


Здравствуйте все!
Возможно, некоторым уже известно, а некоторые забыли или даже не знали, что в ближайшее воскресенье (27 мая 2012 г.) в 11:00 по Московскому времени состоится первый квалификационный раунд RCC 2012.
Задачи обещают быть хорошими, а борьба, надеюсь, будет жаркой, вне зависимости от того, что это только квалификационный раунд.
Я думаю, что не будет лишним написать ещё раз ссылку — Русский кодо-кубок.
Желаю удачи на раунде.
Член жюри.
Председатель жюри : andrewzta.
Координатор задач : Joshik.
Раунд подготовили : Павел Кротков pashkal, Николай Ведерников Niko, Андрей Комаров komarov, Демид Кучеренко BLIZZARD, Владимир Ульянцев, Антон Ахи anton.akhi и Aksenov239.
Помогали в подготовке : Антон Банных anton.bannykh и Владислав Исенбаев winger.
Опубликован разбор задач: http://russiancodecup.ru/round/6/analysis
Если кому-то хочется посмотреть на доказательство равенства простых — http://codeforces.me/blog/entry/4625#comment-94117.
P.S.: Если что-то не совсем понятно в правилах пишите в службу поддержки — http://russiancodecup.ru/feedback/.







Какая разница, квалификация это или нет, если тут футболки разыгрываются :)
Хотел уточнить. Можно ли в квалификации участвовать, если тебе нет 18 лет?
Да, может есть возможность поучаствовать вне конкурса. Как-то я на сайте ничего не увидел об этом. УПД: не умею читать.
Там в одном месте написано, что для участия во всем чемпионате нужно, чтобы было 18 лет, а в другом написано, что такие участники будут сниматься только с финала. Так чему верить?
http://russiancodecup.ru/rules/ — смотрим аккуратненько первую часть.
"Данные ограничения не распространяются на участников онлайн-туров, но в случае несоответствия требованиям такие участники не допускаются до финала."
Верить надо тому, что курсивом.
Спасибо. Может стоит добавить эту информацию сюда : http://russiancodecup.ru/agreement/
Об этом уже поставлено в известность.
А сколько длится раунд ?
Ы.. как-то глаза два раза проскакивали мими блёклого шрифта =(
а тыкнуть по ссылке нереально сложно?
Русский кодекс-чашка
Alex_KPR рискует своим первым местом среди лидеров по вкладу
Alex_KPR абсолютно не переживает по этому поводу :)
Посмотрим, как он заговорит, когда его обойдёт JKeeJ1e30
примерно после десятого RCC;)
Как-то непривычно видеть Alex_KPR заминусованным...
Это еще что, там пятью комментариями выше заплюсованный JKeeJ1e30.
Мне кажется, это уже флешмоб организовался по его заминусовыванию — семь последних комментариев в минусе.
В прошлом году футболки были на 2 размера меньше, чем на них написано...
У меня L и она действительно L.
у меня XL маловата
но, надо отдать должное организаторам, на онсайте можно было получить футболку нормального размера
Они просто были slim cut
А кто-нибудь недавно регался? Я имею ввиду ближайшие пару дней. Просто когда я регаюсь у меня всегда вылетает ошибка "Неправильно введены цифры с картинки". Вдруг еще есть те, кто не прошел регистрацию, как я :) Как вообще сообщить организаторам об этой проблемме? Есть раздел "Обратная связь", но там опять же эта картинка с цифрами... UPD: нашел мыло [email protected]. Сейчас напишу UPD2: на это мыло письма не доходят. Вопрос остается
Зарегистрировался вчера без проблем.
Попробуй с другого браузера.
У Chrome это известная проблема, если попробовать Мозиллой, то всё должно получиться.
Интересно, я один увидел красивое предложение о приближающемся соревновании, в котором нет сказуемого)
Глагол то есть, а вот сказуемого нету :)
Не менее красивым образом это предложение поправили:
...состоится первый квалификационный раунд RCC 20212.
Напишу сюда.
Мне непонятно в правилах, почему в пункте 14 в предложении "Компиляция должна завершиться в течение 30 секунд, компилятор может использовать при компиляции более 512 мегабайт памяти." отсутствует частица "не" перед "может".
В соответствии с рекомендацией в посте, использовал ссылку "обратная связь", но понимание не пришло.
аналогичное делал несколько месяцев назад на этот же пункт
Дизайн футболок в этом году изменится? :)
Интересно, насколько вырастет конкуренция в этом году, по сравнению с прошлым. В прошлом все как-то с вялым интересом посмотрели на этот контест, с его организацией квал, картинкой с регламентом, проблемами с регистрацией и все остальным... А потом смотрели онсайт с открытыми ртами :)
Подозреваю, что в этом году простым смертным попасть на онсайт будет намного труднее.
