


This is the second part of Hunger Games Editorial, hope you'll enjoy it :) And again, thanks for stuff for awesome contest, congratz for survivors too!
UPD: Problems B, D, E, Q, T, W are now available, more soon :)
Editorial Hall of Fame:
Radewoosh .I. Chameleon2460 sepiosky adamant xuanquang1999 rnsiehemt Fcdkbear JoeyWheeler
Problem A: Good Numbers.
Tutorial by: xuanquang1999
Call LCM(i, j) the lowest common multiple of i and j.
First, we should analyse that if x is divisible by LCM(p^i, q^j), then x is divisible by p^i and q^j at the same time.
Call set s(i, j) the set of number x in range [l, r] that x is divisible by LCM(p^i, q^j). Call |s(i, j)| the size of s(i, j). We can find out that:
|s(i, j)| = |s(1, j)| - |s(1, i-1)| = r/LCM(p^i, q^j) - (l-1)/LCM(p^i, q^j)
Call set d(i, j) the set of number x in range [l, r] that x is divisible by LCM(p^i, q^j) and doesn't belong to any set d(ii, jj) (i <= ii, j <= jj, i != ii or j != jj and LCM(p^ii, q^jj) <= r). Call |d(i, j)| the size of d(i, j).
Our answer is sum of |d(i, j)| with i > j and LCM(p^i, q^j) <= r.
We also find out that |d(i, j)| = |s(i, j)| — sum of |d(ii, jj)| (i <= ii, j <= jj, i != ii or j != jj and LCM(p^ii, q^jj) <= r). So we can use recursion with memorize to this.
Our biggest problem is now checking for overflow (since LCM(p^i, q^j) can exceed int64). I found a pretty easy way to do this in Pascal:
function CheckOverflow(m, n: int64): boolean;
const e = 0.000001;
oo = round(1e18)+1;
var tmp, tmpm, tmpn, tmpu, tmpr: double;
begin
tmpm:=m; tmpn:=n; tmpu:=GCD(m, n);
tmp:=tmpm/tmpu*tmpn;
tmpr:=oo;
exit(tmp-e < tmpr);
end;
I wonder if there is a way to do this in C++ (without bignum)
kpw29's update: Let's check if p*q = ret gives overflow. We can check if ret divides q and ret / q = p.
Complexity of whole solution: O((log l)^2 * (log r)^2 * (log l + log r))
Code; http://ideone.com/R1AgnQ
Problem B: Hamro and array
Tutorial by : xuanquang1999
We first calculate array d with d[i] = a[1] - a[2] + a[3] - a[4] + ... + a[i - 1] * ( - 1)(i + 1) in O(n) (if i is odd, d[i] = d[i - 1] + a[i], else d[i] = d[i - 1] - a[i]). Then, for each query, if l is odd then ans = d[r] - d[l - 1], else ans = -(d[r] - d[l - 1]).
Complexity: O(n + q).
His code: http://ideone.com/kMalCH
Problem C:
Problem D: Hamro and Tools
Tutorial by : xuanquang1999
We can solve this problem by using Disjoint — Set Union (DSU). Beside the array pset[i] = current toolset of i, we'll need another array contain with contain[i] = the toolset that is put in box i. If no toolset is in box i, contain[i] = 0. For each query that come, if box t is empty, then we'll put the toolset from box s to box t (contain[t] = contain[s] and contain[s] = 0). Otherwise, we'll "unionSet" the toolset in box s with the toolset in box t (unionSet(contain[s], contain[t]) and contain[s] = 0).
Finally, we can find where each tool is by the help of another array box, with box[i] = current box of toolset i. Finding array box is easy with help from array contain. The answer for each tool i is box[findSet(i)].
Complexity: O(n).
Code: http://ideone.com/Te3wS9
Problem E: LCM Query
Tutorial by: Fcdkbear
Our solution consists of 2 parts: preprocessing and answering the queries in O(1) time.
So, in preprocessing part we are calculating the answers for all possible inputs.
How to do that? Let's iterate through all possible left borders of the segments. Note, that moving the right border of the segment do not decrease the LCM (LCM increases or stays the same). How many times will LCM increase in case our left border is fixed? Not many. Theoretically, every power of prime, that is less than or equal to 60 may increase our LCM, and that's it.
So for each left border let's precalculate the nearest occurrence of each power of each prime number. After that we'll have an information in the following form: if the left border of the segment is i, and the right border is between j and k, inclusive, LCM is equal to value. So, for each segment with length between j - i + 1 and k - i + 1 answer is not bigger than value. We may handle such types of requests using segment tree with range modification. In a node we will keep two numbers — double value of the LCM (actually, it's logarithm: note that log(a * b) = log(a) + log(b), so instead of multiplying we may just add the logarithms of our powers of primes) and the corresponding value modulo 1000000007.
After performing all the queries to segment tree we may run something like DFS on the segment tree and collect the answers for all possible inputs.
