


Hi there,
Soon, Google Code Jam online round 2 will kick off.
You can advance to Code Jam round 3, if you are one of the top-scoring 500 contestants from round 2.
Also, the top 1000 contestants will receive Google Code Jam t-shirt.
Let's discuss the problems here after the contest.
Good luck all!
P.S. Distributed Code Jam round 1 will take place one day after this round (exact time).
UPD: contest starts in less than an hour, you can load the dashboard now.






is it rated ?
Yes.
LOL
Will top 1000 or top 500 contestants receive t-shirts ? Where did they write about it in the official site?
"Also, the top 1000 contestants will receive Google Code Jam t-shirt."
I was asking "Where did they write about it in the official site ?". I was not asking about this post on Codeforces. Someone told me that top 500 will get the tshirts. That's why I was asking this question. Don't know why you have to down vote the comment.
Look for Prizes from T&C. I'm pretty sure if it was top 500 then people would have already pointed it out.
Good luck to everyone joining the contest!
You know a round is too difficult when even the first subtask is challenge to get AC.
How to solve B large?
You need to select X smallest and K - X largest members for some X.
How to prove it in a way different from "I'm a cool guy with a naive solution, I can run a stress-test"?
If you fix all members but one, the probability of a tie is a linear function of that member's probability, so we should pick either the maximum or the minimum.
Wow, that's tricky! I thought about that problem for long time and even thought about algorithm, but couldn't find argument why it has any chance of being correct ._. Fact that 822 people solved that amazes me :P
In case you don't know how to solve, you can always do:
That's what I did. I experimented with different inputs and noticed that if I change only one number then it's best to put it at 1.00 or 0.00. So I came up with the real solution. I suppose that's what most of the competitors did.
That's really cool. Do you know of any problems of a similar kind, where considering the price function allows you to greatly limit the subsets considered?
In a narrow sense, nothing comes to mind. In a broad sense, lots of algorithms are like this — for example the minimum spanning tree ones :)
http://codeforces.me/contest/442/problem/B
Probability of a tie is linear in terms of each member's probability, so, if it is possible to change probability of one member, it is profitable to either maximize or minimize it. Btw, this is the first solution I coded, I didn't have a naive solution.
There's also, "I'll try some trash on easy and if it works I'll submit on large"
Wow, I did think of that as an intuitive principle but didn't think it'd really work. Damn it...
Wow, I submitted 10 seconds before the end of the contest. And still didn't get within top 500, but that soclose moment was worth it.
But did you get AC?
Yes. It was such a stupid bug, too... the bruteforce for C was way too annoying to write considering the points assigned (compare the ACs on C and D small).
I made quite possibly one of most annoying mistake I have ever made when writing the solution for C-small.
I was using bitmasking to generate all possible board states. As a note for myself that when a bit is 0 that means set the value of the corresponding cell to \ I had written the comment:
// \And then continued writing code in the next line.
However, what this does is also treat the next line as part of the same line, therefore commenting out a line of my code, whereas my editor was showing it with normal highlighting etc. making me think that the line was being executed.
It was only after putting print statements everywhere that I managed to find this.
I wasted 20 minutes checking all the graph stuffs before I looked at this line and sighed:
Because of things like this, I have become extremely paranoid in regards to operator priority, so I just put brackets everywhere. They might be nested 5 layers deep, but hey, it works!
Hah, my template is
#define REP(i, n) for(int i = 0; i < (n); i++)and in code I anyway writeREP(mask, (1 << n)). So many brackets.Nope, the problem is not the operator priority. + and — are executed before << and >>. It should be R * C actually.
I have a weird interest in using at least brackets at possible so that I can force myself to understand the operator priority and the scope clearly to not mess things up.
I forget to recursive to make A-large's answer alphabetical order smallest. And when contest ended, directly fall from top 500 to 800. Deeply frustrated, just opposite ot you. That's another type of experience.
For 1.5 hours I failed to submit first two tasks. Then I solved D, and in last minutes found a bug in my B. That was epic. I still dont know how to solve A-large, and i didnt even submit A-small :)
For A you can generate three sequences, starting from P, R, S then 0+1, 0+2, 1+2 = PR, PS, RS and so on N times.
It will give you three lexicographically minimal valid sequences. Count P, R, S in each of them and match to input.
Unfortunately, it is the only task I solved for both small and large tests :)
I used the fact that if you know P, R, S before a round, you can easily compute P, R, S after it. But it's funny that for each N, there are just 3 valid (P, R, S) triples.