Кстати, по поводу дизайна футболок. Есть подозрение, что в этом году его кардинально поменяли. Судите сами по изображению на странице соревнования. Вместо уродливой и некрасивой цифры 1 (спереди внизу футболки, сбоку от числа 201) теперь будет красивая, приятная для глаза и более подходящая по дизайну цифра 2.
А ссылка на интерфейс участника где и когда появится?
Когда начнется. Появится в меню слева.
Нормального обратного отсчета нет >_<
Интересно, я один такой везучий, что зашел в веб-интерфейс через 5 минут после старта, подтвердил участие в RCC 2012, стал отображаться в интерфейсе как участник, написал A, стал ее сдавать, получил длинное красное сообщение об ошибке, написал об этом жюри, написал C, стал ее сдавать, получил такое же длинное красное сообщение, снова написал жюри, т. к. на первое сообщение они не ответили, продумал B, начал писать, и получил сообщение от жюри следующего содержания: "Дмитрий, если вы подтвердили участие после начала, вы, к сожалению, не можете принять участие в раунде"??
Пожалуйста, покажите мне пункт Условий, где сказано, что для участия в раунде необходимо зайти в интерфейс до его начала, учитывая, что всем участникам RCC 2011 12 мая пришло письмо, где была строчка "Тем, кто уже регистрировался в прошлом году, достаточно войти под прежним логином и подтвердить участие", откуда следует, что я автоматически зарегистрирован.
В любом случае, согласитесь, странно, что в интерфейсе я отображаюсь как участник, но сдавать не могу.
Ненавижу e-maxx!! почему не работает поиск мостов у него на сайте.
МБ потому что у Вас руки кривые? Тут e-maxx не виноват.
Поиск мостов правильный. У меня тоже руки кривые, 70 минут дебажил ошибку в одной переменной. Видать, наказание за копипасту.
Кстати, поиск палиндромов там неправильный, в комментах написано какой должен быть правильный код, а в самой статье вроде бы до сих пор не исправлено.
я не нашел в правилах ничего про prewritten code, кроме "Во время раунда участникам разрешается пользоваться любой литературой и личными записями, а также заранее заготовленными программами".
Интересно, это относится к заготовленными не тобой программами?
А ещё в правилах можно найти "Участникам запрещается общаться на темы, связанные с задачами, с кем бы то ни было, в том числе с другими участниками". Что, на мой взгляд, включает в себя давание существенных подсказок по решению задачи во время контеста.
А я по памяти написал :-p
Немного странный интерфейс: посылаешь задачу, в мониторе через некоторое время показывается минус по ней... а еще через некоторое время он становится плюсиком (если повезет :)).
А в списке задач в это время "1 попытка в очереди".
И вот сидишь-гадаешь, минус по ней, или все-таки плюс — тестируется долго...
А ещё в последней колонке у всех крестик. Сплошной пессимизм.
Тоже на этом попался — посмотрел что минус, начал дебажить, минут 5 потратил, а потом обновил страницу и удивился)
Мы приносим извинения за этот баг, поздно заметили и не успели исправить.
Не знаю, не померещилось ли мне, но я во время контеста видел сообщение "-1 попытка в очереди" по задаче, которую я уже сдал :)
У меня тоже было. Вместо +1 попытки по другой задаче.
что за третий тест в В? О_о
UPD после коммента Anton_Lunyov понял, что нагнал по полной в подсчете в случае 1 компоненты.
спасибо авторам за задачу Е, позволила не пролететь))
в моем решении были всякие случаи с количеством компонент связности в первоначальном графе.
если > 2 — ответ точно 0. если 2 — одно решение, если 1 — другое решение.
может, в этом?
как решать, если одна?
Если одна компонента — то ответ это два слагаемых. Первое это произведение всех имеющихся рёбер минус количество мостов на количество отсутсвующих рёбер( n*(n-1)/2 — m) . Второе слагаемое это сумма по всем мостам, произведения количества вершин с одной стороны моста на количество вершин в другой минус 1(сам этот мост).
Считаем число мостов, для каждого моста считаем количество вершин в одной из двух компонент, на которые граф распадается после его удаления. Тогда ответом будет (n*(n-1)/2 — m)*(m — k) + сумма по (n-r[i])*r[i] — 1 для мостов, где k — число мостов, а r[i] — число вершин в одной из двух компонент.
а как для каждого моста быстро посчитать кол-во вершин в двух компонентах, на которые распадается граф?
В DFS, который вычисляет мосты, можно поддерживать размер текущего поддерева.
В dfs-е, где ищем мосты это делается добавлением пары строчек — пусть dfs возвращает нам число вершин, которые посетил, тогда если мы нашли мост, то просто берем это значение от dfs-а, который мы вызывали от вершины, в которую ведет этот мост.