The overall complexity is O(n * log(n) * M), where M is a number of prime powers that are less than or equal to 60
Code: http://pastebin.com/7zcYTced
Problem F: Forfeit
Tutorial by: sepiosky
First we make an array F[] for each edge , for an edge like e if after deleting it we have two components C1 and C2 , then f[e] = |C1| * |C2| , It's easy to undrestand that if we increase weight of edge e by 1 the total sum of distances will increase by F[e].
Now we consider Sum as minimum total sum of distances , from where Min(Sum) = (N - 1)2 We can be sure that for  answer is 0 .
answer is 0 .
Now we can solve the problem with DP Where DP[E][S]=number of ways we can weight tree with sum S using first E edges.Note that first we subtract Sum from K and we use dp for collecting K - Sum
DP[E][S] = DP[E - 1][S - (L[E] * F[E])] + DP[E - 1][S - ((L[E] + 1) * F[E])] + ... + DP[E - 1][S - (R[E] * F[E]]
This DP is O(K * N2) but we can reduce it to O(K * N) (where N < 400 )
Source code: http://ideone.com/WOZfbg
Problem G: Hamro and Izocup
Tutorial by: sepiosky
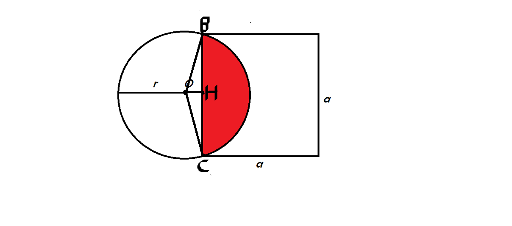
let S1 be the area of SECTOR BOC and S2 be area of TRIANGLE BOC  Answer = S1 - S2
Answer = S1 - S2
We can calculate OH using pythagorean theorem and length's of OB & HB( = α / 2) . so we can calculate area of triangle BOC .
for calculating the area of sector BOC first we should find  . We name as
. We name as 
in triangle BOH according to Law of sines :  =
= 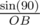 sin(O / 2) =
sin(O / 2) = 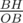 = 2 *
= 2 * 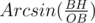
So area of sector BOC = 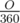 * π R2
* π R2
Now we have S1 & S2 So we have answer !
Source code: http://ideone.com/Zkvh6p
Problem H: Hamro and circles
This problem is basically the same as G. First, imagine that second circle is a square and solve G. Then, swap the circles, solve G again and add results.
Source code: http://pastebin.com/ZvJJcAKP
Problem I:
Problem J:
Problem K: Pepsi Cola <3
There are at least 2 different solutions for this problem, I'll try to explain them.
Chameleon2460's solution:
Let's define A as log of the biggest value in sequence T. By the problem constraints, A ≤ 17. I'll describe an O(3^A) solution, which will pass if implemented without additional log factor.
We'll try to find for all possible values of OR how many subsequences have that OR. (Taking the result is pretty easy then).
Define X contains Y iff (XORY = X). Notice, that OR X might be created only from values, which X contain.
We'll write subset DP in a quite standard way. For all values of X, we'll first assign dp[X] = 2L, where L is number of values, which X contain. (L can be computed the same time we write DP, just for all subsets of active bits in X, we'll add L[x] += L[subset]). Then, we will just subtract all values, because not all the subsets have OR equal to X. But we'll have this computed before entering X, so we can remove them without any additional effort.
Source code: http://pastebin.com/R6B2a41u
My old code, which is O(3^A * A), and gets TLE, but it's quite easier to understand: http://pastebin.com/7GNLJQ7E
JoeyWheeler's solution:
We consider a number to be the sum of some powers of two. (X = 2i + 2j + 2k + ...).
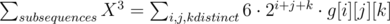 + similar terms for 22 * i + j and 23 * i.
+ similar terms for 22 * i + j and 23 * i.
Where g[i][j][k] = the number of subsequences with bits i, j and k set. We can use the Mobius DP similar to that described in this solution: http://www.usaco.org/current/data/sol_skyscraper.html to calculate f[i] = # of elements in the input array which are "supersets" of i in O(nlgn). Then, to calculate g[i][j][k], we can calculate how many elements of the array contain bit i but not j,k or bit i,k but not j etc (call these types of requirements classes) through inclusion exclusion with f[] in O(3 * 23 * 23). Then by iterating over subsets of the classes to be included in our subsequence and doing some simple math we can determine g[i][j][k] in O(223 * 23 * 23). The overall complexity is thus O($n lg n + log^3 n) See code for details.
Source code: http://pastebin.com/Hphc3k2y
Problem L:
Problem M: Guni!
Tutorial by: sepiosky
We can solve this problem using 2 segment trees. In first tree we keep array a and after processing each query of type 1 on it we add score of gi to second tree and for queries of type 2 we process this query on second tree and add result to it.
In first tree we keep negative of array a and for queries of type 1 we apply RMQ on it for finding minimum element in the gi's interval , its obvious that absolute value of minimum element in that interval is maximum element in gi , cuz we kepp negative of ai's . also only information needed from gi's are their maximum element( their score ) , so after getting answer of queries of type 1 from first tree we only add max element of gi( that is negative also ) to the second tree .
for queries of type 2 we use RMQ again this time on second tree and now we have answer for query . answer of this query is needed information for this Guni!(gi) so we add this number to second tree again .
