


Problem A: Ebony Ivory
The problem is to find if there exists a solution to the equation: ax + by = c where x and y are both positive integers. The limits are small enough to try all values of x and correspondingly try if such a y exists. The question can also be solved more efficiently using the fact that an integral solution to this problem exists iff gcd(a, b)|c. We just have to make one more check to ensure a positive integral solution.
Complexity: O(log(min(a, b))
Problem B: A Trivial Problem
We know how to calculate number of zeros in the factorial of a number. For finding the range of numbers having number of zeros equal to a constant, we can use binary search. Though, the limits are small enough to try and find the number of zeros in factorial of all numbers of the given range.
Complexity: O(log(n)2)
Problem C: Spy Syndrome 2
The given encrypted string can be reversed initially. Then dp[i] can be defined as the index at which the next word should start such that the given string can be formed using the given dictionary. Rabin Karp hashing can be used to compute dp[i] efficiently.
Also, care must be taken that in the answer the words have to be printed in the correct casing as they appear in the dictionary.
Complexity: O(n * w) where n is the length of the encrypted string, w is the maximum length of any word in the dictionary.
Problem D: Fibonacci-ish
The key to the solution is that the complete Fibonacci-ish sequence is determined by the first two terms. Another thing to note is that for the given constraints on a[i], the length of the Fibonacci-ish sequence is of logarithmic order (the longest sequence possible under current constraints was of length~90) except for the case where a[i] = a[j] = 0, where the length can become as long as the length of the given sequence. Thus, the case for 0 has to be handled separately.
Complexity: O(n * n * l) where n is the length of the given sequence and l is the length of the longest Fibonacci-ish subsequence.
Problem E: Startup funding
Let us denote the number of visitors in the ith week by v[i] and the revenue in the ith week by r[i].
Let us define z[i] = max(min( 100 * max(v[i...j]), min(c[i...j]))) for all (j > = i). Note that max(v[i...j]) is an increasing function in j and min(r[i...j]) is a decreasing function in j. Thus, for all i, z[i] can be computed using RMQ sparse table in combination with binary search.
Thus the question reduces to selecting k values randomly from the array z. Let us suppose we select these k values and call the minimum of these values x. Now, x is the random variable whose expected value we need to find. If we sort z in non-decreasing order:
E(X) = (z[1] * C(n - 1, k - 1) + z[2] * C(n - 2, k - 1) + z[3] * C(n - 3, k - 1)....) / (C(n, k))
where C(n, k) is the number of ways of selecting k objects out of n. Since C(n, k) will be big values, we should not compute C(n, k) explicitly and just write them as ratios of the previous terms. Example: C(n - 1, k - 1) / C(n, k) = k / n and so on.
Complexity: O(n * lgn)
Problem F: The Chocolate Spree
The problem boils down to computing the maximum sum of two disjoint weighted paths in a tree (weight is on the nodes not edges). It can be solved applying DP as in the given solution : http://pastebin.com/L8NNLF3f (Thanks to GlebsHP for the solution!)
Complexity: O(n) where n is the number of nodes in the tree.
Problem G: Yash and Trees
Perform an euler tour (basically a post/pre order traversal) of the tree and store it as an array. Now, the nodes of the subtree are stored are part of the array as a subarray (contiguous subsequence). Query Type 2 requires you to essentially answer the number of nodes in the subtree such that their value modulo m is a prime. Since, m ≤ 1000, we can build a segment tree(with lazy propagation) where each node has a bitset, say b where b[i] is on iff a value x exists in the segment represented by that node, such that 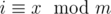 . The addition operations then are simply reduced to bit-rotation within the bitset of the node.
. The addition operations then are simply reduced to bit-rotation within the bitset of the node.
Complexity: O(n * lgn * f), where n is the cardinality of the vertices of the tree, f is a small factor denoting the time required for conducting bit rotations on a bitset of size 1000.
Problem H: Fibonacci-ish II
The problem can be solved by taking the queries offline and using a square-root decomposition trick popularly called as “Mo’s algorithm”. Apart from that, segment tree(with lazy propagation) has to be maintained for the Fibonacci-ish potential of the elements in the current [l,r] range. The fact used in the segment tree for lazy propagation is:
F(k + 1) * (a1 * F(i) + a2 * F(i + 1)...) + F(k) * (a1 * F(i - 1) + a2 * F(i) + ....) = (a1 * F(i + k) + a2 * F(i + k + 1)....)
Example: Suppose currently the array is [100,400,500,100,300]. Using Mo's algorithm, currently the segment tree is configured for the answer of the segment [3,5]. The segment tree' node [4,5] will store answer=500*F(2)=1000. In general, the node [l1, r1] of segment tree will contain answer for the values in the current range of [l2, r2] of Mo's for the values that have rank in sorted array [l1, r1]. The answer will thus be of the form a1 * F(i) + a2 * F(i + 1).... We maintain an invariant that apart from the answer, it will also store answer for one step back in Fibonacci, i.e., a1 * F(i - 1) + a2 * F(i).... Now, when values are added (or removed) in the segment tree, the segments after the point after which the value is added have to be updated. For this we maintain a lazy count parameter (say k). Thus, when we remove the laziness of the node, we use the above stated formula to remove the laziness in O(1) time. Refer our implementation for details: http://pastebin.com/MbQYtReX
Complexity: 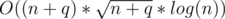






Any advice for how to make sure that our hashing solution passes the systests in future contests ? I used a pair hash with constants( b = 31 , 37 and m = 1e9 + 9 , 1e9 + 7) this contest but that was not enough.
Were we also supposed to keep track of the pairs that we have already processed in problem D besides from what's mentioned in the editorial ?
With hashing you can never be so sure. A personal trick I use is storing hashes of different length strings in different sets to reduce probability of collision.
In D, no need to keep track of the previous pairs, just calculate the next term and see if it is present in the remaining set. It should be ensured that the number of times you use an element should be less than or equal to the number of times the element is present in the given array.
In that case, the cases for D are a bit too strict as my solution got TLE:
http://codeforces.me/contest/633/submission/16362591
Sure the time limit was too strict. :(
But just a small piece of advice, instead of using an another map 'used', you could have subtracted the numbers from the actual map 'have' itself. Just push the used numbers in an array 'used'. Later one could simple restore 'have' using 'used'.
'used' map will result in system calls as it needs to allocate memory every-time for new nodes as u insert elements in it (say malloc/calloc or new) and they are quite costly.
My solution TLE'd on test 99. I changed it to store pairs I already calculated the answer for and it AC'd. Isnt TL a bit too strict here?
My submission is almost same as StoneCold_ — 16362591 and himanshujaju -16364394 but it is taking 904 ms for 99th Test case while in their cases it timed out (>3000 ms).
Can anyone explain. Why ? (was it because of use of 2 maps or something else ?)
I suspect two maps, since it needs allocation space. Also my constant involved should be lot higher than yours due to multiple map value comparisons in my code.
I tried solving C with aho-corasick + weighted job scheduling but got MLE in test case 58. I think this is because in worst case aho-corasick can generate O(m^2) matches when every pattern matches the input string. Am i right?
theoritically yes, I hesitate to use aho corasick yesterday because of that O(m^2) matches, but I just submited it few hours ago and got accepted with speed=265ms and memory=127932 KB
The number of matches isn't too bad, each word has a length of at most 1000, so for any position there are at most 1000 words that match there, giving 107 matches in the worst case, which is quite a lot, but not the worst problem.
How you build the initial tree is a lot more important. For reference, here's my solution that MLE'd one case later than yours: 16359251, and here's one that got accepted: 16382076 (while admittedly still using a lot of memory).
You can compare the two solutions to see what I changed, basically, in the earlier version, a node would store all matches at that position, while in the new version I store a single match, and the index of the next vertex that also contains a match. I'm not sure if this will make the performance much worse (I doubt it), but it reduces memory consumption significantly.
In problem C, I think the O(N × w) time complexity means to check every character ti in the haystack string and a certain length l — to check if titi + 1... ti + l - 1 matches any words in the dictionary. You can calculate the hash of that string in O(1) time, but is it possible to check if the hash exists in the dictionary in O(1) time?
It is possible if you use a dictionary which uses O(1) operations for insert and delete such as unordered_set
There is deterministic solution of problem C without hashing. Just use trie.
Code: 16357979
My solution ( 16364008, 155 ms ) of C without hashing uses another idea: map [length of words] to set of words of this length.
Algiz used similar idea. He had map from length of the string to set of value of hash function.
The only problem is that your solution's complexity is O(n × sumlen).
For example on test generated by this script your solution makes about 14 × 109 operations. Thanks to fast
strcmpit works about 4 seconds on my Macbook Pro, but it is not intended solution.You are right, my solution would fail, if this test was present in systests.
That's strange, that max time was 124 ms on systests, so weak set..
Could you elaborate your trie solution a bit, please? I'm not sure if I got it. And, by the way, what is its time complexity?
Thanks
It's the same idea as the editorial, but instead of looking for hashing values, you will traverse the trie, looking for a word in the dictionary that match with a substring starting from some position.
Let's say dp(i) = it's possible from position i. You will traverse the trie from the root, finding the same characters as the string starting from the ith-position. When you reach a node in the trie that represent a word in the dictionary, make the transition (dp(i + k)) where k is the length of the path you've traversed (which is the length of the word you will use).
The time complexity is the same: O(n * w). For any position, the worst case is using the longest word in the dictionary (maximum: 1000)
Got it. Thanks for the answer!
What was the solution used by checker for hacks in problem C? A deterministic solution with a trie? Or some other deterministic solution? You can't use straightforward hashing because in this case you can't be sure that you'll get correct answer to a given hack (and you can get wrong judge vertict for a hack as a result).
Too short explanations. Please atleast provide the solutions according to your editorial.
A bit more explanation needed for problem D.
I guess complexity for D should be O(n * n * l) not O(n * lgn * l) ?
Thanks for pointing it out. Corrected.
Auto comment: topic has been updated by mkrjn99 (previous revision, new revision, compare).
Auto comment: topic has been updated by mkrjn99 (previous revision, new revision, compare).
what is wrong in my solution for problem D : 16373289
Try this:
0 2 -1 1 0 1 1thanx :)
The logic is wrong and you can't use line
if(dp[l1][l2] != -1) return dp[l1][l2];. Maybe before with some other remaining numbers it was possible to build longer suffix starting from l1, l2 but later it will be impossible because needed numbers are used.And small counter-test for you. Your code prints
5(the answer bigger than n) for:You calculate
dp[0][1] = 4and later you start from 1, 0, 1 and you checkdp[0][1].thanx :)
For E it is said:
The complexity should be O(n * log2 n) in this case, shouldn't it?
RMQ sparse table can be built in O(n*lgn) and queried in O(1).
Ok. You are right.
Could someone tell me why my answer is wrong?[submission:16375142]if gcd(a,b)|c,put Yes.
tests:
3 2 1and9 10 16Why am I getting TLE for my solution for problem D? http://www.codeforces.com/contest/633/submission/16375958
Your solution is TLE as well as WA.
TLE reasons: O(N3) complexity, slow I/O using Scanner. WA: Case
0 -1 -1 2Finally managed to pass system tests: http://codeforces.me/contest/633/submission/16378716
I managed to come up with the method of solving it pretty quickly during the contest but got stuck implementing it and refining it. Anyways, really happy I got it working. Thanks for the reply!
Why TLE?
You don't remove elements from
mapso you iterate over infinite sequence. Test:Why this solution is TLE 16435289 whereas this is AC 16431586 in problem D 633D - Fibonacci-ish
I got it
Delicious contest: in the only interesting problem solutions with complexity O(N·Q) pass.
The difference between the expected O(N.(sqrt N)(log N)) and O(N.Q) solution will only be apparent at higher values of N and Q. But at that point the better solution also takes a lot of time. I guess one could micro optimize the better code to observe the difference at lower values too, but that is something contestants shouldn't have to do. Therefore, sadly it ends up being a very good theoretical question only. I guess it is one of the few reasons dynamic scoring was used
Then it's not a problem for a programming contest, especially if you were aware of that situation
Why did my solution got WA on test 9? I used the same solution with the editorial.
My submission: 16376759
I failed on the same test. Here is a hint: think about the initial elements of your Fib-ish sequence.
Thanks for your hint. I got AC now.
It turned out that sequence with f0 = a[i], f1 = a[j] is different from sequence with f0 = a[j], f1 = a[i].
My solution for A problem (http://codeforces.me/contest/633/submission/16362922) was hacked during the contest and the same solution is now accepted when i submitted it again (http://codeforces.me/contest/633/submission/16377008).
Infact the test case on which i was hacked is not itself valid.(1 1 100000) since range of cwas less than 10000.
HOW IS THIS POSSIBLE??
There was a problem in the validator for the first question. Refer comment http://codeforces.me/blog/entry/43375?#comment-280816
Solution for H: We will use MO's algorithm and segment tree.
Nice!
I have explained the structure of the solution (Mo's algo+segment tree), the crux of the solution (the fact required to be used in the segment tree). Please suggest exactly what more I should add instead of playing sarcasm.
