


И снова здравствуйте!
Уже сегодня 5-го мая в 19:05 начнется очередной раунд Codeforces. Да-да, обратите внимание на нестандартное время старта.
Я воспользовался своим служебным положением и теперь вас ждет чуток экспериментальный раунд с расширенным набором задач. Возможно, опытным участникам (извините, Div 1) он покажется простым. В данном случае был сделан упор на основную целевую аудиторию раунда — в раунде будет много совсем несложных задач, но и даже топ второго дивизиона найдет кое-что интересное. Кроме того, одна из задач будет предложена в двух вариантах — в упрощенном варианте с маленькими ограничениями и в усложненном с ограничениями побольше. Таким образом, если вы сразу сообразите решение для больших ограничений, то можете написать один код на оба варианта.
Авторы задач — это я и fcspartakm. Надеемся, что вам понравятся задачи и будет весело и полезно!
Запланированная разбалловка такова:
- A: 500
- B: 750
- C: 1000
- D1: 1000
- D2: 500 (то есть полное решение задачи D оценивается в 1500 баллов)
- E: 2000
- F: 2500
Удачи!
UPD: Как указали в комментариях с парой смежных задач D1/D2 есть тонкость со взломами.
Для того, чтобы избежать ситуации, что участник заблокировал задачу D1 и подглядел в своей комнате решение к D2, вы сможете блокировать задачи D1/D2 только парно одновременно и только в том случае, если сдали как D1 так и D2. Иными словами, возможность блокировки D1/D2 появляется после сдачи обеих подзадач, блокировка осуществляется одновременно по обеим подзадачам.
Для того, чтобы избежать двойного вознаграждения за взлом как D1, так и D2 у одного и того же участника, участник A в случае успешного взлома участника B по задаче D1 теряет возможность взламывать B по D2. Аналогично, если участник A успешно взломал участника B по задаче D2, то A теряет возможность взламывать B по D1.
UPD 2: Раунд завершен. Поздравляем победителей. Вот герои сегодняшнего дня.
топ-5 официальных участников:
топ-5 внеконкурсных участников:
UPD 3: Опубликован разбор задач.







So is CodeForces trying to move towards larger problem sets for a contest? Cause I think it'd be a lot more fun if there were more problems to try and solve per round.
Мда... всему вас, начинающих проблемсеттеров, учить надо... Забыли поблагодарить Михаила Мирзаянова за Codeforces и Poligon.
Я думаю, что Михаил Мирзаянов в своём посте может и не благодарить Михаила Мирзаянова и созданные им системы Codeforces и Polygon.
Will it be rated?
Sure.
Классно придумали с задачей D!
О, реально. Почаще бы так :)
А мне вот не очень. Очередь была длинная, и нужно было принимать неприятное решение — отсылать сразу обе, и получить за возможный баг -50x2, или отослать одно, и ждать несколько минут ответ теряя очки?
Мне кажется, стоит сделать, что если человек сдаёт D2 (большой тест), и D1 у него не сдано ещё, то он автоматически получает и по D1 галочку
Можно сделать как на Всероссийских олимпиадах: у каждой задачи есть несколько подгрупп.
Will contest duration remain the same?
/contests page shows it is 2 hours and 30 minutes.
If D2 score decrease 8 per minute (as a usual round) . then what will remain after 30 min?! only 250 points?!
I thought that the decrease was dependent on the problems score? If a problem is worth 500, at the very end of the contest it will decrease to be 250 points. In a regular 2-hour contest, it decreases at 2 per minute, but in a 2.5-hour contest it will decrease at 1.67?
А правда, что можно сдать d1, заблокировать ее и перебить код нутеллы из твоей комнаты в d2?
А еще можно получить +200, взломав решение, отосланное и на D1, и на D2.
Also notice that problems are becoming harder and harder as the scoring distribution has also changed.
Having a problem with two subproblems in a regular Codeforces round with hacks may be exploited in a following way: suppose there are two coders in the room. One of then solves only D1 and successfully submits it, while second solves both D1 and D2 with the same source code. Then, if first coder locks his code, he is able to read a solution for larger constraints if he opens a solution of D1 by the second guy.
Something has to be tuned here. How about leaving a possibility to hack only for D2?
Locking D as a whole should work too
But if the first coder solved only D2, there may be people who submitted same solutions for D1 and D2 so if the first coder locks his D2 solution, he can find out the solution for D1 without being able to hack D1 solutions.