In the end the answer is sum of all elements in second tree (scores of Gunis).
Code: http://ideone.com/n00BPJ
Problem N:
Problem O:
Problem P:
Problem Q: Mina :X
We can preprocess answers for each set size with the following DP: dp[0] = dp[1] = 0
dp[i] = min(max(dp[j] + 1, dp[i — j] + 2) for each 1 ≤ j < i.
Also, we should find what j gives optimal answer, we'll need it later.
Therefore, when we'll get a set S of size i, we'll already know what is correct answer for it.
When we know which j gives optimal answer, we can just query first j elements from our set and query them.
If the answer is "Yes", we should take those elements (and extract every other from S). Else, we should extract those j elements.
Solution: http://pastebin.com/cQ9vFkPc
According to sepiosky this may be done with Fibonacci search. His code: http://ideone.com/3dTmfO
Problem R:
Problem S:
Problem T: The ranking
rnsiehemt's explanation:
Consider the simplified case where we know that, for some interval, every competitor is either before the interval (say there are S of these competitors), after the interval, or somewhere inside the interval with uniform probability over the whole interval (say there are K of these). Then if this arrangement happens, each of the K competitors then has a chance to come each of S + 1th, S + 2th, ..., S + Kth.
Note also that if we consider all endpoints together and then take the intervals between consecutive endpoints: then for each interval, every competitor will either not cover that interval at all, or will completely cover that interval (and thus if they are in it, they will have a uniform probability of being anywhere in that interval). Also, there are O(N) of these intervals.
This gives us the simple algorithm: for each interval (O(N)), for each competitor i, (O(N)), calculate dp[S][K] = the probability of S other competitors appearing before this interval and K other competitors appearing inside this interval (which we can do in O(N3) with DP). However, this is overall O(N5) which is too slow. So we need to try and calculate "dp[S][K] for all competitors except i", for every i. One idea is to calculate dp[S][K] for all competitors, and then "subtract" each competitor with some maths. Overall this would be O(N4). Theoretically this is possible but in practice it is too inaccurate.
Instead we can calculate this with divide and conquer (overall O({N4}lgN), or buckets . For example, for divide and conquer we can calculate f(l, r) = the dp[S][K] for all competitors outside of the range [l, r), and then recurse on f(l, mid) and f(mid, r).
Problem U:
Problem V:
Problem W: Palindrome query
Consider strings S and S', to make implementation easier. We'll use hashing to comparing their substrings. We'll store their values in a Fenwick or Segment Tree. Suppose we change position x. (Do not forget to remove previous value!) Then, instead of p1[x] * pot[x] we'll have p2[x] * pot[x] at this place. We add this value to our data structure, and we're done.
For each query we'll use binary search to answer it, as when there's palindrome of length K, we're sure there are palindromes of length K-2, K-4, ....
Source code: http://pastebin.com/gn4wNe6a
Source code by adamant : http://ideone.com/8kLke7
Problem X:
I'll try to write all solutions as soon as possible :)







Problem B: Hamro and Array
We first calculate array
dwithd[i] = a[1]-a[2]+a[3]-a[4]+...+a[i-1]*(-1)^(i+1)inO(n)(if i is odd,d[i] = d[i-1]+a[i], elsed[i] = d[i-1]-a[i]). Then, for each query, if l is odd thenans = d[r]-d[l-1], elseans = -(d[r]-d[l-1]).Complexity: O(n+q).
My code
Problem D: Hamro and Tools
We can solve this problem by using Disjointed-Set Union (DSU). Beside the array
pset[i] = current toolset of i, we'll need another arraycontainwithcontain[i] = the toolset that is put in box i. If no toolset is in box i,contain[i] = 0.For each query that come, if box t is empty, then we'll put the toolset from box s to box t (
contain[t] = contain[s]andcontain[s] = 0). Otherwise, we'll "unionSet" the toolset in box s with the toolset in box t (unionSet(contain[s], contain[t])andcontain[s] = 0).Finally, we can find where each tool is by the help of another array
box, withbox[i] = current box of toolset i. Finding arrayboxis easy with help from arraycontain. The answer for each tool i isbox[findSet(i)].Complexity: O(n).
My code
Thank you for your explanations, added. Btw how to correct formatting in blogs?
The words in the white box with red font can be done with "inline" (you can find it in "source code" toolbar)
PS: By the way, how did you write the array "d[i] = a[1]-a[2]..." in special form?
Problem E:
Our solution consists of 2 parts: preprocessing and answering the queries in O(1) time.
So, in preprocessing part we are calculating the answers for all possible inputs.
How to do that? Let's iterate through all possible left borders of the segments. Note, that moving the right border of the segment do not decrease the LCM (LCM increases or stays the same). How many times will LCM increase in case our left border is fixed? Not many. Theoretically, every power of prime, that is less than or equal to 60 may increase our LCM, and that's it.
So for each left border let's precalculate the nearest occurrence of each power of each prime number. After that we'll have an information in the following form: if the left border of the segment is i, and the right border is between j and k, inclusive, LCM is equal to value. So, for each segment with length between j - i + 1 and k - i + 1 answer is not bigger than value. We may handle such types of requests using segment tree with range modification. In a node we will keep two numbers — double value of the LCM (actually, it's logarithm: note that log(a * b) = log(a) + log(b), so instead of multiplying we may just add the logarithms of our powers of primes) and the corresponding value modulo 1000000007.
After performing all the queries to segment tree we may run something like DFS on the segment tree and collect the answers for all possible inputs.
The overall complexity is O(n * log(n) * M), where M is a number of prime powers that are less than or equal to 60
Code
We don't need segment tree, map is enough. #4lksQD
By the way, shouldn't we move this discussion to the Hunger Games group?
By the way we have no way to post there as blog, editorial in many comments is not the best idea as well :/
I have manager access to this group now for some reason, so I can do that (or at least to make a blog post with a link to this blog post; this option seems to be even better)
Problem K
We consider a number to be the sum of some powers of two
X = (2i + 2j + 2k + ...)
Where g[i][j][k] = the number of subsequences with bits i, j and k set. We can use the Mobius DP similar to that described in this soln http://www.usaco.org/current/data/sol_skyscraper.html to calculate f[i] = # of elements in the input array which are "supersets" of i in O(nlgn). Then, to calculate g[i][j][k], we can calculate how many elements of the array contain bit i but not j,k or bit i,k but not j etc (call these types of requirements classes) through inclusion exclusion with f[] in O(3 * 23 * 23). Then by iterating over subsets of the classes to be included in our subsequence and doing some simple math we can determine g[i][j][k] in O(223 * 23 * 23). The overall complexity is thus O(nlgn + log3n) See code for details.
Edit: Fixed link to code
the link is not available for people who did not solve the problem...
There's a slightly easier solution. After you've computed f[i], let g[i] = 2^(f[i]). Then, you can reverse the "superset" process on g[i] (which is basically your inclusion/exclusion). You can see my code here for more details.
Problem A: Good Numbers.
Call
LCM(i, j)the lowest common multiple of i and j.First, we should analyse that if x is divisible by
LCM(p^i, q^j), then x is divisible byp^iandq^jat the same time.Call set
s(i, j)the set of number x in range [l, r] that x is divisible byLCM(p^i, q^j). Call|s(i, j)|the size of s(i, j). We can find out that:|s(i, j)| = |s(1, j)| - |s(1, i-1)| = r/LCM(p^i, q^j) - (l-1)/LCM(p^i, q^j)Call set
d(i, j)the set of number x in range [l, r] that x is divisible byLCM(p^i, q^j)and doesn't belong to any setd(ii, jj)(i <= ii,j <= jj,i != ii or j != jjandLCM(p^ii, q^jj) <= r). Call|d(i, j)|the size ofd(i, j).Our answer is sum of
|d(i, j)|withi > jandLCM(p^i, q^j) <= r.We also find out that
|d(i, j)|=|s(i, j)|—sum of |d(ii, jj)|(i <= ii,j <= jj,i != ii or j != jjandLCM(p^ii, q^jj) <= r). So we can use recursion with memorize to this.Our biggest problem is now checking for overflow (since
LCM(p^i, q^j)can exceedint64). I found a pretty easy way to do this in Pascal:I wonder if there is a way to do this in C++ (without bignum)
Complexity of whole solution: O((log l)^2 * (log r)^2 * (log l + log r))
My code
Could you please send me source code of your comment via PM? It'll be much easier to insert it into editorial
To overcome overflow in C++ , I used function to multiply two numbers a and b in O(log a)
which detects if a number become bigger than
rthen return -1Why we don't multiply them using doubles and product < r + eps and if it is, product them using long longs and check? eps can equal 100 or something like that.
not sure about your solution, but I didn't say there's no other ways to overcome overflow
My idea to defeat overflows was as follows: Let's check if P * Q = RET gives overflow (and RET exceeds unsigned long long). Just check if Q divides RET and RET / Q = P.
I think I used similar ideas.
Here is my code
There is a much simpler solution that also does not encounter overflow problems.
Firstly, to find the answer for [l, r], we can find the answer for [1, r] and subtract the answer for [1, l - 1], so we only need to solve the problem for [1, n] and then apply it twice.
If q divides p, the answer is 0. Otherwise if p divides q, the answer is .
.
Otherwise, observe that
Trivial code
Very nice and simple solution. I think kpw29 should add this into editoral, too.
If p divides q your answer returns n/p which is not correct as if l =1 r= 10 p=3 q= 6 . The answer will be 2 not 3. Your solution here gives all f(x,p) >= f(x,q) but we need f(x,p) > f(x,q). This can be removed by removing this case.
Here is an explanation for problem O. I don't want to include my code though since it's really ugly :).
Problem O: Cheque
Naive solution: For each query, use Dijkstra to count the number of vertices within distance k. Keep track of already visited nodes so we don't count them twice. Complexity is O(n2log(n)) , which is way too slow.
How to improve this? Every time we visit a node, remember the distance from the starting node. If we come across this node again but with an equal or greater distance, then there is no point in visiting this node again.
Isn't complexity still O(n2log(n))? The distance to a node must be a non-negative integer less than k, and there are only k of these, so we only need to visit each node at most k times. Complexity: O(k * n * log(n)) , which works since k is small.
code for your solution ;)
Actually, you don't need "priority" queue. Because of you can visit every node at most k times complexity won't be larger. It will be O(k * n).
Here's the code http://ideone.com/kyL0J2
I think in problem A best way for getting out of owerflows is Python !
Problem R:
You can pick any spanning forest F you want and increase edge weights in such a way that F is the unique MSF. Just increase the weight of all edges that are not members of F by a very large number.
So, if there exists a spanning forest F which is not an MSF, the graph is adorable: just make F the unique MSF. If not, then the graph can't be adorable: after increasing, there must be some MSF, and it was an MSF before increasing as well.
So, the question is whether there is a spanning forest which is not minimal, i.e. which has a higher weight than the weight of a MSF. To find the answer, compute the maximal spanning forest and check if its weight is same as the MSF weight. You can find the minimum and maximum SF using https://en.wikipedia.org/wiki/Kruskal%27s_algorithm
Now we know how to calculate the answer for a single graph, but we need it for many graphs. The important observation is that adding an edge to an adorable graph can't make it non-adorable, for the following reason: if the edge connects two different components, then every SF must contain that edge, and the weight of both the minimum and maximum SF increases by exactly the new edge weight, so the difference between the maximum and minumum stays the same. Otherwise, the edge connects two vertices in the same component, so it's optional to put it in the tree, so the minimum SF weight either decreases or stays the same, while the maximum SF weight either increases or stays the same — this time, the difference between the max and min can either stay the same or grow.
So we know that the answer has the form 000...000111...111, we just need to find the location of the first 1. Use binary search.
Problem S:
XOR is a very special operation. If you XOR the same number twice, it is the same as not XORing it at all. This means the sum of two pretty numbers is another pretty number.
Let us denote the set of pretty numbers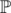 and our set of integers
and our set of integers  .
.
Given this fact, we can make some useful observations. Firstly, if we add a new integer x to ,
,  will not change if x was already in
will not change if x was already in  . Moreover, if x is not a pretty number, then the size of
. Moreover, if x is not a pretty number, then the size of 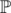 will increase by a magnitude of 2. This means that we can only have log2(109) ≈ 30 numbers we need to keep track of in our set.
will increase by a magnitude of 2. This means that we can only have log2(109) ≈ 30 numbers we need to keep track of in our set.
This leaves us with two questions. How do we determine whether or not a number is pretty, and how do we determine the kth prettiest number? The answer to both of these is row reduction (or Gaussian Elimination). We will construct a matrix where each row corresponds to the binary representation of a number in , and row reduce this matrix to obtain a new set of integers
, and row reduce this matrix to obtain a new set of integers 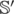 that will have the exact same set of pretty numbers as before the transformation.
that will have the exact same set of pretty numbers as before the transformation.
After row reduction, we will be left with a set of integers where each one has a distinct leading bit positions (bits of high value). Moreover, if a leading bit appears in a certain position in one of our numbers, no other numbers will have a 1 in that position.
With our modified set of numbers, we can now solve our two questions.
To determine whether or not a number q is a subset XOR of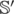 , we look at the binary representation of q. If there is a 0 in a certain position, then our subset XOR cannot contain the number from
, we look at the binary representation of q. If there is a 0 in a certain position, then our subset XOR cannot contain the number from 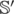 which has a leading bit in that position (if it exists). And if there is a 1 in a certain position, then our subset XOR must contain the number from
which has a leading bit in that position (if it exists). And if there is a 1 in a certain position, then our subset XOR must contain the number from 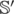 which has a leading bit in that position (if it exists). If at any point we need to include a number that does not exist in
which has a leading bit in that position (if it exists). If at any point we need to include a number that does not exist in 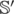 , then q is not pretty. Additionally, if after including and excluding numbers, our subset does not equal q, it is not pretty either. If we add q to our set of numbers, then we need to perform row reduction again.
, then q is not pretty. Additionally, if after including and excluding numbers, our subset does not equal q, it is not pretty either. If we add q to our set of numbers, then we need to perform row reduction again.
To determine the element, notice that because of the distinct and exlusive nature of the leading bit positions, when determining the rank of a pretty number, we need only consider the position of the leading bits. Moreover, if we sort
element, notice that because of the distinct and exlusive nature of the leading bit positions, when determining the rank of a pretty number, we need only consider the position of the leading bits. Moreover, if we sort 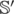 , the elements we choose will correspond the the binary representation of k - 1.
, the elements we choose will correspond the the binary representation of k - 1.
Complexity is O(log3k + nlogk), where k is the size of the query numbers, up to 109.
Could anybody explain, why complexity in F is O(n * k)? We have n * k states in DP and counting each costs O(k) in the worst case, so it looks like O(n * k^2). Actually, because F[i] >= n — 1, we have
O(n * k * (k / n)) = O(k ^ 2), but this is also to much.
in each step when we are updating the dp for first N edges , we know that in next step we should update dp for first n+1 edges , we know value of F[n+1] and also we know that updating dp[n+1][...] just uses dp[n][...] , so we can use prefix sum with ratio F[ n+1 ]( pre[i]=dp[i]+pre[i-F[n+1] ] ) in each step in dp and in next step for each state we can find answer in O(1) so the time complexity is O(N * 2 * k)=O(N * K)( look at code )
I've got it. Thank you
I don't want to sound self serving (although I really am), but isn't the solution I presented to A clearly better than the one added to the main post? Perhaps there is a little bit of bias since kpw29 seems to have had the same solution as the one chosen? :P
You should send Miyukine the source code of your comment via PM so he can easily insert it into editorial.
Oh good point... for some reason I thought there was a way to view a comment's source code, or at least to copy the comment with latex intact...
Problem T: The ranking
To do it without extra log in complexity, we can calculate dp values for every prefix and for every suffix of competitors. Then we we multiply prefix i - 1 and suffix i + 1 to get dp for all competitors except i-th one.
Can you explain how to multiply/merge a prefix/suffix in o(n^2 lg n), the best i could find for the merge step was O(n^2 lg n) using FFT.
^ This, it's not easy to merge two ranges of big lengths. I have a theoretical O(N4) that utilises commutativity and unmerging ranges of length anything and 1, but precision errors force me to use a slower, yet more precise mixture with the simpler O(N5) bruteforce.
Sorry, I indeed can't do it in O(n4).
Let's check if p*q = ret gives overflow. We can check if ret divides q and ret / q = p.
In competition I couldn't prove correctness of that. So I did this : first find Maximum possible coefficient for p that no exceed the MaximumNumber . then check it with q. I think this is easy , safe and self-proof.
this is my Accepted solution : http://ideone.com/YVbmOt
Problem S: Godzilla and Pretty XOR
Totally a linear algebra problem :) To solve this problem we should keep the minimal set of numbers (let's call it basis) such that every pretty number can be obtain as xor of sum elements from basis. Also as we want to get the k-th number we should keep basis in some simple form. Let's say there are n elements in basis. Then we want every element to has its mots significant bit not to appear in any other element. It is simply to do with Gauss method. After that let's query k-th number we can obtain. Easy to see that if k = 2a1 + 2a2 + ... + 2at then the answer is xor of a1, a2, ..., at elements of basis. Total complexity is .
.
My code (it is much more simple then explanation): #0KF9Ra
hey man..could you just explain how are you making the basis vector
Can anybody explain why these two submissions don't work?
http://pastebin.com/KQNyW5NZ
^This goes into an infinity loop while binary searching.
http://pastebin.com/GYHtBc48
^This gets a wrong answer on a systest, but I can't find which edge case its failing on.
Thanks
It would be cool if you pasted them onto a different link (like pastebin.com), because others cannot access your code. :)
Fixed :)
C:
We'll be counting all indices modulo N. By subtracting two successive sums, you get Ai + 3 - Ai = Di = Bi + 2 - Bi + 1. Now, there are two cases for N divisible and not divisible by 3; let's describe the latter case first.
If we fix A0, we can successively find A3k for all k, which (in this case) means we'll find the values of all elements of A[] before reaching a cycle when trying to "find" the value of A0 for k = N. If this "new value" a of A0 doesn't coincide with the one we initially chose, then there's no solution, since adding any number to A0 means adding that same number to all elements of array A[] and also to a, which always leads to a contradiction. For the same reason, if there's no contradiction once, then any solution obtained this way satisfies all equalities for Bi — except one (which vanished due to subtracting for Di), w.l.o.g. B1. In order to satisfy it, we can see that we need to add (B1 - A0 - A1 - A2) / 3 to all elements of A[]. If that's not an integer, there's no solution for the problem in integers; otherwise, we found one!
when it's divisible, just split the given array into three based on remainders of indices mod 3 and apply an approach similar to that for N non-divisible by 3 on each of them to find a solution that satisfies the equalities for Di. We need to satisfy w.l.o.g. B1 again — we can arbitrarily choose A0, A1 and assign a suitable value to A2 to satisfy it, because this time, changing A0 or A1 doesn't affect A2.
The problem statement contained strange requirements (|Ai| ≤ 109 and Bi ≤ 1018); in reality, any solution is acceptable (there are multiple solutions for N divisible by 3, a single solution for non-divisible) and Bi are much smaller, so there's no need to worry about overflows. Time complexity: O(N).
I:
All non-deleted roads should form a minimum spanning tree, so the answer is the sum of all roads' weights minus sum of MST's roads' weights. The answer is -1 iff the initial graph isn't connected. Time complexity: O(N2).
J:
This is an excercise in centroid decomposition. The right vertex to ask is a (there can be two, in which case either one works) centroid of the given graph. If that's the special vertex, we're done; otherwise, we can remove it, which splits our tree into several disconnected trees and we're told which tree we should look for the special vertex in — which we can handle recursively. One of the most basic properties of the centroid is that each of those trees has at most N / 2 vertices, so there are at most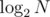 centroid searches and questions necessary.
centroid searches and questions necessary.
Since a centroid can be found using DFS in O(N) time, the actual time spent on this is O(N + N / 2 + N / 4 + ...) = O(N).
L:
First, let's consider all edges with weights containing 1 as their 29-th bit. If all paths from S to T require taking one of them, then the answer is at least 229. Otherwise, it's less than 229. In the latter case, we should discard all those edges and repeat with the 28-th bit. In the former, we can add 229 to the answer, set the 29-th bit of every edge's weight to 0 (as in: we should ignore that bit forever, since we already know it's 1 in the answer and OR works bitwise) and again repeat with the 28-th bit, without discarding any edges.
How to find out if all paths from S to T require taking one of the specified edges? Lol BFS. On the given graph without the specified edges.
So, we need to run BFS 30 times (actually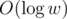 times). The total time complexity is therefore
times). The total time complexity is therefore 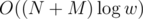 ; the answer is -1 iff there's no path from S to T in the initial graph.
; the answer is -1 iff there's no path from S to T in the initial graph.
N:
http://codeforces.me/blog/entry/17612
O:
This is a pretty standard problem. All you need to do is maintain the min. distance of any city from any one containing a killer, or distance K in case that minimum is ≥ K. When adding a killer, we can run a BFS starting from this vertex. When we check an edge during the BFS and see that the min. distance of a killer that goes to v through u is strictly better than the one we had before, then we can update the minimum and add v to the BFS queue. Meanwhile, we can keep count of the number of vertices with distance from a killer < K.
during the BFS and see that the min. distance of a killer that goes to v through u is strictly better than the one we had before, then we can update the minimum and add v to the BFS queue. Meanwhile, we can keep count of the number of vertices with distance from a killer < K.
This way, each vertex is added to the BFS queue O(K) times and each edge is checked O(K) times, so the total time taken is O((N + M)K + T).
P:
This is the first problem for centroid decomposition (therefore, it should be solvable with HLD, but the first idea I had was centroid decomposition). The idea and implementation are extremely similar to problem P.
After finding a centroid c, we can split the tree into its sons' subtrees and assign each query to the subtree in which its vertex vq is and add its value pq to the centroid if appropriate (apart from queries for which v = c, for which we just add pq to the centroid; adding it to the remaining vertices is handled in the following automatically). Then, we can recurse to the subtrees and only need to add pq from each query to all vertices that lie in a different son's subtree than that query's vq and have depth ≤ dq - dep(vq) = d'q. Of course, we should calculate depths dep() of all vertices in a tree rooted in c.
A good way to do this is with one BIT; depths only go from 0 to N, so there's no need for compression. We should put all queries into the BIT, then for each son's subtree, remove the queries in that subtree, check all vertices in it, add to each of them the sum of pq of queries in the BIT whose d'q is ≥ to the depth of that vertex — from this, we can see that we should be adding/subtracting pq at the index N - d'q for each query — and add the removed queries back to the BIT before continuing on to the next son's subtree.
This way, we only consider each query and each vertex in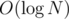 trees in the decomposition, and each time, we only need a constant number of BIT queries; also, the total size of constructed BITs is no more than the number of vertices, since it has size O(N) for a tree with N vertices — alternatively, we can work with a single BIT and remove all queries after processing the last son's subtree — so the time complexity is
trees in the decomposition, and each time, we only need a constant number of BIT queries; also, the total size of constructed BITs is no more than the number of vertices, since it has size O(N) for a tree with N vertices — alternatively, we can work with a single BIT and remove all queries after processing the last son's subtree — so the time complexity is 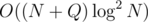 .
.
U:
The bruteforce solution to this problem would be: for each player v, check each player w who beat him, then check if v beat someone who beat w. If you can't find anyone for some w, then don't add 1 to the answer for v.
This runs in O(N3), but it can be optimised by a factor of around 30 using the fact that bitwise operations with integers are very fast. The right thing to do is coding all people beaten by u and all people who beat u for each u as 1-s in binary representations of integers — make an array B[][], where the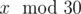 -th bit of B[u][x / 30] is 1 iff u beat x and another similar array Bi[][] for "x beat u". Then, checking if there's someone beaten by v who beat w becomes just checking if the bitwise OR of B[v][i] and Bi[w][i] is non-zero for some i, which takes around
-th bit of B[u][x / 30] is 1 iff u beat x and another similar array Bi[][] for "x beat u". Then, checking if there's someone beaten by v who beat w becomes just checking if the bitwise OR of B[v][i] and Bi[w][i] is non-zero for some i, which takes around 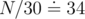 fast operations. With a time complexity of O(34N2), it's easy to get AC.
fast operations. With a time complexity of O(34N2), it's easy to get AC.