If someone wants to read about segment tree and Mo's algorithm specifically, please refer the following links:
in E, how to deal with increasing size of C(n, k-1)?
Misunderstood the editorial. But my mistake was not in preciseness, in binary search I took the largest index such that vmax[i]*100 <= cmin[i]. But we also need to check (i+1), because cmin[i+1] may be smaller than vmax[i+1]*100, but larger than vmax[i]*100.
Sad that I had code for that but somewhy decided that it's not needed and commented it..
Can someone please elaborate why is 90 the longest sequence length in D ?
Fibonacci(-ish) sequence increases (or decreases) very quickly -- also, it is given that
|a_i| <= 10^9. So at some point numbers will be larger than 10^9 -- to actually know what is the longest sequence length, you can take 2 arbitrary values and check for yourself.Fibonacci numbers increase exponentially. There are actually about 45 Fibonacci numbers from 0, 1, 1, 2, ... till 10^9.
In this question, excluding the case when all the input is zero, the numbers are being added so they will soon reach the maximum limit specified 10^9 quickly.
To actually know the sequence which reaches the length of approximately 90, it is formed as follows-
.....13, -8, 5, -3, 2, -1, 1, 0, 1, 1, 2, 3, 5, 8, 13....
i.e. on right side of 0, write the original fibonacci series and on the left side of 0, write the fibonacci series in reverse with every even position being multiplied by -1.
Well, we can say that the series is completely defined by the first two elements.
In order to get the maximum length of the series, pick the smallest two elements that you can, consider (0, 1).
Now the series that has this will be the smallest, (is what I claim).
0,1 can be had by starting with some number we don't know. Let's build our series backwards and forwards.
Backwards: (0, 1) => (1, 0, 1) => (-1, 1, 0, 1) => (2, -1, 1, 0, 1) => (-3, 2, -1, 1, 0, 1) and so on.
Similarly the forward way is (0, 1, 1, 2, 3, 5,..) (The fibonacci series)
We do this to keep our values as small as possible. Any other series will exceed 1e9 earlier than this.
Total elements in this series = 90 Code
This analysis is good, but I was wondering is there a formal proof of number of fibonaccis <= MAXVAL ?
Great explanations, thanks.
Author after his editorials
I can say I am feeling the same way.
Here is link to AC solutions to A, B and D according to the required complexities as given in editorial
A- log(max(a,b)) for extended_euclid algorithm http://codeforces.me/contest/633/submission/16374965
B- log(n, 2) * log(n, 5) where log(a, b) represents log(a) wrt base b. http://codeforces.me/contest/633/submission/16375458
D- n*n*l in worst case http://codeforces.me/contest/633/submission/16375898 (Thanks to adkroxx for his nice solution)
Hi, I know it's an old comment, but could you please clarify why you took the ceiling of t1 and the floor of t2 on 633A?
the number of numbers having a particular number of trailing zeroes are either 0 or 5 . is there anyway to detect a number whether it have 0 or 5 zeroes mathematically ??
Yes. The highest power of prime p in n! can be given by: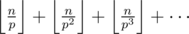
Since the number of zeros in a number is min(power of 2 in the number, power of 5 in the number), we can simply calculate the power of 5 in n by the above formula and assume it to be the number of zeros in n!, since in n!, the power of 5 will definitely be less than the power of 2 (trivial to see by the above formula).
if the expected solution of E had sparse table, why was the memory limit so strict?
Even in 3rd and 4th, Maps and Sets take an extra LOGN time. They have simply ignored it. I don't understand how?
In the editorial, we have mentioned the theoretically correct solution complexity since we assume that we can use unordered_map instead of map and the similar for set. The time limits definitely allow correct solutions which use map, set, etc. instead.
Even unordered_map has high constants. Since some solutions passed doesn't justify these constraints. The proper bound on complexity is (len(str) * 1000 * logn).
We have seen even Java solutions using RMQ sparse table passing well within the memory limits so I would not called it very strict.
On another note, I have often noticed that we as competitive programmers often tend to ignore the importance of space complexity; to stay safe we often use long long instead of int, etc. In this question the 100*x part in the question was deliberate to make some people believe they need long long, whereas in actuality they just need an int since x ≤ 107
What can be more frustrating?
TLE AC
AC
WA
Difference 2 symbols.
not true
Where can I get test input? I need for Problem C.
Есть ли возможность скачать тест, на кот-м программа завалилась? Похоже нет это очень неудобно.
По-моему было бы очень полезно добавить возможность на форме протокола тестирования для скачивания нужного теста и/или всех.
Could anybody can give some tips in Problem F?
The task is to find two paths in the tree so that no node appears in both paths and the total weight of all nodes in the paths is maximum.
This can be calculated efficiently using dynamic programming. Let d[a][b] the maximum weight of a single path in a subtree "downwards" from node a when node b is considered as the parent of node a. Now the answer is the maximum of all d[a][b]+d[b][a] where a and b are any two adjacent nodes.
This may be too late, I wrote a description in quora
In E, we can do without RMQ sparse table using normal dp. Say visitors and revenue are v[] and c[] respectively, and z[] stores then : int max_v = v[n-1]; int min_c = c[n-1];
http://codeforces.me/contest/633/submission/16382326
Plz tell me why am i getting WA on test case 28 In ques C(using trie)... http://codeforces.me/contest/633/submission/16384219
My solution for C is Accepted , but I still think it could have been TLE.
I didn't use hashing or trie.
can someone find a testcase that could have been used to hack my solution ?
yes, someone could hack it :)
thanks for this neat testcase :)
I guess I was lucky there was nothing like this in the main tests :D
Could someone, please, clarify these questions for me?
..dp[i] can be defined as ..What is
ihere? What are we iterating?.. the index at which the next word should start ..What is the next word? Next after what?
.. such that the given string can be formed using the given dictionary ..What is the
given string? What is thegiven dictionary?I tried my best to pinpoint the places of confusion. Forgive me, if these questions seem stupid. I needed to come up with something better than 'please, help, I don't understand' :)
In problem B why factorial of a number trailing zeros are min value of highest power of 2 and highest power of 5. I just want to feel this logic can anyone please explain it easily? Thanks.
Any number containing one or more zeros at end must be a multiple of 10, right? 10's are formed by the primes 2 and 5. 2*5 = 10.
That's why. If you still don't feel it, it's a very well known mathematical problem, google it and you'll find many sources.
Someone please explain the solution of problem C using Rabin-Karp hashing...
Hey , Could somebody explain the solution for problem H? I couldn't understand how to use the mentioned fact in lazy propagation to solve this problem.
Please have a look at the expected solution for this problem: http://codeforces.me/contest/633/submission/16396613
I cant access the link mentioned.
Try this: http://pastebin.com/MbQYtReX
hi please help: i submitted the problem D but i get Time Limit Exceeded on Test 3 :( this is my code:16392423 Thank You.
Can somebody explain, in problem E, how the binary search works? For each z[i], ans(j) is some function that first increases and then decreases, but it's not strict? (It is the minimum of an increasing function and a decreasing function, so it either decreases or increases and then decreases)
It is the minimum of the increasing function, say f(x) and decreasing function say, g(x).
Binary search uptill the maximum index i such that f(i) is strictly less than g(i). Then the answer is either going to be on index i or index (i + 1) .. If you try to think about it using diagrams then it would be clearer.
Oh, yes, I see it now. I thought of it before as simply function that is used in the ternary search, and didn't consider the combination of individual functions at all XD
Auto comment: topic has been updated by mkrjn99 (previous revision, new revision, compare).
Can someone please explain ? What is bitset and how to uptade it ?
Bitset is just a set of bits (binary digits) that can be used as an efficient alternative to a boolean array. The advantage of using a bitset is that certain operations such as OR, AND, count are faster than a boolean array. The underlying structure of bitset utilises the fact that a word (32-bit or 64-bit depending on platform) is just a combination of bits and bit operations on them are very efficient due to the hardware support. In this case taking a bitset of size 1000, we can assume that the and of two bitsets is computed in 1000 / w machine operations, where w is the word size (typically 32 or 64).
In Problem B , on test case 41
My code gives 0 as number of values of n having 26151 zeroes on terminal and ideone.
But on codeforces it gives 5 as output.
I can't understand why?? Can somebody help me?
My ideone solution :- Ideone Solution Link My codeforces solution :- Codeforces Solution Link
Constarints for problem B are wrong. Upper limit of m is given 10000 where in Test case 41 it's 26151. plz try to Resolve such issues.
Please read the problem statement carefully. Constraints for problem B state M <= 100,000.
Increase the upper limit of the cases you are calculating for. Your link on Ideone doesn't work correctly either because the numbers are of the order 1e5, and you are computing till 5 * 1e4.
This is correct now.
Make the constant = 1,000,000.
