


Could not find related blog. Let's discuss. What's the solution of B?
→ Pay attention
Before contest
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
13:40:34
Register now »
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
13:40:34
Register now »
*has extra registration
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
→ Find user
→ Recent actions






Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Nov/23/2024 03:54:27 (j1).
Desktop version, switch to mobile version.
Supported by

Auto comment: topic has been updated by dragoon (previous revision, new revision, compare).
Apparently it's 1 if graph is bipartite, otherwise 0. But we have no clue why.
Let's choose a subset of edges, and then color each vertex black and white. If u and v are connected by a chosen edge, they must be colored with the same color. Also, vertex 1 must be colored white. How many ways are there to do this?
Suppose that we fix the set of edges. Then, the number of valid colorings is 2components - 1 and this is odd only when the entire graph is connected. Thus this is what we want to compute.
Now let's fix the coloring first. In this case, the number of valid subset of edges is odd only when the coloring is a valid bipartite coloring for the entire graph.
Could you explain the second item in detail?
Also the notion of the characteristic polynomial of a graph helps a lot. We can say that if we fix some edge, each good subset either doesn't contain this edge (their number is the answer for the same graph but without this edge) or contains it (their number is the answer for the same graph but the endpoints of this edge are considered the same). The characteristic polynomial is built just like that, but there we subtract instead of adding, which is the same modulo 2. Finally, we know that the number of ways to paint vertices of a tree in 2 colors is 2, so we can just look at the number of ways to paint vertices of the initial graph in 2 colors modulo 4: it's either equal to 2 (then the answer equals 1, and this happens iff the graph is bipartite), or equal to 0 (otherwise).
"what is the intuition behind this fact? How to come up with it without knowing it in advance? I would be grateful if the readers could shed some light here." — ok, so here's how we derived the answer, not just proved the guess (more specifically Marcin_smu did it). Strategy was very similar to the solution of problem C2 from that Petrozavodsk. If one knew solution to that problem this one was much easier.
Consider bad subsets of edges. For bad subset of edges we can divide vertices into two groups (A, B) so that there are no edges between them. We will count such triples (bad subset of edges, A, B), where (A, B) is partition of V and first vertex belongs to A (otherwise everything would be even trivially). But hey, if graph with our subset of edges has more than two connected components there is more than oen way to divide connected components into A and B! But if there are k of them then there are 2k - 1 - 1 ways to do so, which is always odd! So our answer is equal to number of such triples! But if we fix A and B first then there are 2e bad subsets of edges corresponding to them, where e is number of edges within A and within B in total. But this is almost always even. Only case when it is odd is when A and B are independent sets, or in other words if our graph is bipartite :). Since our graph is connected there is only one way to partition its vertices into two independent sets, so we are done.
Maybe a bit more complicated than Makoto's proof, but that's how you can come up with it not knowing answer in advance.
Thanks — it makes more sense to me now. The 2**(k-1)-1 part, where the magic happens, does arise from a reasonable consideration!
C. https://apps.topcoder.com/wiki/display/tc/SRM+527 This editorial (P8XCoinChange) gives a big hint.
D. After some calculation on paper it turns out that we need to compute the following: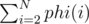 ,
, 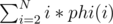 ,
, 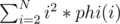 . I believe this is solvable if we pre-compute these values when i is divisible by 100000 and paste it into the code.
. I believe this is solvable if we pre-compute these values when i is divisible by 100000 and paste it into the code.
C: Duh, that SRM's editorial is so long :P. What I did is very similar to what is described here: http://petr-mitrichev.blogspot.com/2015/10/a-week-with-sheafs.html (probably similar to what is written on TC, however much shorter), however my solution has complexity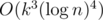 and at first it took my code 100s to complete maxtest, whereas TL was 2s. Using some weird optimizations I fortunately made it to pass :p. However I have heard that there is a solution in complexity
and at first it took my code 100s to complete maxtest, whereas TL was 2s. Using some weird optimizations I fortunately made it to pass :p. However I have heard that there is a solution in complexity 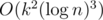 , but I couldn't understand it at problem analysis.
, but I couldn't understand it at problem analysis.
D: I am not sure it can pass by using preprocessing. We had that idea, but there are some problems with this approach. Note that there are 100000 testcases. Moreover we need to compute those phis (that comes with log log n factor to complexity). We can do something a bit more clever and preprocess points of form k3 instead of k·100000, but it is still shaky. Maybe it will pass, maybe not, but this task still has a solution not using "preprocessing cheating". Computing those sums boils down to computing prefix sums of μ(i)·ik for k=0,1,2 for some specifics points. I didn't figure it out to the end, but I think main ideas are contained here: https://www.mimuw.edu.pl/~pan/papers/farey-algorithmica.pdf or in editorial to Four Divisors problem: http://codeforces.me/blog/entry/44466
It is very surprising that the number of primes up to N can be computed faster than O(N). My thinking was like: the sum of phi(i) is closely related to the distribution of primes, most probably it can't be done faster than O(N), so it must be some pre-computation.
Compute sum{phi(i)} is different from number of primes up to N since they are Multiplicative function.
These sub-problems are well known in China and they can be solved by "sieve of jqdai0815". I couldn't find articles in English, but I know this one in Chinese is good: http://blog.csdn.net/skywalkert/article/details/50500009
The method the problem setter used in C is from here -- Summation by parts.
For two given sequences (an), and (bn),, with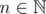 , one wants to study the sum of the following series:
, one wants to study the sum of the following series: 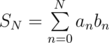
If we define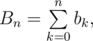 then for every n > 0, bn = Bn - Bn - 1, and
then for every n > 0, bn = Bn - Bn - 1, and
The method can be applied in the following way:
For the m-th power partition,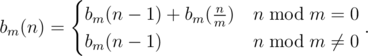
For the k-th convolution power of the m-th power partition, the k-th order forward difference is: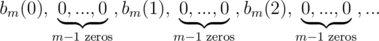 .
.
Taking k = 1 as example, let an = bm(n), bi = 1, we have
As $a_{n} - a_{n-1} = 0$ if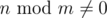 , otherwise
, otherwise 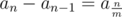 , we can reduce n to
, we can reduce n to 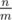 . And apply this method again and again, we can reduce n to a trival case n = 0.
. And apply this method again and again, we can reduce n to a trival case n = 0.
For large k, we need to apply this method k times to reduce n to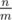 .
.
D can be solved in O(n2 / 3) as described here
Thanks for link to clear explanation. However, for the sake of completeness, complexity analysis is a bit off, because it doesn't take into account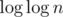 factor coming from Erathostenes' sieve. It is
factor coming from Erathostenes' sieve. It is 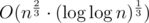 (if done carefully), as in both places I mentioned as well.
(if done carefully), as in both places I mentioned as well.
In fact,phi(1)..phi(n) can be calculated in O(n) using sieve(I don't know its English name),whose main idea is to calculate phi(i) using its minimum prime divisor.After this preprocessing we can make "xudyh sieve" O(n**2/3)
Any easy solution to F?
Divide rectangles on left and right and sort them by
b. Then calculatedp[i][j]as maximum weight when upper left rectangle isleft[i]and upper right —right[j].It can be computed in next way:
If
left[i].a > right[j].athendp[i][j] = left[i].weight + max_over_k(dp[k][j]), whereleft[k].b < left[i].a. Otherwise same logic but withright[j].Use two additional maximum_on_prefix_dp and it will be O(N2).
How to prove greedyness in G?
How did you solve it?
One can prove two observations:
Observation 1. If one panda is already assigned — the problem can be solved greedily.
Observation 2. Given optimal assignment of pandas one can transform it to another optimal one such that there will be a panda which maximally gives its donuts either to left or right one.
Now we need to find such a panda (intuitively it will be the one with minimal allowed deviation).
The criteria we used was the following: minimal difference between optimal left and right packing (one panda) and minimal b[i] + b[i+1] — a[i]. Stress-test did not find any testcase it fails at.
Where I can read the problems?
How to solve div.2 M? Can't understand task.
Anyone A, H, I?
I: Theorem: Let T = A·B with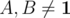 , and let Y be a subtree of root(B) with maximum number nY of vertices. Then the subtrees of root(B) are exactly the subtrees of root(T) with at most nY vertices. Proof: Reduction to Absurdity.
, and let Y be a subtree of root(B) with maximum number nY of vertices. Then the subtrees of root(B) are exactly the subtrees of root(T) with at most nY vertices. Proof: Reduction to Absurdity.
Using above theorem you can easily to prove that the factorization is unique.
Compute the hash value of all the subtree, and sort all the subtree according to their size. By enumerating the value of nY, we can find the subtrees of B. Using the hash value to check if this tree is a factor of T. This leads to an O(n·d(n)) solution, where d(n) is the number of divisors of n. By combining with some string matching technique, we can get an O(n) solution.
For problem A.
Apparently, if s is less than or equal to 1010, there is no solutions. Otherwise, we can always find a solution.
If s has d (d > 4) digits, then$\underline{999\ldots 999}898$((d - 4)'s 9 followed by 898, (d - 1) digits in total) is almost bobo. We can use this fact to solve the case where there is no almost bobo number having the same length with s. Now, we can assume there always exists an almost bobo number having the same length of s.
Apparently, the answer has a longest common prefix with s, let's denote it as p. In order to find p, we need to enumerate all the prefix, and check if this prefix can be a solution.
Assume the prefix is s′, we need to append another digit c to s′, in such a manner that c < s(|s′| + 1). Let's call the new string be t (assume the consecutive equal digits are merged). To append some other digits to make t almost bobo, we need find a border u of t (t = uxu, for some nonempty string x), such that |t| - 2|u| ≤ |s| - |s′| - 1 (there are some other small cases, just ignore it for now). So, we should find a u with maximum length, we can call it half border.
As showed in this paper, Efficient data structures for the factor periodicity problem, all the border longer than half forms an arithmetic progression, we can determine the half-border with KMP in O(1).
After finding the longest prefix, we can just append more digits from 9 to 0 to find a largest answer (the rule used above can be used to check if the digit is a part of the answer).
I found dmd-compiler(it is compiler of d-lang), and I use It, but my program are too slow and got TL ... ;( (I can get accept by rewrite it in c++)
Does anyone know the compiler options of judge? I can't find it.
Can anyone publish the problemset?
Yes. http://opencup.ru/files/och/gp11/problems1-e.pdf