UPD: vice versa for D2 and D1
All correct D2 solutions will probably be correct D1 solutions
Not necessarily. I have a correct D2 and an incorrect D1. When submitting D2 there was an overflow error which I forgot to fix in my D1 submission :(. Maybe D2 should have been worth at least as much as D1.
There is also a possibility that D1 is "solve it" and D2 is "now write a checker".
I don't think so, I think it will be like write quadratic solution for D1 and quasi-linear for D2.
What if a rule can be made like this "To hack any of the sub part of D you need to solve both of them first." ?
this gonna be Enjoyable , I'm in !
this gonna be Enjoyable , I'm in !
I have my Exam tomorrow.But this round looks interesting. I'm in!
That's the spirit !
Who cares about exams?
After a backlog, I started caring!
I think this new form---one of the problems will be offered in two versions is very great!The equivalent of i could not finish big data algorithm can also get scores,right?For the beginners like us is really nice!I hope this form will be keep in the next rounds.I will support codeforces forever and i am expect codeforces can launch more good forms like this!Come on,codeforces!!!
Partial Marking. This is going to be pretty interesting. :)
I wonder why if you hack D1, you can't hack D2. They can be completely different solutions.
Rule number 2 is not good ! In case someone submitted same code twice and I hacked one code in 90% of cases it means the second code is also not good. So some other will see it and receive points for second subtask despite he didn't find bug after first chacking.
Also there can be 2 completely different solutions, why hacking one of them prevents from hacking another?
I think that better option is receiving 200 points for hacking both solutions, or not allow hacks for D task.
Suppose you hack ones D1 and then they resubmits correct D1 and bad solution for D2.
You should be able to hack him.
You may consider disallowing to hack solutions which were submitted before hack.
But may be it's a good idea to just let people get their 200 points
You forgot to thank yourself.
В задаче B почему-то отклоняется генератор: Validator 'val.exe' returns exit code 3 [FAIL Expected EOLN (stdin)] вроде проверил всё.
Как использовать тип
__int128? gnu g++ 11 ругается. А еще научите сравнивать произведение чисел с другим числом, если произведение может выйти за long longЕсли хочется сделать сравнение вида
a * b >= c,то можно вместо этого сравнить
a >= c / b,где переполнения не возникнет. (работает для натуральных чисел, понятно, что нужно менять в случае отрицательных)
(a >= c / b)^(b<0)должно сработать.bool f(long long a, long long b, long long c) { if(c == 0 && (a == 0 || b == 0)) return true; return (c % a == 0 && c / a == b); }
Объясните пожалуйста первый пример последней задачи, а именно: где там число k, которое равно количеству цифр в числе n?
n=00312 k=5
но ведь Единственное, что помнит Вася, это некоторая непустая подстрока числа n (под подстрокой числа n следует понимать последовательность подряд идущих цифр из числа n). и там 021, следовательно в n должна быть подстрока 021
Тоесть n до перемешивания могло быть 30210 или 30021.
Test #11 is Evil
well, look at this
Desperation on a whole new level :v
This guy was trying so hard...
I think Hedgehogy gave up at the end. x)
Nope, unfortunately, he did not.
What a Binary Search Round! Enjoyed it to the core...
Too easy IMO.
How to pass test 4 in problem F? Easy problem, but I can't find bug in my code :(
Same. test 4 for F killed me.
Maybe this test can help you: 330055 33,the answer is 33005
Weak tests at F,my solution doesn't work for 323445 32,didn't have time to fix that,feel so bad...
My solution works for both but failed Pretest 4. T_T
in pretest 4,you put the second string first,and after that the rest of digits,i know that for sure
What is the substring?
fixed
I pass both "330055 33" and "323445 32", but still fail on pretest 4.
Same. LOL. Magic test 4
don't know what is your mistake,i checked these tests and after fixing my bug i got pretests passed
I suppose pretest 4 is huge. I've tested my solution with test generator, still no idea what fails.
how to solve Div2 A?
First of all we are bound to have 2 off days in each week , so first find the number of weeks and multiply it by 2. Next in case total days are not divisible by 7 we need to see if there are any remaining days or not (i.e. total days % 7) Now if there are 1 extra days if we are unlucky it will not be an off day , thus min off day is unchanged , but if we are lucky it will be an off day thus max off day is incremented by 1 , again if there are 2 extra days those 2 may not be off days thus min day is the same , but those two can be off days so max day is incremented again ( i.e. week*2 + 2 ) This logic extends up to extra day = 5 , but if the extra day =6 we are bound to have 1 off day so min day will be incremented then and max off day as before incremented twice ( i.e. week*2 + 2).
halyavin used my successful challenge of D2 to identify the wrong solution and got challenge of D1. :)
What do you say when you submit a solution and the contest gets over — "Every second counts" Was just a heartbeat away! RIP question F.