Пусть вначале удаляется не мост, тогда один вариант
(n*(n-1)/2-m)*(m-cnt)где cnt — количество мостов. В случае удаления моста: разобьем граф на компоненты реберной двусвязности и построим такую конденсацию. Это будет дерево. Для каждой вершины этого дерева храним размер поддерева (динамикой посчитать можно). Ну и понятно, что к ответу тогда приплюсовывать.Можно проще, возвращать из dfs-а количество посещенных вершин, если ребро (from, to) — мост, то dfs(to) возвратит размер одной из компонент.
(n*(n-1)/2-m)*(m-cnt)вот так вроде.Да, точно. Спасибо.
Ищем мосты, выделяем компоненты реберной 2-связности. Можно удалить любое внутрикомпонентное ребро и добавить совсем любое. Можно удалить любой мост. Тогда граф разделится на две компоненты связности. Можно добавить любое ребро между ними, кроме только что удаленного моста. Считать кол-ва вершин в получившихся компонентах можно, сжав граф в дерево (вершины — бывшие компоненты двусвязности) и посчитать на нем кол-ва вершин исходного графа в поддеревьях.
Ну у меня также, да. Вроде попроверял разные тесты вручную, проходит. Вообще не могу понять в чем бага
UPD понял)
У меня также, причем если 1 компонента, ТЛьной решение пытался сдать, в итоге ВА3
Мб, что-то такое?
6 5
1 2
2 3
2 4
4 5
4 6
Ну там есть три принципиальных случая. Граф связный, граф с 2 компонентами, граф с больше чем двумя компонентами. Во втором случае надо не забыть, что нельзя удалять мосты. А добавлять надо понятно что. Что из этого забыли, смотрите сами.
как решать, если граф связный, а конкретно, при удалении мостов?
Динамика на дереве двусвязных компонент.
Ответ в этом случае такой: (m - k) * (n * (n - 1) / 2 - m) и плюс сумма всех bi при i = 1..k (k — количество мостов), что bi = qi * (n - qi) - 1, где qi — количество вершин по одну сторону от i-го моста.
Вообще говоря, последнюю сумму не очевидно как быстро решать (ну собственно Anton_Lunyov уже написал
да-да, я над этим и просидела :(
http://ideone.com/7h9Pt , функция dfs1, isB — по паре возвращает bool — ребро мост или нет
Один dfs, который возвращает количество вершин в дереве. Тогда при проходе по ребру смотрим: если ребро — мост, то прибавляем к ответу qi * (n - qi). Вроде бы довольно очевидно.
Ага, вот сейчас прочитал, и стало сразу очевидно:(, сам че-то не придумал.
В том же DFS'е где ищутся мосты запихать ещё и подсчёт количества вершин в этом поддереве.
Правильно ли я понимаю что ответ либо (2 2 3), либо (2, 2, 5), либо (3, k, k + 2), либо (3, k, k + 4)? И, если это так, то в чем еще можно накосячить?
ответ (p, p, 2p ± 1). Чисто экспериментальный факт. Почему других не бывает не знаю.
ответ (p, p, 2p + - 1)
UPD набросок доказательства: d1 + d2 = d3 + - 1, далее подставляем d1 + d3 сравнимо с + - 1 по модулю d2. Получаем, что либо d2 = 2, либо d1 = d2, либо d1 + 1 делится на d2. Аналогично либо d1 = 2, либо d2 = d1, либо d2 + 1 делится на d1. Получаем d1 = d2, ну и подгоняем d3.
Вообще-то уже можно скачать тесты. Третий тест какой-то большой.
У меня из-за отсутствия long long'ов падало на 3ем
Третий тест в В это вроде как 40 полных графов из 100 вершин, соединенных в одну цепочку. На нем действительно очень многие падали еще и на прорешивании.
Прикольно, дали штрафу за послыку ПОСЛЕ AC :)
UPD: сняли
Хорошо, что ещё AC не сняли, а только штрафу дали! :)
После него шел еще 1AC :)
То приятное чувство, когда все вокруг сдают задачу, а у тебя нет никаких идей по ней... Как решать С?
заметим, что невыгодно брать подпоследовательности длиной более 3
А что за тест 2, просто я так и не смог придумать тест который валит динамику.
А его и нет. Динамику валит переполнение на 10-м тесте, если я правильно понял, о чем вы.
Странно, у меня так и не вышло подобрать не рабочий тест. Может есть какие еще подвохи?
Тесты выложены
Странно, на второй тест 10 2 2 2 2 2 2 2 2 2 2 я вывожу 4 2 4 7 10 у авторов 4 3 6 8 10 в чем подвох, ведь можно результаты то одинаковые?
Ну вроде одно и тоже, да. Попробуйте обратиться к авторам.