Even funnier ... I accidentally got the formulas wrong in my code (R -> PS, P -> SR, S -> RP). I didn't notice until after the contest, because it doesn't affect the final answer at all!
For A, you only need to simulate the process backwards. For example, let's suppose that Rock wins; then, the last match was Rock vs Scissors, the two lasts but one matches were Rock vs Scissors and Scissors vs Paper and so on...
Did you actually submit that for A-large?
Yes. The only thing that I forgot to mention is that I sort the string after the process is done.
Solution for 4-th problem:
Its obvious that after we teach all the workers, the result graph must consists of multiple connected components which are full bipartite graphs between same number of workers and machines. Lets calculate all current connected components and fill them with edges so they will be full bipartite. The only problem with that is that our components can have different number of workers and machines, lets fix that by joining several components into one. Complexity is something like 3^50, because there can be 25 components with 1 worker and 25 components with 1 machine, and its not good.
We must separate all components on 4 types: "free workers", "free machines", "free pair machine<->worker" and "complex shit". Use counts for first three and masks for shit.
Since number of complex components cannot be more than 50/3, we'll have something like 3^16 which is good enough for us.
I used counts for all identical components. Also, I didn't consider free machines at all, instead I used condition machines ≤ workers for a component to be "good".
"Its obvious" — for me it was like 80% of difficulty ._. I think that this fact is neither intuitive nor straightforward to prove and I was pretty proud when I have observed this. Creating an algorithm from that seems much easier to me (I got identical as you).
Indeed, I didn't manage to figure this "obvious" thing out during the contest. :) I should have spent more time experimenting with small cases and less time looking for some complex flow-based solution.
Glad you liked the problem ;)
This one of the rare problems built entirely "from the statement" — i.e., I was curious which graphs have this property, and after some thinking found that they're actually described quite nicely. It was in no way obvious to me, but it seems that some people have the right kind of intuition here.
For A you may notice that the solution exists if and only if min(r,p,s) differs from max(r,p,s) by at most one, let's call such tuples valid. Then you find such (r',p',s') that they form a valid tuple and (r-r',p-p',s-s') is also valid and among these we maximize p', then r'. Then we recursively call
solve(r',p',s'); solve(r-r',p-p',s-s')until there is just one element left, which we simply print.What is the approximate time of waiting for GCJ T-Shirt?
If you qualify for onsite, you can get it there. If not, you might get it even earlier :-)
Can someone explain the solution of B?
The O(2n·k2) subset DP for small is trivial, but how to solve large?
It seems somehow sorting the range and then trying all contigious sub arrays in the DP works. Can someone prove it's correctness?
Why don't you ask on AoPS? (It's mathy) >_<
For everyone who doesn't get this, it is regarding this.
Anyway, the contest analysis is up. You can find the proof there.
Firstly, sort all the probabilities.
Then you have to select some prefix and suffix.
After that calculate f[taken][lies] — is the probability that you have gone through taken persons and lies of them have lied.
The answer is f[k][k / 2].
Try all prefixed and suffixed and choose maximum.
"Then you have to select some prefix and suffix." How did you prove that?
I solved small group with bruteforce.
When I guessed that this idea is true I coded it. Checked with brute. And realized that the idea is cool and submitted the solution :)
Me too. It can prove actually.
Great contest (D was beautiful). However, I think the rank depends too much on C small + D small.
Hmm, Problem C is identical to an existing contest problem from several months ago: https://jollybeeoj.com/contest/24/problem/126
Bad luck. I think it's fine that organizers assumed that this is an original problem. It isn't straightforward (I'm talking about problem/statement, not about solution).
Oops, this is an unfortunate coincidence indeed :(
EDIT: I guess it just happens that the same idea comes to the mind of different people at the same time. We had this problem written since September of last year, and also asked quite a lot of internal testers but nobody seen it before. I hope there were not too many people already familiar with it.
Yeah, I'm sure it didn't matter. There were no submissions to that problem in its original contest, and it was also added to SPOJ but received no submissions there either. The contest had an editorial, but the explanation of this problem was so brief that it would be completely useless to anyone.
Anyway, interesting coincidence that multiple people independently came up with such a specific problem around the same time :P
It's a well-known type of logic puzzle (without the "every square gets a mirror" constraint, though, which is what makes the greedy work). So it's not actually THAT surprising two people would independently convert it into a contest problem.
Nowadays there are so many problems being written for so many contests, it feels like it'd be a full-time job just scanning them all to avoid duplicates! I was pretty embarrassed when one of my ICPC Finals problems (Maze Reduction) turned out to be a copy of a Topcoder problem. It happens.
