


100889A - A Beautiful Array
Given an array of integers, find a permutation of the array to maximize the sum 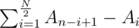 .
.
If we observe the formula closely we see that we have to calculate 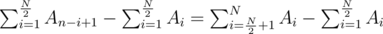 . If the array is of odd length, we can simply skip the middle element. This can be maximized by putting the large numbers in the right half, and the small numbers in the left half. One good way to do this is to simply sort the array in ascending order.
. If the array is of odd length, we can simply skip the middle element. This can be maximized by putting the large numbers in the right half, and the small numbers in the left half. One good way to do this is to simply sort the array in ascending order.
Complexity: 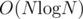 .
.
Code: http://ideone.com/nJddvt
100889B - Backward and Forward
Given an array A, make it palindromic using minimum merging operations. In one merging operation two adjacent elements can be replaced by their sum.
To make an array a palindromic we can simply apply merging operations n - 1 times where n is the size of array. In that case,size of array will be reduced to 1. But, in this problem we are asked to do it in minimum number of operations.
Let’s denote by f(i, j) as minimum merging operations to make a given array a mirror from index i to index j. If , i = j answer is 0.
If Ai = = Aj, then there is no need to do any merging operations at index i or index j . Our answer in this case will be f(i + 1, j - 1).
But if arr[i] ≠ arr[j], then we need to do merging operations. If arr[i] > arr[j], then we should do merging operation at index j. We merge index j - 1 and j, and update Aj - 1 = Aj - 1 + Aj. Our answer in this case will be 1 + f(i, j - 1).
For the case when Ai < Aj, update Ai + 1 = Ai + Ai + 1. Our answer in this case will be 1 + f(i + 1, j).
Our answer will be f(0, n - 1), where n is size of array A. This problem can also be solved iteratively using 2 pointers(first pointer pointing to start of the array and second pointer pointing to last element of the array) method and keeping count of total merging operations done till now.
Complexity: O(N).
Code: http://ideone.com/lIHYJF
100889C - Chunin Exam
You are required to reach (N, M) from (1, 1), where in matrix P cells are blocked and you are allowed two type of queries:
- Look at adjacent squares. - Go to adjacent squares.
You can use constant memory and at-most O(12 * P) queries.
How would you come out of a maze full of darkness(i.e. you can just check adjacent cells) and with you having memory just enough to remember the last cell you came from? The idea is very intuitive: just walk along the walls(assume blocked cells as a wall)! Its guaranteed that path exists, so in O(P + N + M) queries worst case, we should safely reach our destination.
So, we put our left/right hand on wall and start walking in that direction. For each cell that we are visiting, we maintain the current direction in which wall is. Based on that, we try to extend the wall in possible directions by looking at adjacent blocked cells.
The worst case where you might perform O(12 * P) queries is when there is a pattern like this:
| | | | || | |0| || |0| | || | |0| || |0| | |
Here 0 denotes a blocked cell.
Code: http://ideone.com/Fintxx
100889D - Dicy Numbers
Author : vmrajas
Tester : Toshad
Explanation :
If n is represented in its canonical prime factorization as follows :
n = p1k1 * p2k2...pjkj
The number of numbers having their number of positive divisors equal to n with their highest prime factor ≤ m'th prime number is given by :
ans = m + k1 - 1Cm * m + k2 - 1Cm... * m + kj - 1Cm
Explanation of Formula : The number of divisors of a number x :
x = p1α1 * p2α2...piαi
is given by :
y = (α1 + 1) * (α2 + 1) * ... * (αi + 1)
where y denotes number of divisors of number x. We need to find number of x such that their corresponding y = n.
The problem can be seen as for every kz where z goes from 1 to j , we need to distribute kz balls into i boxes. This reduces the problem to the formula stated above.
Computation of ans : Given the formula stated above, we can compute it as follows :
Prime factors of all number from 1 to 2 * 106 can be computed efficienlty using sieve. Now, if we know the prime factors of a given number n , the answer can be computed in O(number of prime factors of n). As this number is very low (~15) , 105 queries can be easily handled.
Code : http://ideone.com/w202fV
100889E - Everyone wants Khaleesi
You are given a Direct Acyclic Graph(DAG) with no multi-edges and self-loops. Two players play a game in which Player 1 starts at node 1 and has to reach node N by taking one existing directed edge in the graph in one move. Player 2, in one move can remove any existing edge of the graph. Game ends when player 1 has reached node N or he can't make a move. Report who wins if both play optimally.
This is a troll problem! Initially it might look really complex, but the very basic idea is that if player 1 is at distance 1 from his destination and its player 2's move, player 2 can just remove the edge that player 1 could use to reach node N in next move. The only way player 2 loses if when nodes 1 and N are directly connected, in which case player 1 will win in first move.
Complexity: O(1)
Code: http://ideone.com/oiXQTR
100889F - Flipping Rectangles
The problem asks for the maximum area of destination rectangle that can be covered by the source rectangle by flipping it atmost k times.
Let us formalize a good notation for the problem, so that it becomes easier to solve it.
Let us translate the two rectangles in such a way that the left bottom corner of the source rectangle becomes the origin. As translation does not affect the dimensions of the rectangles, the answer won't be affected because of this operation. Let a denote the side length of the source rectangle along X-Axis and b denote the side length of the source rectangle along Y-Axis. Let (c,d) denote the left bottom corner of the destination rectangle in new coordinate frame. Let e,f be its side lengths along X-Axis and Y-Axis respectively.Therefore the corners of the destination rectangle can be given by (c,d),(c + e,d),(c,d + f),(c + e,d + f).
Let Rect(i,j) denote the rectangle of length a along X-Axis and length b along Y-Axis such that its left bottom corner is at point (i * a,j * b). Therefore, the original position of the source rectangle can be referred to as Rect(0,0). Now, the given operation of flipping can be represented as follows
- Flipping it right Rect(i,j) goes to Rect(i + 1,j)
- Flipping it left Rect(i,j) goes to Rect(i - 1,j)
- Flipping it above Rect(i,j) goes to Rect(i,j + 1)
- Flipping it below Rect(i,j) goes to Rect(i,j - 1)
Now, the minimum number of flips required to take source rectangle Rect(0,0) to Rect(i,j) can be found out as |i|+|j|. Let Rect(x,y) denote the rectangle whose intersection area with the destination rectangle is non-zero and |x|+|y| is as minimum as possible.
Key Observation : Atleast one of the rectangles Rect(x,y), Rect(x + 1,y), Rect(x,y + 1), Rect(x + 1,y + 1), Rect(x - 1,y), Rect(x - 1,y - 1), Rect(x,y - 1), Rect(x + 1,y - 1), Rect(x - 1,y + 1) covers the maximum intersection area with the destination rectangle.
Therefore, if we are able to find such x, y, we can find the answer by finding the maximum intersection area of destination rectangle with the above 9 rectangles. To consider the extra constraint of maximum k flips, we also need to check if |i|+|j| ≤ k while considering Rect(i,j) for maximum intersection area.
How do we find the required x and y?
These can be found out by the observation that Rect(x,y) will contain at least one of the corners of destination rectangle or the points (c,0), (c + e,0), (0,d), (0,d + f). Rect(x,y) will not contain the corners of destination rectangle in cases when the endpoints of the destination rectangle are on the opposite sides of the coordinate axes.
For a given point the required i, j such that Rect(i,j) contains the point can be computed easily using integer division of the coordinates of point by the sides of the source rectangles.
For more details http://ideone.com/u97AYD
100889G - Gift Pack
Since XOR and AND are bit-wise operators, we can process x, y and z bit by bit separately. Lets try to construct x, y and z which gives optimal answer from MSB to LSB. Since they are bounded by 1018 we need to consider less than 63 bits.
Let's say x has i, y has j and z has k at a bit position 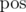 , the contribution of this position in answer is
, the contribution of this position in answer is
((i^j) + (j&k) + (k^i)) * 2pos
So now if there was no constraints on values of x, y and z we would move from MSB to LSB and simply chose the combination of bits of x, y and z at every bit-position that resulted in maximum contribution to the answer. But how to deal with constraints on them?
A thing to note is:
Let's say we are constructing a number p bit by bit from MSB to LSB. If at any position i we make a choice such that p becomes greater than a number q at that bit position, no matter what we choose for further bit position of p, it can never become ≤ q.
Same thing can be said for p ≥ q.
So while constructing x, y and z from MSB to LSB, the choice of values we have, for each of them, at every bit position depends on the previous choices of values L, R, A and B.
We solve the problem using dynamic programming.
Define a state as 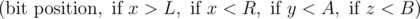 . Following code explains the transition between states.
. Following code explains the transition between states.
//f1 denotes if x has become > L
//f2, g1, g2 denotes if x, y, z have become < R, < A, < B respectively
//pos is the bit position currently being looked at
lld solve(int pos, bool f1, bool f2, bool g1, bool g2)
{
if(pos<0) return 0; //base case
lld ret = dp[pos][f1][f2][g1][g2];
if(ret!=-1) return ret;
ret = 0;
int d1 = 0, d2 = 1; //min, max values the bit can take at this postion for x
if(bit(pos, L) == 1 && !f1) d1 = 1; //adjust min value at pos for x
if(bit(pos, R) == 0 && !f2) d2 = 0; //adjust max value at pos for x
int D1 = 0, D2 = 1; //min, max values the bit can take at this postion for y
if(bit(pos, A) == 0 && !g1) D2 = 0; //adjust max value at pos for y
int DD1 = 0, DD2 = 1; //min, max values the bir can take at this postion for z
if(bit(pos, B) == 0 && !g2) DD2 = 0; //adjust max value at pos for z
//try all possible combinations for this postion for x, y, z
for(int i=d1;i<=d2;i++)
for(int j=D1;j<=D2;j++)
for(int k = DD1;k<=DD2;k++)
{
//calculate the contribution this bit cam make in final answer
lld tmp = (1LL*(i^j) + 1LL*(j&k) + 1LL*(k^i))<<pos;
bool ff1 = f1, ff2 = f2;
bool gg1 = g1, gg2 = g2;
//adjust new flags (f1, f2, g1, g2) depending on current combinations
if(i > bit(pos, L)) ff1 = 1;
if(i < bit(pos, R)) ff2 = 1;
if(j < bit(pos, A)) gg1 = 1;
if(k < bit(pos, B)) gg2 = 1;
//update the ans depending on result for this combination
ret = max(ret, tmp + solve(pos-1, ff1, ff2, gg1, gg2));
}
//found the result for this state yay :D
return (dp[pos][f1][f2][g1][g2] = ret);
}
100889H - Hitting Points
You are given N points of a polygon pi in counter clockwise order. In each query, for a different l, k, we put polygon with origin at point pl and edge pl to p(l + 1)%N on x-axis; and we put an infinite rod on line x = k. When this rod falls in counter-clockwise direction, we are supposed to output the indices of vertices where this rod touches first time.
Most interesting observations in g### eometry come via visualisation and drawing. Consider the following image.
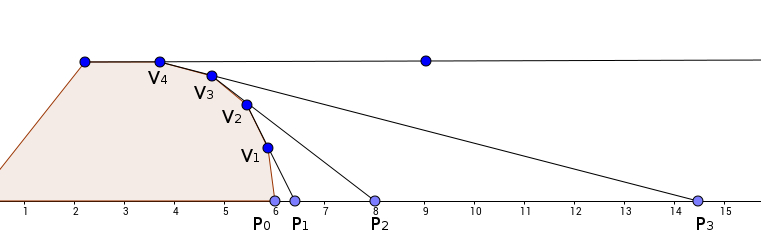
I have projected edges Vi to Vi + 1(for i ≥ 1) on new x-axis(defined by base). If the vertical rod lies in region (P0, P1), it'll touch vertex V1, if its in region (P1, P2), it'll touch vertex V2 and so on. So, we notice that all edges in counter-clockwise direction are creating a continuous region such that if k lies in that region, the rod will touch the first point of that edge. If you think about the reason, its quite intuitive. We just have to find the region in which k lies, which can be done via binary search on the edges of polygon in counter-clockwise direction. We need to consider those edges whose intersection with new x-axis lies to right side of polygon(i.e. +ve x-axis); so basically are searching over right hull of convex polygon.
For finding the distance on new x-axis we take intersection with the base line(i.e new x-axis) and see distance from base points. Also, we can easily take care of rod touching an whole edge, which happens when k is at the boundary of one of the regions of an edge.
Complexity: 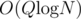 .
.
Code: http://ideone.com/w6DGKA
100889I - iChandu
Given a string S of length n consisting of only lower case letters, you have to replace a character at exactly 1 position with the character '$' such that the number of distinct palindromes in the final string is maximum.
What we need to do is for every position i count the number of:
- new palindromes that would be created, if the substitution was made at index i.
- old palindromes that would be destroyed, if the substitution was made at index i.
For the first case, since the new character is distinct from all the earlier ones it can only create odd length palindromes with '$' at the middle.
Hence the number of palindromes created when a substitution is made at index i, will be equal to the number of odd length palindromes that already exist with index i as the center. This can be found for every i in O(n) using Manacher's algorithm.
For the second case, what we need to note is that the maximum number of distinct palindromes in a string of length n is n, because at every index i, only 1 distinct palindrome can be ending there.
Now consider one of the distinct palindromes present in string S, let it be P.
P might occur in S more than once. After the substitution, P will no longer exist if and only if the index of the substitution is present in each and every occurrence of P. For index i to be present in each occurrence of P, i must be present in the overlap of every occurrence of P. The overlap of every occurrence of P is equal to the overlap of the first and last occurrence of P. So if the substitution is made in the overlap of the first and last occurrence of P, P will be 'destroyed'.
Hence we need to find all distinct palindromes and for each one we need to find the first and last occurrence of it. This can be done with a palindromic tree.
Construct a palindromic tree for S, this will provide the first occurrence of every distinct palindrome. Similarly construct a palindromic tree reverse of S, this will provide the last occurrence of every distinct palindrome. Now for every distinct palindrome preform a range update of +1 for the range of overlap of the first and last occurrence of that palindrome, because a substitution in that range will destroy that palindrome.
Now finally check which index i has maximum of number of palindromes created - number of palindrome destroyed.
Final complexity: O(n)
Code: http://ideone.com/bxH8O0
100889J - Jittery Roads
Given a weighted undirected tree, handle 2 types of queries:
- Update weight of edge between two nodes u, v.
- For a subset of nodes(special nodes), find for every special node the distance to the special node farthest from it.
First let’s look at a simpler version of the problem. Consider there were no updates and all nodes of the tree were special nodes. Let the tree be rooted at node 1. For every node u, the farthest node from it will either be in its subtree or not. With one DFS, we can compute for every node u, what is the maximum distance to any node in its subtree.
-> in_subtree[u] = max(in_subtree[v] + E(u,v)) for all ‘v’, where ‘v’ is a child of ‘u’ and E(u,v) is the weight of the edge between ‘u’ & ‘v’.
With another DFS, we can compute for every node u, what is the maximum distance to any node NOT in its subtree.
-> out_of_subtree[u] = max(in_subtree[v] + E(u,p) + E(v,p)) for all ‘v’, where ‘v’ is sibling of ‘u’ and ‘p’ is the parent of both.-> out_of_subtree[u] = max(out_of_subtree[u], out_of_subtree[p] + E(u,p)), where ‘p’ is the parent of ‘u’.
Finally for every node u, answer will be the maximum of in_subtree[u] and out_of_subtree[u].
Coming to a slightly more advanced form of the problem, consider there are no updates but now special nodes can be any subset of nodes. When we have a query with K special nodes, we can construct an auxiliary tree of those K nodes and solve for that new tree with the DP used above.
To construct an auxiliary tree, we need all K special nodes and LCAs of every pair of special nodes. But LCAs of every pair of special nodes is equal to LCAs of every adjacent pair of special nodes when the special nodes are sorted in preorder of the tree(arrival time of nodes in DFS). Now for the weights of the edges in the auxiliary tree, weight of edge between node u and v will be equal to distance between nodes u and v in the original tree. This can be handled if distance between every node u and root of original tree is precomputed.
Now to handle updates as well. Note that for every node, the only information that we require and that can be changed after updates is the distance to root. If edge between node u and its parent p is updated from w1 to w2, the only changes will be for distance to root from every node v in u's subtree, and the change will be same for all, i.e. for every node v in subtree of u:dist_to_root[v] = dist_to_root[v] - w1 + w2
Now if we maintain an array of dist_to_root[] sorted in preorder of nodes, any subtree is a continuous range. Thus the updates of edges can be handled with an array that can handle:
- Range Update(add w2 - w1 to range of subtree of u)
- Point query(query for
dist_to_root[u])
This can be handled using a Segment Tree or Fenwick Tree.
Complexity:
- Update
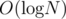
- Query
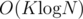
Solution: http://ideone.com/UyhQDX
There are others approaches as well, such as:
- Updates can be handled using HLD (Longer code and slower).
- Centroid Decomposition; Solution: http://ideone.com/2YnsZc
- Breaking apart the queries into those with
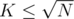 and those with
and those with 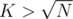 . Apply O(K2) brute force for first case and O(N) DFS on entire tree for latter case.
. Apply O(K2) brute force for first case and O(N) DFS on entire tree for latter case.
100889K - Kill Bridges
Setter : Baba
Tester : itisalways42 , karanaggarwal
Problem Statement :
Given a connected undirected unweighted graph with N nodes and M edges, you can add at most K edges in the graph, tell the maximum number of bridges that can be removed from the graph. There will be Q queries, each specifying a different K .
Solution :
First of all, shrink the 2-edge biconnected components of the given graph and build it's Bridge Tree.The problem now reduces to :
Given a tree , we need to do select 2*K leaves of the tree and do their matching such that if a pair of leaves (u,v) is matched, we color the path from u to v in the tree. We want to maximize the number of colored edges after the paths joining all the K pairs has been colored. Note that in the process an edge might be colored multiple times but it would be counted only once in the final answer.
Before we solve the above problem, let us look at the following two lemmas :
Lemma-1 : In the optimal solution , the subgraph formed by the colored edges would be connected.
Proof : If it is not so, let (u,v) be an edge such that it is not colored and there exists colored subgraphs on either side of this edge in the tree. Let (x,y) be a pair of matched leaves towards the left side of the edge and let (p,q) be a pair of matched leaves towards the right side of the edge. Without loss of generality, we can match (x,p) and (y,q) such that whatever edges were colored earlier remain colored and the edge (u,v) is now also colored. Same argument can be inductively extended and we can say that in the optimal solution the subgraph formed would always be connected.
Lemma-2 : The center of the tree would always be a part of the optimal connected subgraph.
Proof : The proof of this is left as an exercise to the reader (Hint : For K=1, we would always join the end points of the diameter )
Using the above two lemma's, we can move on with the implementation of the greedy approach as follows :
1. Root the tree at its center.
2. Break the tree into chains using HLD type idea, where at any node a special child would be the one that has longest chain lying in it's subtree with one end point at that node.
3. For every leaf, define contribution of that leaf as the length of chain that ends at that leaf. The contribution can be found out as follows :
void dfs(int u,int p,int len=0)
{
bool isLeaf=true;
for(auto w:tree[u])
{
if(w==p)continue;
isLeaf=false;
if(far[u]==far[w])dfs(w,u,len+1); //special child
else dfs(w,u,1); //start a new chain
}
if(isLeaf)cntbn.PB(len);
}
Sort the leaves in descending order of their contributions and for a query K, pick the first 2*K leaves from the sorted order and add their contribution to get the final answer.
Code: http://ideone.com/pLCPcP
100889L - Lazy Mayor
Problem Idea : vmrajas
Author : itisalways42
Tester : hulkblaster
Problem Statement:
Given an undirected weighted graph of n nodes, m edges and a non-negative integer k, you need to find out for each pair of nodes u,v, Let the shortest distance between u and v using atmost k edges be dist[u][u]. We have to compute dist[u][v] and the count of paths from u to v with atmost k edges such that the distance of such paths is equal to dist[u][v].
Difficulty:Medium
Explanation:
The problem can be solved using dynamic programming. Let dp[x][y][z] be the shortest distance between node x and node y using atmost z edges and let cnt[x][y][z] denote its count. The recurrence to compute dp[x][y][z] can be given as :
dp[x][y][z] = min(dp[x][i][z/2] + dp[i][y][z-z/2],dp[x][y][z]) where i goes from 1 to n.
The base case :
dp[i][j][0] = 1 , if i==j
dp[i][j][0] = 0 , otherwise
dp[i][j][1] = g[i][j]
where g[i][j] is the length of the edge between node i and j (0 if it doesn't exist.)
Using the above recurrence the 2-D matrix representing the shortest distance between any pair of nodes using at-most K edges can be computed using matrix exponentiation. Also, the cnt table can also be computed along with the exponentiation to compute the dp table.
Have a look at the code below for implementation details.
Code : http://ideone.com/9r975m







Problem D is missing.
Adding soon.
Added.
At problem K, what do you mean through the center of the tree? Can you please explain why the greedy approach works? And, also, we choose the first 2K leaves, but how to pair them? As far as I can see, it seems that it's optimal to pair them after considering the euler order as follows: the first one with the K+1 th one, second with K + 2, and so on. But I have no proof of this strategy...
For Problem D, shouldn't the formula be (m+k1-1)C(m-1) * (m+k2-1)C(m-1) * ....*(m+kj-1)C(m-1) or which is equivalent to (m+k1-1)C(k1) * (m+k2-1)C(k2) ....(m+kj-1)C(kj) ?
Could not understand the explanation of problem D. Can anyone do a better explanation?
LCAs of every pair of special nodes is equal to LCAs of every adjacent pair of special nodes when the special nodes are sorted in preorder of the tree(arrival time of nodes in DFS).
How to prove this statement ?