А не таки я идиот, просто из этой стены отправок не заметил что на последней уже на другом тесте.
p.s. Малоинформативная у них система, это мягко выражаясь.
у меня валилось вроде бы на тесте 4 1 2 3 4
пытаясь взять 1 + 3, вместо 2+2
Кстати, а там так и надо было прологарифмировать и сделать динамику или можно точно решать?
Можно поставить
dp[0] = 0;
dp[1] = -inf;
А дальше набирать двойки и тройки, причем как можно больше троек.
Ну у меня длинка зашла.
Ну ладно, я не имел в виду длинку :)
Можно каждый раз последние три числа в динамике делить на их НОД, тогда можно обойтись и без длинки. Правда не совсем очевидно, что числа останутся небольшими, но такое решение прошло.
Да, спасибо...
Блин. У меня была константа MAGIC в коде равно 200. Получал ТЛ. Надо было еще уменьшить)
Ну и естественно вопрос. Как мы это замечаем?) Печатаем и смотрим?
Была задача подобная на acmp, сейчас найду)
UPD хм, не нашел. Ну значит не на acmp, но где-то была задача "Дана сумма натуральных чисел, найти наибольшее возможное их произведение"
На acmp есть, http://acmp.ru/index.asp?main=task&id_task=42
И на Тимусе, если хотите, http://acm.timus.ru/problem.aspx?space=1&num=1222, тоже есть.
да, точно, значит память меня не подводит! :)
Поскольку там произведение, то интуитивно ясно что размер групп маленький. Теперь попробуем доказать верхнюю оценку. Ясно, что группы размера 2 и 3 точно могут быть в ответе. Также видно, что группу размера 4 уже можно разбить на 2 группы размера 2. Делаем предположение про группы размера >4 и доказываем по индукции.
Проще: при k>=2 2*k=k+k>=2+k, поэтому брать группу размера 2+k не выгоднее, чем разбить на двойку и остаток.
Некий факт, который ещё используется и в этой задаче 1222. Chernobyl’ Eagles Максимальное произведение получаем когда множители близки к e ~ 2.71. Т.е. 2 или 3.
The product of natural numbers with a given condition in this problem will be maximal if and only if the middle arithmetic of these numbers is the most closely to the number e=2.71828... It's a mathematical sentence which are proved! Форум
Пусть есть кусок хотя бы 4, делить его на части ясно хуже не станет 2*(n-2) >= 4.
Если есть и тройки и единицы, то можно обеъдинить 3 (2 2 2) 1 в 2(2 2 2) 2, ну дальше ясно, что у нас в итоге заменяются три двойки на две тройки, что выгодно.
Три двойки не всегда можно на 2 тройки заменить. Пример:
1 2 1 2 1 2.Ну да, я понимаю, я имел ввиду, так мы показываем, что нам надо набирать побольше троек.
Как все круты, такие факты сходу замечают... На самом деле всё интуитивнее — для непрерывного случая надо максимизировать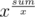 , дифференцируя, получаем, что надо разбивать на группы по e элементов. А дальше остальное заметить уже просто.
, дифференцируя, получаем, что надо разбивать на группы по e элементов. А дальше остальное заметить уже просто.
У меня другой вопрос — почему в double'ах с логарифмированием заходит? Есть какое-нибудь рациональное объяснение этому? Т.е. верно ли утверждение, что для любых разбиений на группы значения целевой функции сильно отличаются? Или это верно только в окрестности оптимума? Или вообще неверно, и тесты слабые?
Только что написал перебор всех значений (a, b), таких что 3a + 2b ≤ 50000. Если отсортировать все величины
ln(3) * a + ln(2) * b, то 2 самые близкие из них лежат на расстоянии 1.8 * 10 - 5.Ну ладно, значит с тестами всё ок :) Но вопрос остаётся — что можно доказать про то, насколько бывают близки разбиения, в общем случае? Кажется, если рассматривать произвольные 2a·3b, то они могут быть близкими. Или нет?
Из этой теоремы следует, что логарифмы могут быть сколь угодно близкими. Правда, это не говорит о самих значениях 2a·3b.
Ну тут можно просто при сравнении двух значений (2^a*3^b ? 2^c*3^d) сократить 2-ки и 3-ки и получить (2^n ? 3^m) или (3^n ? 2^m). А далее сравнить их как описал KADR
Произвольные-то могут, но те, кто писал с логарифмированием, при фиксированном 2a+3b их сравнивали, нет? В этом случае, например, замена трех двоек на две тройки понятно какое приращение дает.
У меня была константа 1000 и я получил ОК. Откуда там может быть ТЛ, всего 5*10^7 операций с даблами. У вас так вообще 10^7. Как так?
там все получающиеся куски длины либо 2, либо 3
Либо 1.
Говорят, таких тестов не было)
Динамикой, храним логарифм реального ответа для некоторого префикса + длину каждой группы я ограничил 20.
Можно просто хранить кол-во троек.
А как быть в случае [1 2 3 4] — когда нужно разбить на две группы по 2, а если будем максимизировать 3-йки, то получим группу из 1 и 3?
Ну нам разрешено использовать только 2 и 3. Набираем максимум троек. Если ВООБЩЕ ничего не набралось(dp[1] = -inf и тогда это равносильно dp[n] < 0), где dp — максимум троек, то тогда берем по 2 и по 1.
В данном случае вообще по 2 и по 1 не надо набирать — мы просто разобъём по 2 и по 3 маскимальным количеством троек — 0. Вообще можно пример, где надо брать 1?
UPD: 3 1 2 1, ок.
3121 => [31][21]
а вот 121 => [12][1]
3 — это кол-во ;)
Легко понять, что длину каждой группы можно ограничить тремя.
А можно решать жадно. Двойку возможно взять всегда, поэтому, если можем, берём тройку, иначе двойку. В конце, если осталась единица и мы брали тройку, сдвинем часть концов влево.
Как решать Е?
Выше написано.
Я, конечно, сам дол...., что правила не читаю, но ,....., объясните мне кто-нибудь, почему у них под гнусь размер стека выставлен, а под visual нет?
Мб потому что в вижаке можно свмому выставить,а в GNU — только из строки компиляции
Наверное, потому что под CNU C++ размер стека из программы поменять нельзя, а из Visual C++ можно.
а почему compilation error считается за попытку?
Уже убрали... Я поднялся на 2 места :)
UPD. А, ну вот, да: 15. Если не произошла ошибка компиляции, то решение проверяется на заранее подготовленном едином для всех участников наборе тестов.
В этом году на финале АСМ не давали минусов за Compilation Error. Как было в прошлые года, не знаю.
Хм, а на полуфинале в Питере дают сейчас вроде? Или уже нет?
На самом деле, всё больше убеждаюсь, что давать или нет минусы за CE, это по настроению организаторов. Ещё бывают случаи просто по отсутствию возможности не давать минусы за CE на сервере.
UPD: Про Питер не помню уже...
На ACM компилятор у участника и в системе одинаковые.
в Задаче C нам нужно брать куски длиной 1, 2 либо 3. у меня прошла динамика по логарифму реального ответа.
В задаче B я делал извратное рекурсивное решение на DSU с откатами, когда мы в самом низу рекурсии DSU содержит все рёбра, кроме одного, которое мы типа удалять собираемся. В этом случае возможно два варианта: либо это ребро — мост, тогда в DSU сейчас всего два множества, вершины данного ребра лежат в этих двух множествах, одна вершина в каждом множестве, прибавляем к ответу |A| * |B| — 1. в противном случае ребро не мост, и если в DSU сейчас два множества, перемножим их размеры и прибавим к ответу. Размеры этих двух множеств нужно посчитать один раз, т.е. если такая ситуация повторится, множества будут ровно те же самые. Как её решать по-русски? Я сдал её с 9-ой псылки из-за ТЛ и прочих ошибок.
C 11 попытки на Java из-за TLE :)
Надо посчитать 2 вещи:
1. Количество и размеры компонент связности.
2. Какие из ребер графа мосты.
Все это делается в одном dfs.
Ну а дальше если одна компонента, то если удаляем мост, надо добавить ребро, соединяющее то, что отрубил мост и все остальное, если не мост, то просто любое ребро, которое раньше не встречалось. Если компонент в исходном графе 2, то мосты удалять нельзя, а обычное ребро можно. Ну а добавить ребро нужно между двумя компонентами. Если компонент больше 2, то ответ 0.
К сожалению я не умею искать ни мосты ни точки сочленения :) Поэтому это был единственный вариант дотупный мне. Вообще-то решение довольно простое, там не так много мест где ошибиться, просто я че-то втупил жесточайше.
Какое самое эффективное решение у А?
сортируем. и смотрим, что первые 4 равны, вторые 4 равны и третьи 4 равны.
Достаточно посмотреть, что первый равен четвертому, пятый — восьмому и девятый — последнему.
Отсортировать каждый набор и проверить на равенство первые 4, вторые 4 и последние 4 числа.
Эх, как обидно. 234 человека с 2+ задачами и я 231-ый из-за того, что идиот.
Будут еще попытки, но пожалуй этот квал было проще всего пройти из-за пересечения по времени с опенкапом.
Пересечения нет. Opencup в 14:00 начинается.
Уважаемые красные, замутите пожалуйста тренировку на CF с задачам квалификации, так удобнее дорешивать.
Встречайте в тренировках 2012 Russian Code Cup, квалификация 1.
Блин я на капе стал 51м и меня нет в раклисте. Печально(((
Опубликован разбор задач: http://russiancodecup.ru/round/6/analysis.
Подробность разбора просто впечатляет. Например, по задачам C и E такое впечатление, будто бы авторы сами только глянули на них и, без написания кода, набросали самые общие идеи
PS. Уж тогда хотя бы дали источник с нормальным доказательством по Е
И в А разбор совсем никуда не годный :(
Хотя она, имхо, сложнее С или Е.
sort(ar,ar+12); if (ar[0]==ar[3]&&ar[4]==ar[7]&&ar[8]==ar[11])... else ...
В каком месте тут сложность зарыта?
То же самое и в С или Е.
Сопоставимая по сложности идея(к началу контеста можно вообще не знать, что есть параллелепипед или его какие-то свойства) + простая реализация.
Поверьте, доказательство не очень сложное.
Правка 4 это БОМБА!
Я рад за нынешних пятиклассников (к слову, из первой сотни участников задачу сдали далеко не все, а доказали корректность решения, видимо, еще меньше).
В разборе же как раз опущен единственный нетривиальный для меня момент — объяснение того, почему d1 = d2.
Не поленитесь уж, объясните нам, старым дегенератам =)
1 пост.
2 пост.
Ок. Я напишу разбор здесь, так как там в html достаточно сложно всё это написать.
Докажем, что какие-то 2 из них равны.
Пусть нет двух равных. Упорядочим по возрастанию — d1 < d2 < d3. Тогда посмотрим на (d1 + d2 - 1)(d1 + d2 + 1) — оно делится на d3. Несложно заметить, что d1 + d2 - 1 < d1 + d2 + 1 < 2 * d3. Из этого получаем, что d3 = d1 + d2 - 1 или d3 = d1 + d2 + 1.
Для примера возьмём d3 = d1 + d2 + 1, второй случай аналогичен.
Давайте подставим в другие условия d3 — например, (d2 + d3)2 - 1 ≡ d1(2d2 + 1)2 - 1 = 2d2(2d2 + 2). Случай с двойкой неинтересен. Значит, или d2, или d2 + 1 делится на d1. Аналогично, или d1, или d1 + 1 делится на d2. Из этого уже ясно, что d1 = d2.
Мы выбрали для разбора стиль "наброски решений". Аналогичный стиль используют, например, члены жюри финала, уже который год публикующие "неофициальный разбор финала".
Мы понимаем, что такой разбор не всегда позволяет понять детали реализации тех или иных идей, но вместе с тестами в этом году опубликованы также коды решений жюри.
Спасибо за понимание и конструктивную критику.
Наброски решений — это я понимаю, но, например, представленный разбор по задаче С — это даже не набросок. Из того, что написано, можно понять, что сложность авторского решения — это O(N^2), потому что нет ни слова о том, почему в задаче не нужно рассматривать подпоследовательности длин больше 3.
В задаче Е самая нетривиальная часть решения, которую, наверное, все хотели понять — а именно, почему d1 = d2 — описана как "ну, это даже пятиклассники решают, так что не поленитесь и вы". Зачем тогда вообще было писать разбор на эту задачу, если всю идею опустили, а то, что написали — и так тривиально?
Возможно вы правы. Хотя, откровенно говоря, часто техничные вещи "оставляют как упражнения" даже самые уважаемые авторы.
Что касается данного конкретного разбора, сожалею, что ваши ожидания не совпали с реальностью, мы учтем всю поступающую критику при подготовке следующих раундов.
Просьба тоже не воспринимать написанное мной как какую-то жесткую критику. Объективно — сам раунд был хороший и (кажется, не только мне) понравился. Но разбор задач C и E подкачал (причем для остальных задач разбор достаточно подробный), о чем я не преминул написать. Ну и удивился, получив в ответ не слишком, имхо, адекватную (не говоря уж про банальную вежливость) реакцию.
Как бороться со stack overflow в B? Сдавать под MS? GNU — WA4.
Решения, сданные под g++ компилируются командой g++ -x c++ -O2 -Wl, --stack=67108864 <файл> (пункт 13 правил). ML 256 Mb, но 64 на стек в такой задаче вполне должно хватать.
А можно на странице результатов добавить функционал, который бы выводил вверху (где пишутся твои результаты) результаты "друзей", как в GCJ или на Codeforces?
только хардкор — только поиск постранично вручную!
или нулевая задача контеста — напишите плагин, который делает это
Спасибо за предложение. Более эффективно отправлять предложения через форму обратной связи на сайте Russian Code Cup.
Мы постараемся реализовать подобную функциональность, но пока не могу точно сказать, когда...
Предложение уже и было отправлено, когда пост получил over +30. Ждём с нетерпением.
Проснулся в 15:00. Пропустил, как обычно.
Как обычно — это по сто грамм?
Сто грамм — это сюда
Присоединяюсь к озвученному выше негодованию. Разбор не выдерживает никакой критики.
"Можно доказать, что существует ответ, в котором отрезки имеют длину не более трёх". Клмн, это и есть единственная сложность в задаче (ну и логарифмы конечно, но о них вообще ни слова).
"Первым делом следовало заметить, что два наименьших простых числа обязаны быть равными — иначе, условия выполняться не будут." Иначе условия выполняться не будут — обоснование просто обезоруживает.
Кому-то лень писать разбор — тогда его лучше вообще не писать.
Здравствуйте, steiner.
К сожалению уже ничем не могу помочь. Если хотите почитать про доказательство равенства чисел, то на него есть ссылка в посте. Извините, за столь непонятный разбор.
Аксёнов В.
Здравствуйте, Aksenov239.
Извиняю. И всё же я думал, что разбор можно переписать. Никакие доказательства я читать не хочу, но замечу, что на контесте именно они заняли у меня больше всего времени. Вероятно, не только у меня.
Здравствуйте.
Меня поражает реакция публики, собравшейся здесь — то им не так, то им не этак. Но Вы сами пробовали хоть что-нибудь подобное сделать? Вместо того, чтобы критиковать, поправили бы.
С уважением, Аксёнов В.
А где же ссылка?! За всех не скажу, но мне раунд показался весьма удачным. Довольно интересные задачи, короткие и понятные условия (привет GCJ!), никаких реджаджей. Единственная претензия — к качеству разбора — вряд ли была бы озвучена, если бы не хамство одного из авторов (не будем показывать пальцем) в треде выше.
Хамства не было. Всё вполне обосновано. Вам прислать выдержку — "Как не быть мудаком"? Ведите, пожалуйста, себя адекватно.
"Такую задачу пятиклассники решают — неужели Вы не можете справиться?"
Да. Это не хамство. Это чистой воды правда. Меня поразило, что люди старше пятиклассников на очень много лет не в состоянии это доказать. Именно, по этим причинам я оставил эту часть без доказательства.
мне кажется, или разбор должен быть исчерпывающим несмотря на то, читают его пятиклассники или любой другой контингент
Я рад за пятиклассников, но доказательство выше страдает, минимум, двумя неточностями:
1) Доказано, что какие-то два числа равны. Не рассмотрен случай d2 = d3.
2) Cлучаи d2 = 2 и d3 = 2, конечно, не интересны. Пропущен, возможно, важный случай d1 = 2.
Я могу показать этот случай. Если d1 = 2 и d2 != 2, то (d1 + d2 — 1) — четное, (d1 + d2 + 1) — четное. Значит, так как ни первое, ни второе не равно 2(иначе нарушается условие о неубывании), то оба они не являются простыми.
Это и называется хамством. Все мы очень впечатлительны. Меня, например, поражает, что люди, которые старше пятиклассников на очень много лет, не в состоянии нормально расставить запятые ни в одном предложении. Но если бы я был представителем жюри такого крупного соревнования, то поостерёгся бы говорить такие вещи о задаче, которую не решила и десятая часть участников.
Добавлю: соблюдать традицию не писать пробел перед двоеточием и грамотно написать слово "кодокубок" (перевод названия соревнования и использование слова "русский" в переводе оставим на совести автора).
Когда участники просят что-то объяснить (а среди участников RCC могут быть люди, которые вообще не имеют профильного образования), указывать им на то, что они тупее каких-то гипотетических пятиклассников — последнее дело.
В некоторых соревнованиях прямо в условии рассказывают, что такое логарифм, и что такое XOR. И не видят в этом ничего поражающего воображние. Проще надо быть, а не строить из себя высокомерного засранца.
Виталик, ты меня извини, но нужно быть проще.
Мы рады, что ты принял участие в подготовке задач к столь хорошему турниру, однако, это не делает тебя автоматически лучше других.
Здесь много людей, которые лучше тебя решают задачи, непонятно откуда столько пафоса.
Я не участвовал в холиваре который происходит чуть выше. Но могу сказать, что меня удивляет наглость ОДНОГО ИЗ АВТОРОВ задач который прямым текстом называет почти всех участников большого соревнования тупыми идиотами и при этом еще и отстаивает свою точку зрения. С другой стороны мне кажется если автор считает что он настолько крут что такие задачи решал в "пятом классе", почему он не подготовит какой-нибудь крутой набор задач на олимпиаду по математике на уровне Всероса или Межнара и не будет мешать развиваться кодерам?
Здравствуйте, сообщество.
Во-первых, да, я могу написать фразу с двойным контекстом, даже неподозревая, что её поймут в плохом смысле. Прошу прощения за то, что себя так поступил.
Во-вторых, я не строю из себя "высокомерного засранца", по понятным причинам, я — тупой, и не представляю из себя никого, этого не было в моих планах, и "сраться" здесь я тоже не собирался.