The editorial right now does little to help me find the solutions since it uses jargon like Rabin Karp hashing, euler tour, Mo's algorithm, lazy propagation etc. which I have no clue about (I do hope I am not the only one with this problem). It would help if you could dumb it down a bit so that even amateurs like me can follow what you say.
You're not the only one feeling it, but I guess we'll just have to google. Sometimes yes, the author could give better editorials, but if we've never heard of the method used for the solution, we can't expect the author to teach us, we'll have to read up on it ourselves. There's quite a good explanation on the wikipedia page for Rabin Karp hashing anyway.
Good luck! :)
I do agree that expecting the author to teach us concepts is not correct. But, I do like it when the editorial focuses on the logic to solve the problem rather than enforcing techniques. This would help me write a code which works without having to go back to school. It is probably wrong of me to expect this from all authors though :)
We are not enforcing techniques on you. The logic used for solving the problem is too tightly inter-linked with the techniques mentioned. Nevertheless, there may be other solutions to the problems as well.
Regarding the techniques, please have a look at these links:
Why am I getting WA for my solution for problem C? 16406153
Explanation of problems C and D could have been explained in a more detailed manner :)
For Problem E, to calculate z[i], it can be observed that if 100*v[i] >= c[i] then clearly z[i] = c[i]. When 100*v[i]<c[i] we can only get better value for z[i] if z[i+1]>100*v[i] but we cannot get better than c[i] therefore z[i]= max(100*v[i],min(z[i+1],c[i])) in this case.
Omg, sir, you made my day.
Problem 633C - Spy Syndrome 2 :
My solution using prefix trie should get TLE on a test like this :
my AC solution : 16367453
Test File Here
Can you provide some reference for prefix trie?
Unfortunately, I've studied Trie from Arabic tutorials. But he uses slides written in English, So I hope it helps.
Here
I can't understand problem F by just reading codes by others...Who can help me?I have not find discussion about it....
Why this solution is TLE 16435289 whereas this is AC 16431586 in problem D 633D - Fibonacci-ish
I got it
In Problem 633C - Spy Syndrome 2 I got AC and WA in 2 solutions only differ in
map<int,int>gets AC and when i changed it tounordered_map<int,int>i gets WA on test 53!! could anyone explain why that happened?!First AC submission 16433158
Second WA submission 16433164
Can anyone explain the difference between hash_map and unordered_map
Hah, deceivingly it has absolutely nohting to do with those maps. You have integer overflows when computing h and v which leads to undefined behaviour, which means that behaviour of your code is not defined. More precisely it is allowed to behave differently when executed many times. That is not just plain and unreal theory, it is really happening :). I copied your code that got accepted and submitted it two times and first time 16559248 I got WA on 17th test and second time 16559257 I got WA on 53rd test. However when I copied your code with unordered_map and removed overflows it got ACed 16559243 :).
I think someone said this before (on another blog?) but I couldn't find it and I think it is worth repeating.
The editorial solution as written doesn't really work without additional tricks, since it's complexity is actually
This becomes O(n2) for a star graph, and for example the given author's solution seems to TLE on such a test.
To fix this, we need to have a way to accumulate values from a subtree and also invert one value (of the child to be calculated next) — which can be done with prefix+suffix "sums" or just working it out based on the problem. I would love to see simpler ways to use the idea of dp[edge] if anyone has any!
What you are saying is correct and I realize it just now!
Neverthleless, the actual correct solution used for the contest was by GlebsHP : http://pastebin.com/L8NNLF3f. I am adding it to the editorial.
There is a discussion about how to apply the idea of dp by edge keeping linear time complexity, ffao wrote a great implementation., I don't mean that's simpler but interesting: http://codeforces.me/blog/entry/43683?#comment-285628
Oh god I thought problem C is similar to GGCJ Round D problem C, where the ciphertext is shuffled in random order.
Somehow this code managed to stay up till case 67. Your text to link here...
for C why this code aint work WA at test 46 https://codeforces.me/contest/633/submission/77006664
For problem D can someone explain me how to prove that the length will be logarithmic.
Alternative solution for 633F - The Chocolate Spree
Find the diameter. If you remove the diameter, you get some subtrees. There are two cases for the two optimal paths:
You can check both cases in $$$O(n)$$$.
216754901 Problem C solution using trie
Anyone solved A using the gcd(a,b) divides c ,i understand that the parameters should be positive , but what if the ones i find weren't both positive , i try doing a translation but doesnt work.