


How to solve this problem from recent Codechef Long Challenge??
→ Обратите внимание
До соревнования
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
03:02:41
Зарегистрироваться »
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
03:02:41
Зарегистрироваться »
*есть доп. регистрация
→ Трансляции
→ Лидеры (рейтинг)
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
→ Лидеры (вклад)
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 156 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
→ Найти пользователя
→ Прямой эфир






Codeforces (c) Copyright 2010-2024 Михаил Мирзаянов
Соревнования по программированию 2.0
Время на сервере: 23.11.2024 14:32:20 (h1).
Десктопная версия, переключиться на мобильную.
При поддержке

Auto comment: topic has been updated by sophisticated1 (previous revision, new revision, compare).
Hi! i guess the answer is polynomial of k-th degree. So you could just use Lagrange Interpolation. Again it is only guess.
Ok, here's how I solved it:
First of all notice that given a set of lengths s, they represent a convex polygon if (assuming s is sorted, so s|s| is the largest element). A kind of "generalized triangle inequality". Rearranging yields:
(assuming s is sorted, so s|s| is the largest element). A kind of "generalized triangle inequality". Rearranging yields: 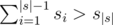 .
.
So the problem is: Given the set {1, 2, 3, ... n}, how many k element subsets obey our equation? Constructing an dp solution based on that should be pretty straightforward. That gives 30 points already.
dp solution based on that should be pretty straightforward. That gives 30 points already.
In order to optimise further, we need some combinatorics: How about counting the number of subsets that do not work? Then the answer is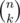 — (this number). Turns out this is easier to compute (..at least for me ^^). So
— (this number). Turns out this is easier to compute (..at least for me ^^). So  .
.
Let's solve for equal first. That is, given the highest element, in how many ways can we select k - 1 smaller numbers, such that their sum is equal to this highest element. That can be computed once again using dp in . To handle "smaller equal" and not just "equal", we can use a "kind of prefix sum" (consult my submissions for details). That results in 60 points.
. To handle "smaller equal" and not just "equal", we can use a "kind of prefix sum" (consult my submissions for details). That results in 60 points.
To gain full score, we have to transform the recurrence into a matrix (my matrix has dimensions ((k - 1)2 + 2) × ((k - 1)2 + 2) — basically keeping track of the previous f(n, k) values, 1 as well as the answer). Using matrix exponentiation we can compute the result in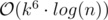 per test case. That's still not fast enough.
per test case. That's still not fast enough.
To optimise, notice that there are just 7 - 3 + 1 = 5 different matrices we're taking powers of. So I just precomputed the powers of two for these matrices (taking per matrix). For each query you then just multiply your result vector with the corresponding powers of two. That reduces the time per testcase to
per matrix). For each query you then just multiply your result vector with the corresponding powers of two. That reduces the time per testcase to 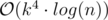 and gives full score.
and gives full score.
You can check my submissions here — they're basically representing the though process I've described above.
I hope that gives you an idea. The details are "left as an exercise for the reader" :P. Nah, just kidding — I can elaborate if you don't understand parts of it. But try it yourself first, it's really not that hard + a lot of fun as well :)
UPD: The editorial has been published: here
Ok, it doesn't seem to be a polynomial:)
Note, that if you have a recurrence of degree k, you can calculate nth element in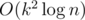 time by exponentiating polynomials modulo polynomial, no precalculations required. Also if you know that your recurrence is of length k, and can easily calculate the first 2k values, then using Berlekamp–Massey algorithm you can immediately get the recurrence in O(k2).
time by exponentiating polynomials modulo polynomial, no precalculations required. Also if you know that your recurrence is of length k, and can easily calculate the first 2k values, then using Berlekamp–Massey algorithm you can immediately get the recurrence in O(k2).
That certainly sounds interesting!
Could you describe some more details? I'm not really getting the idea yet :)
I'll show an example, hope it will be clear how to use it in general case.
Suppose we want to calculate a recurrence an = 2an - 1 - 5an - 2, a0 = 1, a1 = 2:
Move everything to the left side:
Take the left side and replace $a_n$ with xn, and remove the common power of x:
Now to calculate 10th element of the sequence, calculate
and multiply the constant term with $a_0$, the next coefficient with a1, etc:
Multiplication modulo polynomial takes $O(k^2)$ time, so exponentiation takes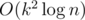 .
.
I can see that polynomial exponentiation can be used to calculate binomial coefficients C(n, k). The multiplication polynomial is 1 + x. So it is indeed complexity instead of
complexity instead of  when we used matrices exponentiation. However I didn't understand how the polynomial trick can be applied to the problem being discussed.
when we used matrices exponentiation. However I didn't understand how the polynomial trick can be applied to the problem being discussed.
Here is an excel table I've created where each F(n, k) is a number of sets that do not work, the value that should be subtracted from C(n, k) in order to receive the answer. I solved the problem using matrices exponentiation with degree 23.
Is it possible to get a recurrence polynomial from this table?
Yes, using Berlekamp–Massey algorithm on the last column will give its recurrence relation (though I think you should find partial sums first).
BTW, in this problem the recurrence polynomial is equal to
Please explain the portion : "generation of matrix from recurrence relation " ??
Our 60 points recurrence looks something like that (omitting modulo and memorisation):
We want (the
(the  thing, because my recurrence allows xi ≥ 0, so I'm just assuring that xi > 0). In other words:
thing, because my recurrence allows xi ≥ 0, so I'm just assuring that xi > 0). In other words: 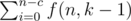 , with
, with  .
.
To calculate something like that using matrix exponentiation, we're basically trying to transform some vector vn into vn + 1, by multiplying vn with some matrix A. vn needs to contain all information to calculate vn + 1.
I used the following vector:
The 1 is representing f(n, 0) and sum is the sum of f(n, k - 1) values. Now we need a matrix A, to transform vn into vn + 1. The vector has (k - 1)2 + 2 elements, so we need a matrix of this size as well.
Here's how my transformation matrix looks like for k = 3:
It's just the recurrence from above, represented using linear equations.
So what we want is An - c - k. Multiply that with a vector of "base cases" (e.g. initial values for n = {k - 2, k - 3, ...0 }). Those can be computed using our dp from above in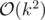 . Once you did that, sum represent the number of "bad" subsets.
. Once you did that, sum represent the number of "bad" subsets.
Auto comment: topic has been updated by sophisticated1 (previous revision, new revision, compare).