Does this happen alot??? But still it was a great round.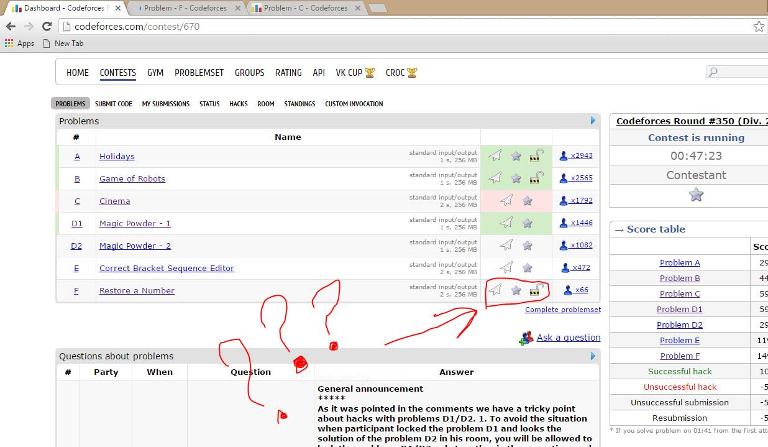
What do you say when you try to submit and the contest gets over — "Every second counts"
Just a heartbeat away. RIP Question F.
Bro there is high chance of getting it wrong still :P
Can string k contains 0 digits in last task ?
No
Am I the only one who miss-read E's statement (such that you need to delete just the pair of brackets but not the whole substring) and implemented an implicit treap?
Я перед началом раунда думал, что частичное решение D будет набирать 500, а полное +1000. Поэтому сначала решил задачу для ограничений D1 и.. был слегка удивлен.
Разделение задач а-ля Code Jam заставило меня затупить так же, как я обычно туплю на GCJ: потратил кучу времени и попыток, пытаясь написать красивое шаманство в D2, а в итоге простого бинпоиска по ответу оказалось более чем достаточно.
Еще обиднее стало в тот момент, когда в последние 20 секунд нашел баг в E, но не успел исправить и отослать. Сегодня однозначно не мой день.
I think it should be a better contest but ...!!! :)
spent so much time writing nice code for E
http://codeforces.me/contest/670/submission/17746555
only to forget to change the size of the segment tree
I feel like shit
Next time generate maxtest & check your solution before submit.
It helps me avoid this mistake.)
Problem E Why my solution got TLE Here is my code:Your text to link here...
This complexity(nlog^2n)
Then another my solution is:Your text to link here...
Both solution Got TLE on test 12. please help me
Problem E..
Why my solution Got Tle in Test 12 Your text to link here...
If I am not mistaken, you iterate from f to s on each delete query. Total complexity O(n^2*log^2(n)).
Problem E why my solution Got Tle on test 12 Here is code:code..
how did a O(n log(n)^2) in problem C gets TLE on test 125 17726278 ?!!!!
My O(N) Time Limit.
http://codeforces.me/contest/670/submission/17727212
How is that even possible -_-
It may be N log N, maps requires O (log N).
it's "UNORDERD MAP"
unordered_map`s constaint may be worse than log in some tests
shouldn't also be fine for that problem?
also be fine for that problem?
here is one: http://codeforces.me/contest/670/submission/17727184
Anti hash-map test.
Why would they put an anti hash-map test leaving the normal map passing in NlogN? are they trolling us ?!
Actually it seems there is something wrong with unordered_map in C++ or the authors designed the test cases that fail hashing only for unordered_map.
Java's HashMap works normally. Which to be honest, I find pretty weird, if you are going to TLE hashing solutions, then make sure you TLE them on all languages.
Mine too! Solution
Too strict! :(
Not too strict because map works in ~800 ms,it's your fault you used unordered_map
Hi, isn't unordered map supposed to be faster,
Please correct me if I am wrong.
In what sense "faster"? Do you mean asymptotically faster or what?
Sometimes it is faster but sometimes it is the very slow,imagine you have a Hash modulo MOD,then when you'll have test like MOD + 1,MOD + MOD + 1,...,MOD * n + 1 it will run in linear time.