Regarding to Maze Reduction. Recently we were virtually solving WF14. First solution on contest was at about 1h 40 min (coming from University of Warsaw!). However Marcin_smu managed to solve that problem in 38 minutes. That was because it was on his list of problems he has came up with and is going to propose somewhere in future :). Needlessly to say, it was erased from that list the same day :P.
By the way, how do you solve version without "every square gets a mirror" constraint (I assume, routes are determined as if those were lasers and mirrors)? It is among problems on Cracow's online judge and I struggled a lot with that problem (just YES/NO version) and came up with some stupid necessary solution which happens to pass, but I don't have any idea why.
Hmm. Not sure. My intuition is that it's NP-complete, like most generalizations of logic puzzles are. But on the other hand, there are only 2*(R+C) constraints on an R*C grid, so as R and C grow large maybe it just becomes easy for any somewhat-reasonable heuristic to work. (Logic puzzles of this form tend to also tell you how many times each laser reflects, which constrains the answer more.)
Ah, I thought you already knew how to solve it :). To be precise, exact formulation I am talking about is what was posed on a contest but without that "every square gets a mirror" and question is whether there exists such placement of mirrors. It turns out to be polynomial, but I have no idea why that condition I am gonna talk about is sufficient. What we need to check is whether there exists a horizontal/vertical line dividing whole grid in two parts so that there are more pairs whose elements were separated by that line than the length of that line itself.
For example, for a case
if we consider a vertical line passing through the middle all three pairs are separated, but only one beam can cross that line, so solution doesn't exist.
Interesting. I guess you can prove that your (obviously necessary) conditions are sufficient using induction. Slice off one row, and try to assign constraints to the dividing line to make two smaller puzzles that work. The worst case is when there's only one X-X match on the small piece. It might look like this:
Between the Xs the permutation can't change, but you're also removing one cut constraint (the Xs) from the large piece's vertical lines, so the large piece's conditions are still satisfied. And on either side of the Xs you can move a single constraint anywhere you like, which should be enough to reduce the rest of the larger piece's vertical line cuts by 1.
There are a lot of technical details to fill out, but that seems like it might work.
However, the conditions definitely aren't sufficient when not all the outside constraints are given. This has no solution but doesn't fail the conditions:
I wonder if you can still solve these in polynomial time by finding an assignment of constraints to the outside that satisfy the cut conditions...?
I wonder what is the expected solution for C. I know a solution that works in O(RC), but limits for C-large are too small for this complexity.
But do you know any slower solution? Since we didn't really have any other solution to separate, we opted for lower limits to allow languages like Python to pass easily.
Yay! So there are more people following golden rule "Limits should be as low as possible in order not to let any slower solution pass" ^_^
But it's still nice to give correct info about the required complexity, in my opinion. It isn't nice to get O(n2) for n ≤ 50 and think why this approach is wrong (Topcoder, I'm talking to you). But whatever, it's something fine and acceptable.
From my point of view — contestants should solve a problem instead of guessing a solution by looking at constraints section.
This tweet comes to my mind (for those who don't speak Russian, it is about one of the problems from NEERC 2014, and it says something like "In problem I original constraints were n<=1000, but later it was simplified by rising it to n<=200000").
P.S. Also this coment describes my point of view well.
Interesting. So I guess I will start applying it to my problems.
But they also let some slower solutions pass, e.g O(K^3) for B. I guess that's the alternate golden rule of "as long as you have the main idea, you can pass"
K^3 was intended, no? And K^4 was what also passed.
I wasn't involved in preparing B, but my guess is that the thinking was to reward solving the mathematical part of the problem, not the relatively standard following DP, so there was nothing bad about letting O(K^3) or O(K^4) pass.
I tried to code this O(n^3 log n) (assume R = C = n) solution:
Sort the matches by their distance (min(abs(a-b), 2*n+2*m-abs(a-b)), process them one by one. For each match, we want to use a path that it is as close to the edges as possible. That can be done by finding a shortest path between 2 nodes — and if 2 paths have the same length, we need take the one passed more cells that passed by previous paths before.
I was thinking that is not too complicated to code, but...
This is really tricky to implement indeed, and correctness will depend on very small details.
We had a similar solution implemented, and quite surprisingly we could break it even within the small's constraints with 2x8 grids — I guess you ran into those tests.
I'm sorry you missed the top 500 :(
If someone already received a T-Shirt before, I ask you: How much time takes to I receive it in my home address?
Several months I think.
I think that should depends on where you live.
BTW, I receive the T-shirt at about the end of July last year.