T:
So, we have the (reasonably obvious) DP that finds the probability Px, R[S][K] that, if we know that competitor x is in one of the minimum interesting intervals (I) and when we consider a subrange R of all people except x, then S will be before I and K inside I. We can compute Px, R'[][], where R' is R extended by one person, in O(N2) time as Px, R'[i][j] = aPx, R[i][j] + bPx, R[i][j - 1] + cPx, R[i - 1][j], where a, b, c are some constants that only depend on the person that's added and I. This way, an O(N4) way to enumerate P for all x and corresponding maximum R simply by adding N - 1 people consecutively for each x, but that's too slow. We need something better.
One might have an idea to use something like a segment tree, where we can merge ranges easily. In this case, it doesn't work — merging ranges with lengths L and 1 is easy by adding 3 terms per person, but merging ranges for L and M people takes adding 3M terms directly and at least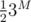 even when not counting duplicates. That won't work.
even when not counting duplicates. That won't work.
What we can do, however, is reverse the process of adding a person to R — from Px, R'[][], we can get Px, R[][] in O(N2). There are generally 3 ways to do this, but some of them can give NaN-s if some of a, b, c are zero — but since a + b + c = 1, all three won't fail at once. The formulas are quite lengthy to write here, you can find them in my code.
In addition, why are we even using ranges?! For what we want to describe, making some magic order for competitors is obsolete, so they should be sets! In other words, merging ranges is commutative.
Now, notice that Px, R[][] is just Px, R + x[][] — person x doesn't have a particularly special place. If we denote the full set of all N people by Rm, then we really just want to always remove x from P·, Rm[][] (if the second index is Rm, the array is the same for any x) to get Px, Rm - x[][]; that's N times an O(N2) process. After processing, we can add the appropriate numbers to the output array by adding Px, Rm - x[i][j] / (j + 1) to the probabilities that x will be at each place from i-th to i + j-th inclusive; that also works in O(N3) by brute force, but can be easily optimised to O(N2). And here we have an O(N4) algorithm by repeating this for each of the minimum intervals.
If only the precision wasn't so awful.
There are no trouble with calculating Px, R'[][] from Px, R[][] thanks to only multiplying and adding small numbers, but when doing the reverse, we use division by one of a, b, c, and they can get small (or 0) sometimes, which quickly nukes the code. The problem is that small precision errors may appear when dividing, but since we use previously computed values of Px, R[][] when computing new ones, those precision errors pile up, causing further precision errors and the values we compute progress exponentially to bullshit (probabilities of minus billion, for example).
The first trick to employ here is... well, not dividing by small numbers if that's so bad. Just pick the maximum of a, b, c or something and use the method that divides only by that; you can always pick a number ≥ 1 / 3 to divide with, which is pretty big. While it eliminates the errors very well, it doesn't have to eliminate them fully. So we should look for something more.
The second trick is even stupider, just check if there are people with strange-looking probabilities and do the bruteforce (O(N4) per person) on them. This does lead to AC, but you can't pick too many people to bruteforce, so you should pick the right people and if necessary, make your bruteforce constant-efficient (you don't need to compute N2 elements when merging two sets of size N and 1, just roughly N2 / 2). What I used was adding up all probabilities for everyone and bruteforcing the people for which that sum differs from 1 too much, but there are simpler things to try, like checking if you've computed some strange-looking probability.
Of course, this way doesn't guarantee running time better than O(N5), but it's a really fast O(N5) :D.
V:
We'll go down by bits. If the 59-th bit of l and r is the same, then the 59-th bits of all numbers in the range [l, r] will be the same and we don't need to do anything. If those bits are different, we can split the range [l, r] into two non-empty subranges such that one of them has numbers with 59-th bit equal to 0 and the other has it equal to 1, so we can find a number (any number from one range xor-ed with x) that has the 59-th bit equal to either 0 or 1. Based on whether we want the min. or max. ugly number, we pick the right subrange, discard the other one and continue on with the 58-th bit.
The important thing is that we'll always get a range of consecutive numbers for each value of the current bit thanks to starting with the largest bit, so we can continue in the same way for the 58-th bit etc., always cutting down the current range to a single number. We can find the final answer by xoring it with x again. Time complexity: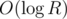 .
.
Speaking of xor, what's the point of using an operator and then defining it to mean xor? Wouldn't you save space by writing l ≤ (x xor a) ≤ r to being with?
X:
This is the second problem for centroid decomposition (therefore, it should be solvable with HLD, but the first idea I had was centroid decomposition). The idea and implementation are extremely similar to problem P.
The recursive part is done in the same way as in problem P, but since we want to sum up vertices at a distance of at most something from each query vertex and not query vertices at a "distance" of at least something from each tree vertex, we should reverse what we put into the tree (+-1 for each vertex at the index given by its depth) and what we ask for.
Also, we need to compress the distances, since they can get large. One prior use of STL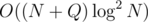 again.
again.
map<>is sufficient. Time complexity isCan someone explain P in detail, not getting what is being done after constructing centroid tree.