It's supposed to be faster on average (runs in O(1)) but in the worst case it runs in up to O(N). The test must have been specially designed to backstab us who used unordered_map. :(((
Can you explain me please where is a problem in my solution: http://codeforces.me/contest/670/submission/17731716 ? I think the complexity of solution is O((N + M) * log(N)) so it don't have to get TLE verdict.
Reading with cin 600.000+ numbers?
I think, it's true but I'm very angry because, for example, this solution http://codeforces.me/contest/670/submission/17742515 got OK verdict.
Nice profile pic.
Hi !
Use
reversetrick.Like this : 21771219.
More information here : Link
Constants from STL...
Similar problem happened in this problem.
O(n^2) gave TLE.
Click
I think test data for D is weak, 17727910 can be broken with an overflow, with large N, large Ai, and small Bi.
Problem C got TLEd with O(n+m) Solution, But passes with scanf and stdio sync off.
Maybe the problem setters shouldnt keep it that borderline where 2 solutions of the same complexity have different result cause of I/O Methods.
EDIT: I was wrong, It is not the IO, but the use of map instead of unordered_map, but that still confuses me, even more so.
Choosing I/O is the same as choosing data structures for the problem. There are more comfortable ones, and less comfortable but faster
Regular cin/cout is hella slow — it's one of the first things you learn when competing. If you were to complain, for example, that sync off didn't pass while only scanf did, that'd be somewhat reasonable — but using regular cin/cout on 400,000+ numbers? Come on.
it may pass only reading but there is also unordered_map,in genereal all the unordered_map solutions don't pass the test 132.
EDIT 2: It's not inserts it's the access

see this on unordered_map documentation
time to go and punish myself for misjudging :)
EDIT 1: It's definitely unordered_map's hashing
So many inserts on a map must have been done in amortized constant
map passed but all unordered_map solutions TLE
I am not sure if I/O is taking time or is it unordered_map's hashing. Eh, I feel like it was a brutal test My stdio sync was off http://codeforces.me/contest/670/submission/17737941 Still TLEd I am going to test Python with raw_input(), it that passes , then cin,cout with sync off should have been allowed to pass
There is an anti-unordered_map test (I hope mine is #132).
The reading part should not be the problem.
wat
Ouch. It is better go to sleep, rather than waiting for the end of systests.
tnx.
same :/
Great contest.
Very soft increase in the difficulty of the problems.
I want to repeat the experience :)
I'm gonna ask a very professional question: how do you use your time efficiently till system testing end? (except pressing f5 rapidly which I'm doing right now)
switching between friend standing and common standing :)
That's what I am doing too, actually. It works well, I must say!
Instead of pressing f5 clicking the refresh button of your browser =D
How come this submission gave TLE on the C problem? 17725819
Maybe it has something to do with mixing cin and scanf?
Maybe because of unordered_map?Change into map and see what happens.
I used the same algorithm:
17733793
but, i prefeer use only "cin" and "cout"
and add: "std::ios::sync_with_stdio(false);"
UPD: in worst case: MAP: O(log(N))
UNORDERED_MAP: O(N)
You shared your solution for problem D1
What is the difference between simple map and unordered map ? I see many people prefer using the later.
I said shit. I've learnt my lesson :(
map is balanced bst (red black tree), the other one unordered is hasing based. While map guarantees O(log n) access, unordered_map generally gives constant time access however in worst case can lead to O(n) per access too
Thanks that was helpful. BTW, in which cases unordered map can lead to O(n) per access .Any general idea ?
I said shit. I've learnt my lesson :(
std::unordered_map does NOT do linear search.
Это был лучший контест, что я когда-либо решал! Огромное спасибо авторам контеста за задачи =)
Тебе определенно нужно порешать задачи с последнего GCJ (их всего 3).
Too slow............System Testing?
Because 100+ tests for each problem.
Actually, it is better to have more complete testing rather than fast and accepting wrong solutions.
Problem D1 gives more points than D2, but it's actually the easy one. Isn't it?
The idea is if you pass the large one you can submit it to both... so D2 is basically a bonus for passing the large input.
I get your point, but how that could be better? It decreases the value of solving the hard version (if it turned out to be pretty hard, then it should be optimal to skip it and just submit the easy version, and your score wouldn't change significantly) IMO. Maybe I'm missing something.
Doofenschmirtz Evil Incorporated!
Slowest System Testing EVER!!!
Is multiset much slower than map ? I got TLE for C due to multiset. I was trying something new and now it failed. :(
The complexity to search for a single item is same as in map. However to count number of occurences of item is linear! ouch
http://www.cplusplus.com/reference/set/multiset/count/
oh my god :((
Holy... I should have checked. God.
TLE Test 132...Thanks Mike :D
seems Codeforces is little deceitful.
instead of waiting so long in pending system test ,you wait so long during system test
I got WA for setting High=1e9 in binary search for D2 . How to calculate maximum value High can get ?
Didn't it failed on pretests? The first pretest had 2000000000 as answer
NO it didn't . I first calculated the number of dish I can make assuming value of k to be 0 . then I BSed the answer with k involved and sum of the 2 was the answer . (For pretest 2e9 can be accomplished using k=0 and 0 after consider k so total ans =2e9 >.<)
You can prove that 2e9 is the highest value of hi.
If n=1 k=1e9 a[0]=1 b[0]=1e9 then the ans is 2e9 , and note that there can be no worse case than this.
Suppose all ai's are equal to 1 All bi's are equal to 1e9
k is equal to 1e9
In this case the answer will be 1e9+1 but you have set high already lower than this so you will get wa. Above comments show that max hi = 2e9
I was lazy to calculate it so I just set:
High = (sum of all bi + k)/(sum of all ai) + 2
(the +2 is redundant but you can never be too safe). This is a simple and obviously correct estimate. Using only that estimate we can conclude that High at about 1014 should for sure do the job.
(ofc you can get better bounds but ain't nobody got time for that)
>.< funny How 1 character makes a difference .
For D1 I just used 1e9 (WANTED to be safe) for the upper bound and failed cause I wasn't aware of int overflow due to such small inputs! (But passed D2...) T_T
The top possible value is 2e9. This can be seen by an example with one ingredient, where you have 1e9 of the ingredient and 1e9 of the magic powder, and you need 1 of the ingredient to make a cookie. You can then make 2e9 cookies with what you have.
1<<33 is enough
It's 2e9 + some const, but be patient, 2e9 + C not anytime is equal to 200...00 + C due to floating point precision error
Подскажите что такое Вклад = -3?
Вклад отображает то насколько полезен пользователь для общества. Чем больше плюсуют ваши посты/комментарии тем выше становится вклад, чем больше минусуют — тем соответственно ниже.
Can someone explain me why I got TLE on pretest with this (problem B)? I used std::sqrt, don't think it will work so slow... http://codeforces.me/contest/670/submission/17732164
I don't know if it is ok, to read long long with %ld?
%ldis forlong, which in most cases is equal tointby size, forlong longyou need to use%lld, reading by%ldgave you some trash insidenandk— http://ideone.com/NDPC4RI liked the round, but if the system tests have to be this long, then no, just stick to the regular rounds.
Why does the testing time bother you at all? :)
DAMN!!! tomorrow is comming,but there're only 75% checked !!! So slooooww!!
Winter is coming!
To be safe,I set the high in D2 to 4e9. But my code fails on test #128 T-T
Did you use int or long long for the 4e9 variable?
Long long int
Nope, there is some other error
Nope, works fine.
Consider this case
3 3
4 5 6
3 4 5
Works fine
i think expected answer is 1 and your code is returning 0
correct me if i am wrong
I used BigInteger and passed 128 =) 17735769
Can someone explain why have i got RE13 on B with this code http://codeforces.me/contest/670/submission/17726464/. It literally ruined this round for me.
When i*(i+1)/2 == k you would get data[-1]
Nope. I would get data[i-1]. i*(i+1)/2 — i*(i-1)/2 = i.
Then it's overflow, i * (i+1)
Nice to participate to
Waiting for system test to end like...
Why is there a penalty for Wrong Answer for pretest 2 in D2? Pretests 1 and 2 don't have penalties right?
as far as i know , Only Pretest 1 does not cost u penalty .
Мое решение задачи C: http://codeforces.me/contest/670/submission/17731716 Как вы можете заметить, асимптотика решения — O((N + M)logN), но вердикт — TL. Видимо, TL ловится из-за долгого считывания. НО я нашел идентичное моему решение по задаче C, которое получило ОК: http://codeforces.me/contest/670/submission/17742515. Как видно, оно отработало за 1918мс, что очень близко к TL. Мне кажется, что мое решение тоже верное, просто работает чуть больше 2 секунд, поэтому прошу пересмотреть вердикт по моему решению.
если решение не проходит из-за ТЛ, то, вроде, его сразу же тестируют повторно. так что твое решение дважды не вложилось во время(:
откуда такая информация?
Я, конечно, не эксперт, но синтаксис ввода/вывода с помощью cin и cout отличается от scanf и printf
like a boss! problem E:
I did it the same way , it took me 20 mins of coding and more than 40 mins of debugging :)
That hash table hit me HARD!! What a great lesson by the problem writers :). Thank you, you guys make me learn something new.
Shouldn't this solution:http://codeforces.me/contest/670/submission/17745728 Fail on cases like "(((((.....)))))" if you start deleting right from the middle of the string this solution would keep iterating over all of the characters in the original string?
anti-hash table test was MESSED up...
Мб баян, но цитата из условия: "Обратите внимание, что запись числа, которое Вася передал Кате, не могла начинаться с нуля, кроме случая, когда передаваемое число и было нулём (в этом случае оно записывалось как единственная цифра 0)."
Крайне расплывчатая формулировка с совершенно ненужной подставой. Сколько ни перечитывал, мне и в голову не могло прийти, что для этого случая в тестах будет 01 и 10, а не просто 0. Ведь чёрным по белому написано что "единственная цифра 0". Нехорошо.
Why did this solution — http://www.codeforces.com/contest/670/submission/17743870 receive a compilation error?
I know that it is unbelievable but I sure that it is happen, during the system test after all my problems have been test I found my rank is 644 and after the contest finished I found it 640 HOW!!!
This already happened to me. I don't have any explanation.
Народ, кто-нибудь может объяснить, почему у меня на системном тестировании так "тормознул" тест 132? При том, что предыдущий тест (тоже при максимально допустимых входных данных) отработал нормально. Заранее спасибо.
Поменял unordered_map на map и зашло...
Мораль: никогда не используйте unordered-контейнеры в C++ — работает дольше, да и набирать тоже дольше.
Почему решение С с multiset падает по времени, а если поменять на map заходит? Вот решение с multiset 17731907 А вот с map 17749945 Разве multiset.count() не за логарифм работает?
Логарифм от размера контейнера, но линейно от количества совпадений. То есть, если в мультисете содержится n единиц и 1 двойка, то поиск двойки займет О(log n), а единицы — O(n).
http://www.cplusplus.com/reference/set/multiset/count/
Понятно. Спасибо. Придется отказаться от multiset... :(
Не нужно ни от чего отказываться. У каждого инструмента свое предназначение.
D1 should be of 500 points and D2 should be of 1000 points. Higher constraints problem should ideally be having more points.
And I automatically agree with you since I failed D1 but not D2 LOL
But to not be biased, I think either scoring is fine. In the way it is it seems the large input is just a bonus score. Those who solve D2 are supposed to also solve D1 correctly anyway. (Well, except in the case of some overflows which many and I have overlooked because of small inputs...)
Nice
So tell me how the problem setters (or a contestant?) generated anti-unordered_map case? How to prevent our solutions from being hacked (´・_・`)
I googled and tried to read gcc headers, but it's too sophisticated. What I could understood are:
unordered_maphas a normal hash table implementation; it divides items into some bucket by its hash value and items with the same hash value are stored by linked list in same bucket.intis just identical function (hash(x) = x).Hashmap has O(n) complexity in worst case (when all the elements store in same bucket). So the solution with unordered_map has O(n^2) complexity.
Yes I realized that, but when you find hashmap while seeking challenge, can you always generate TLE input?
For programs which don't take measures against anti-unordered_map inputs, it seems easy.
Random input: http://ideone.com/bjvJKg
Anti-unordered_map input: http://ideone.com/LAzKjm
Thank you! http://ideone.com/atUji0
Problem D2. Not able to find any error in my solution. It fails in test case 128. Can someone please help in finding out the error. I uploaded the same code for D1 which got accepted. Here is my solution. Please help :p http://codeforces.me/contest/670/submission/17734861
mine fails on 128 as well Code
Overflow, now it passes 17779411
I've been doing F and my code got Runtime_error after cout the output nad I dont know why. Here's my code: http://codeforces.me/contest/670/submission/17828267 Anyone can help, pls?? P/s: my English is not good sry if u mind.
In problem D2 if I take the value of "r" for binary search as 1e10 then I get AC but if I use r=1e12 initially then I get WA as the answer comes something arbitrary like 350488137400 in place of 0 .Is there any constraint on choosing the value of r in binary search as I have been stuck on quite a few questions where probably the problem was that my value of r was near the likes of 1e15 or higher?
WA on test case 2 with r=1e12:237333175.
AC on keeping r=1e10: 237326598.
Could anyone please help me out with this?
Edit: I figured out that my variable "a" was having an overflow despite being long long which gave me the error.