Got my T-shirt yesterday (Aug 2). It was delivered by DHL.
EDIT: Thanks to ffao for pointing the flaw in my proof. Seems it was even less "obvious" :P. Hope this one works.
Let me describe here my proof why only possible graphs in D are sums of Ka, a.
Consider one connected component and vertex with smallest degree within it. Let that vertex be v, its degree be d and set of its neighbours be N. Throw away v from that graph. Note that there can't exist a matching containing N (because otherwise v can be not assigned to anyone). However all guys from N have degrees ≥ d - 1 (since v has smallest degree), so every proper subset of N fulfills Hall's condition. Since there is no matching containing N then subset of N that doesn't fulfill Hall's condition needs to be N itself. So N knows less than |N| = d guys, so N knows d - 1 guys since all guys from N have degree d - 1. Moreover every guy from N has exactly the same set of d - 1 neighbours. It is easy to see that those d - 1 guys can't have other neighbours than N (because otherwise it may be the case that N will not be fully matched), so if we restore v to graph then what we have just obtained is fully connected bipartite component Kd, d that concludes the proof.
This sounds off to me. Consider the following case:
P knows 4 > |P| machines different than m, still m will always be assigned.
Here's another proof. I don't know which is easier but I think it's worth sharing because my idea is completely different and it doesn't even use Hall's lemma.
Assume that graph is connected and has a perfect matching (v1, u1), ..., (vn, un).
1) If there is an edge (vi, uj) then there is an edge (vj, ui). Indeed, we can construct this matching: (vk, uk) for k ≠ i, j and (vi, uj). Then the only unmatched vertices are ui and vj. So there should be an edge between them.
2) Actually we can make previous statement stronger: if there is an alternating path from vi to uj then there should be an edge (vj, ui). The proof is almost the same.
3)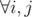 there is an alternating path from vi to uj. The graph is connected, so there is a path from vi to uj. Using statement 1) we can make this path alternating.
there is an alternating path from vi to uj. The graph is connected, so there is a path from vi to uj. Using statement 1) we can make this path alternating.
4) Combining 2) and 3) we get that the graph is indeed complete.
As usual I headed to office to write Codejam — I don't do it at home, because it is impossible to isolate two kids for 2.5 hours :) I arrived at work — nice and quiet. We have a cleaning lady who comes to do cleaning in our office once during weekend for just half an hour. I don't know how she chooses the time, but when Facebook hacker cup round was starting at 14:00, she came at 13:55. Today, GCJ was starting for me at 9:00 and she came in at 8:40. Maybe she follows competitions schedules. I asked her not to vacuum clean this time and sat down waiting for the round. I don't like people doing cleaning around when I try to concentrate, but it's not the first time and still better then kids.
At 9:00 working day started for some guys doing repair in our building. Together with opening first problem I heard drilling noise coming right from lower floor. It felt like they are drilling my feet. After trying to figure out what problem A was about with that drilling happening, I understood that I can't even think, so I went downstairs. Talked to those guys and they agreed to delay drilling for 2:30 hours. Then I found out that I locked myself out of the office, so called security to get me in.
Around 9:30 I finally sat down to write the round. By that time I was not in a good shape anymore. Solved A small by naive implementation. It was extremely buggy implementation, especially the half of it written while those guys were still drilling. Thought long time about A large, implemented heuristic approach which in my opinon should have found solution if there is one — and it did on A small, I submitted (and it was correct in the end). Good example of approach — write some sh.., check on small and submit :)
Then I solved B small, which took me a lot of time — I couldn't figure out how to calculate probability even if I know which members I want to take. Now I know — just simple DP, ok. then I went for D small but couldn't fix all bugs until time ended.
I don't blame myself much because of first stressful 30 minutes — I couldn't code properly after all that time running around. Last year I had a bit of luck, so finished within 500, this year I had bad luck and finished outside 1,000. I think that without that stressful 30 minutes I would get somewhere between 501 and 1000.
Still hope to win T-shirt this year — my chances are definitely higher tomorrow, then they were today. Also cleaning lady did her visit for this weekend and usually nobody work on Sunday here, so hopefully no more drilling.
Unless they also did Codejam.
They will — but now they are just 5yo and 2yo :) Older one just started doing Lightbot for iPad :)
And you were at #11, congrats :)
CHEATER FOUND
Look at the code of rank 758: anubhav11 and rank 837: rajat1603 for B large.
Only variable names are changed, they're basically same. And they're from the same school.. Co-incidence?? I doubt that..
pussy is NibNalin who has a past record of cheating (: