727371
You can speed up io by reading and writing directly to streams. Also your answer accumulation works really slow, you create new strings N times and their lengths are big.
For problem D, how do you decide to choose binary search to compute the minimum width? I do understand the code itself, but still have no idea how to pick binary search for this problem.
Choose m by (l+r)/2, try to do text with m lines, if you can m = l, else r = m. So you get answer in l when became r — l <= 1.
Define function f(w) — number of lines you will require if its width is limited to w. This function is monotonous, f(w) ≥ f(w + 1) for every w. And binary search is usually applied to monotonous functions.
Thank you very much. I'll try binary search when I see monotonous pattern in problems.
You can try binary search in this problem.. Try to make an efficient monotonous function here http://www.spoj.com/problems/AGGRCOW/
Can anybody please tell that why in Problem C the GCD of resulting sequence is always a divisor of n?
Let's consider the case when GCD isn't a divisor of n. Let it be some value g. Then resulting sequence looks like x1·g, x2·g, ..., xk·g. Its sum is equal to x1·g + x2·g + ... + xk·g = g·(x1 + x2 + ... + xk). That is divisible by g. The sum is equal to n. Thus n is divisible by g. This lead us to contradiction(? I'm not sure of right word to use).
Thank you very much, i always isn't understand this solution until i get you explanation. Maybe my brain short circuit, hhhhh, thanks.
In problem C why we need to check that n — s > (k — 1) * d? also we need to check that gcd(n-s,d)=d right ?
We need to check n — s > (k — 1) * d, because sequence must be ascending. If this inequation is false, then last number is breaking this rule. There is no need of checking for gcd(n — s, d) = d. If n is divisible by d and all other numbers from sequence, which sum is equal to n, are divisible by d, the last number also must be divisible by d.
I got it, thanks :)
In problem C test:#10, n=24, k=2, answer is "8 16". So, the max divisor is 8 ? But 8 is greater than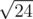 , isn't it a contradiction of the statement in editorial?
, isn't it a contradiction of the statement in editorial?
"Don't forget that you should consider d and n / d, if you check divisors up to square root of n." Maybe, you should get acquainted with fast algorithm to find all divisors.
got it, thanks a lot!
There's like 'didnt want to tnink at all' solution for G.
We can actually build a valid persistent treap over whole range(N * K) — build a treap over given N elements, make K copies of it, merge them. Congratulations, u now have a valid treap with 10^9 elements in it.
Can anyone please further explain the solution to F?
Let's say we have a set S of K elements. The power sets (all possible subsets including null sets is 2^K)
Now for this problem we are given an array a1, a2, ..., aN and here we have to find subsequences of this array such that all GCD is equal to 1.
Let's try all g (all possible GCDs) from 100k to 1. ans[g] is how many possible subsets we can make with GCD in this subset is equal to g. Our answer will be in ans[1]
We now iterate for all possible g, let's denote the number of elements which has GCD equals to g as cnt(g). Then the value of cnt(g) is sum of all numbers of elements which has divisors of g, 2g, 3g, and so on.
The number of possible subsets with GCD = g is equals to 2^cnt(g) — 1 (since we have to exclude null subset). However for some multiple of g, we have already counted before. That's why by using inclusion-exclusion ans[g] value will be equal to 2^cnt(g) — 1 — ans[2g] — ans[3g] — ...
To have a better understanding, you can view my solution Submission
Thanks so much fonmagnus :)
Can someone post good clean solutions for problems A and B in Java? Everything I saw so far was quite tricky and hard to fathom. Thanks in advance!
How to solve E in linear time?
Consider the dpi j table from the tutorial. For a given i, all j such that dpi j are true must be in one continuous segment. Therefore, you can do dynamic programming by storing the min and max of this segment for all i instead of storing the boolean for all i by j
My code (java) might be easier to understand than my explanation: 26787020
Sorry, but I didn't got your explanation, and I got less the Java code. You are saying that for a given i, all the j such that dpi, j are true are contiguous. Let be i = n ; dpi, - k and dpi, k would be equal to true, and for all j such that - k < j < k would be equal to false. Am I making any mistake? Thanks in advance for your clarification
In the dp table, think about how any column relates the the column before it. On a 'W', 'L', or 'D', the true values in the later columns are either shifted up, down, or not at all from the previous column. Similarly, a '?' results in union of these three. None of these operations ever split up a segment of true values into two segments.