В-третьих, я имел в виду нынешних пятиклассников. :-)!
В-четвёртых, всё это происходит ещё после моего последнего раунда на "Codeforces". Я просто ошалел от того, что делают люди — им подготовили контест, в котором была ошибка в 1 задаче, которую я признал, но меня поразило то, что до раунда было около "+110", а после его проведения стало "+25". (Между прочим, после этого я до сих пор на нервах, а им очень плохо. И я под присмотром врача. Спасибо, ребята!) Здесь же ровно такая же ситуация. Я просто выхожу из себя и не могу себя нормально контролировать, потому что я всё принимаю близко к сердцу.
Извините за такой просчёт, я постараюсь больше не причинять Вам никаких хлопот.
P.S.: Ваше отношение ко мне я тоже принял близко к сердцу между прочим. :-)! (А с моей неустойчивой психикой я могу и суицид совершить...)
P.S.2: Можно, пожалуйста, не писать критику сразу по поводу того, что разбор задачи — "говно" (_"Разбор не выдерживает никакой критики."_), напишите чего Вам не хватает, и я с радостью сделаю то, что надо. Но надо нормально сообщать, а не таким образом. Извините ещё раз.
До свидания.
суИцид.
Здравствуйте! Спасибо, что заметили ошибку. До свидания!
Не знаю как остальным, но для меня мелкие фейлы — это не причина выносить критического суждения о человеке. Я — из тех, кто ставит плюсы еще до начала раунда, потому что считаю что даже если автор задач невнимательно оценил сложность задач или даже набажил в решении одной или нескольких задач — все равно он большой молодец, он проделал гигантский труд.
Поэтому призываю вас — не обижайтесь на сообщество, оно не всегда ведет себя адекватно, а иногда мы сами себя ведем неадекватно и не замечаем этого. Даже если сообщество не право, не воспринимайте все очень близко к сердцу, продолжайте писать контесты, составлять задачи и не обращайте внимания на отдельных придурков.
В Ваших рассуждениях мысль, по-моему, иногда теряется. Задачи и разбор не читал, но по прочтению обсуждения оных напрашивается мысль о том, что Вам просто необходимо отдохнуть. О Вашей неустойчивой психике известно немногим, и Вы должны быть готовым к тому, что жалеть Вас и заботиться о Вашем состоянии никому не придет в голову. Берегите себя!
Возможно, чтобы избегать ошибок в задачах, нужно написать полный разбор ДО раунда, с полным доказательством всех фактов? И ошибок станет меньше после того, как тщательно все будет изложено на бумаге. И не будет необходимости жаловаться потом на непонимание тех, кому очень не нравится участвовать в раундах, в которых были ошибки. Может быть, стоит с уважением относиться к УЧАСТНИКАМ раунда при подготовке, и тогда с уважением будут относиться к вам?
Если принимать любую критику так близко к сердцу, то жить будет ну оочень тяжело. С критикой всем приходится сталкиваться, а большинство людей не умеют смягчать формулировки, поэтому полезно установить "смягчающий фильтр" на своей стороне, если резкие формулировки так огорчают.
(Алсо, никогда не понимал, почему некоторые волнуются из-за плюсов/минусов: большая часть голосующих — совершенно незнакомые вам люди, какое вам дело до их мнения (вы же не политик какой)? Да может это и не люди вовсе, а чья-то очередная армия ботов.)
А в чем сыр-бор по E. Пусть для определенности d1<=d2<=d3. (d1+d2)^2-1 делится на d3 Следовательно, из простоты d3, получаем k3*d3=d1+d2+{1,-1} Следовательно, либо d3=d2=d1+1, что приводит нас к невозможному варианту (2 3 3), либо d3=d2+d1+{1,-1}. Тогда аналогично k2*d2=d1+d3+{1,-1}=d1+d1+d2+{2,0-2} Тогда (k2-1)/2*d2=d1+{1,0,-1}, что опять таки нас приводит либо к невозможножному варианту d1=2,d2=3, либо d1=d2, ч.т.д. И это на самом деле просто. Но, функция разбора не только в том чтобы объяснить решение, но и в том чтобы продемонстрировать участникам, что организаторы на самом деле тщательно готовились. А все здесь присутсвующие легко это смогли бы доказать тем или другим способом. Организаторам надо понять, что возмутило всех внешне небрежное отношение к работе. И еще, импульсивность и интеллект часто очень перемешаны. Так что не будем никого судить особенно строго, а уж тем более минусовать ;). Я от задач получил удовольствие. И это главное.
Да ну достали уже комментарии в эту ветку. Ну поругались, не допоняли, не так себя повели, какая разница? Бывает, рабочий момент. Уже все версии и взгляды на произошедшее высказаны, все слова сказаны. Хватит переливать из пустого в порожнее.
Thank you, captain ;)