You also know that the first column is a single segment of length 1. Therefore, induction tells you every column must be a continuous segment of true values (or all false).
This poor ascii representation of the third example might help
Thanks for your cool illustration, and i finished a linear solution in C++. 26798716
Any suggestions are welcome.
I was able to do greedy in O(n) with a stack (Submission).
From the start, keep a running sum of the score. Treat (W) as +1, (L) as -1, and ignore (D)s and (?)s.
At any point, if the score becomes k or -k, assign the nearest (?) to a (W) if score=-k, or (L) if score=k. Here, you can keep track of the nearest (?) by using something like a stack.
Now be careful, after changing you'll have to slide the whole window after that (?). If the shift will make a part of the score still hit k or -k, then output NO. Otherwise, keep going.
Now once you reach the end, we'll need to make the score k or -k so we simulate both options. Making use of the stack of (?), to target score=k, we assign the last k — score unknowns as (W)s. The remaining (?)s can be (D)s. Similarly, do it for (L) with score — (-k) unknowns. Check if it still satisfies everything, then we can output either working answer (otherwise, output NO).
EDIT: Thanks to @xurz97 for pointing out that a bug in my previous submission. The logic is still correct, but please refer to this submission link instead
Can someone please explain the use of the mobius function for problem F?
In problem C, I could not apprehend, how we reach described solution. And, why does it give us best answer ? Could someone explain me ?
We're trying to maximize a the GCD of a (positive strictly increasing) sequence of length k that sums to n.
Consider any sequence that has a GCD greater than 1:
Note that if a sequence has a GCD > 1, we can factor that number out:
Because we can factor this number out, n (the sum of the sequence) must be divisible by the factor.
Also note that the smallest possible sequence of length k, {1,2,...,k}, sums to k*(k+1)/2.
We can combine these two observations in the following way.
Below is an example:
Consider the input "12 3"
I hope that helps!
Here is another practice problem to apply the idea from problem F: http://codeforces.me/problemset/problem/439/E. This problem requires the same idea used on problem F plus some knwoledge about stars and bars formula. Hope it can be useful for those who want to become better :)
Could you please explain problem G in details. It is pretty hard to understand. And is there any code example? I didn't get how to build the tree, what whould represent sparse table. Please, help me
My AC submission for G
WA with a smaller tree
I made a segment tree that is somewhat "persistent" for the initial period, and I thought that the memory complexity should be around O(Qlog(NK)), yet instead I had to allocate much more memory for my solution to pass. Now I wonder if I had a wrong bound or I just underestimated the constant factors. Would anyone mind prove the memory complexity for me?
Many thanks in advance.
In problem C, in test case #21, my output sequence gcd is 3 and it's clearly increasing, the checker says my gcd is 1, perhaps I missed something! 26808542, I also submitted a very close version to the editorial binary searching among the divisors of N and it passed! 26809758
So what's the problem?!
In submission 26808542 your output is 500000003 1000000006 1500000012. 500000003 is not divisible by 3 so clearly your output's gcd is not 3. Further you can check gcd of your output is 1.
Can someone provide the proof of the assertion in Problem C ?
The gcd of k positive integers that sum up to n, is always a divisor of n.
There's an easier way to solve problem F: https://www.geeksforgeeks.org/count-number-of-subsets-of-a-set-with-gcd-equal-to-a-given-number/
Here's my code using this approach: Code
Err, the gcd can be much larger than 1000
Thanks. I think I had linked the wrong article. I have corrected the link to the article and also posted a link to my code using that approach.
thank you!
The editorial for C is unrigorous: how is it possible for a red coder to write like that is beyond me.
Can someone explain the solution to problem F
Why does greedy work for D — Magazine Ad? Can anyone provide a full/half proof?
Think of the first line, suppose by using the greedy logic you decide that you can have n words in the first line. Since greedy is taking as many words as possible, no other solution can have more than n words in the first line. Also, by taking more words, you're leaving fewer words for the remaining k-1 lines. So if a solution is possible by taking more than n words in line 1, it should be possible by taking exactly n also.
The linear solution of problem E,based on greedy. https://codeforces.me/contest/803/submission/156600793