


I've checked today is not April 1st.
(source: 12 Days of OpenAI: Day 12 https://www.youtube.com/watch?v=SKBG1sqdyIU)
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 3985 |
| 2 | jiangly | 3814 |
| 3 | jqdai0815 | 3682 |
| 4 | Benq | 3529 |
| 5 | orzdevinwang | 3526 |
| 6 | ksun48 | 3517 |
| 7 | Radewoosh | 3410 |
| 8 | hos.lyric | 3399 |
| 9 | ecnerwala | 3392 |
| 9 | Um_nik | 3392 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 169 |
| 2 | maomao90 | 162 |
| 2 | Um_nik | 162 |
| 4 | atcoder_official | 161 |
| 5 | djm03178 | 158 |
| 6 | -is-this-fft- | 157 |
| 7 | adamant | 155 |
| 8 | awoo | 154 |
| 8 | Dominater069 | 154 |
| 10 | luogu_official | 150 |
I've checked today is not April 1st.
(source: 12 Days of OpenAI: Day 12 https://www.youtube.com/watch?v=SKBG1sqdyIU)






Merry Christmas!
thanks for guiding me to become red
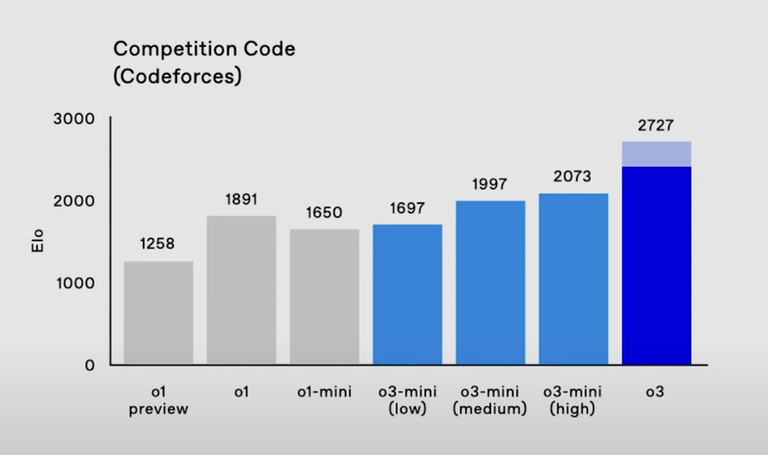
Anyone know why o1 is rated 1891 here? From https://openai.com/index/learning-to-reason-with-llms/ o1 preview and o1 are rated 1258 / 1673, respectively.
Benq do you think it's the end?
end for us mortal humans, not for gods...
At this rate, it will be over for these so-called gods soon. It is chess all over again.
1891 was o1-ioi I think
hm, o1-ioi is only 1807 in the link I shared though
it's probably o1 with high-compute like in the pro plan.
Possibly it's "o1 pro mode" or a finetune like o1-ioi or some other o1 model idk at this point because there's so many
in 5 years, there will be no way to pretend that the average human is worth more than a rock
I'll wait until it starts participating in live contests and having Red performance
dude even gpt1 was better than you
damn im cooked
Not possible...
I doubt that AI can do better math research than humans 5 years later.
That's the only thing you're gonna be able to do 5 years later — doubt.
Is this a prediction about humans now vs AIs in 5 years or AI + human in 5 years vs AIs in 5 years?
From the presentation we know, that o3 is significantly more expensive. o1-pro now takes ~3 minutes to answer to 1 query. based on the difference in price for o3, o3 is expected to be like 40-100?(more???) times slower. CF contest lasts at most 3 hours. How can o3 get to 2700 if it will spend all the time on solving problem A? It's very interesting to read the paper about o3, and specifically how do they measure its performance.
It must be parallelized. Surely there is something like MCTS involved
I will personally volunteer myself as the first human coder to participate in the inevitable human vs AI competitive programming match.
I only believe it if it was tested in a live contest
Maybe, codeforces should allow some accounts from OpenAI to participate unrated in the competitions? MikeMirzayanov what do you think?
o1-pro was tested in this contest live https://codeforces.me/contest/2040 and solved E,F (the blog has since been deleted)
It also couldn't solve B after multiple attempts, so keep that in mind as well (still, it's really impressive)
It feels comfortable until your last line
I mean, I can't deny it, these new AI models are really impressive for what is, in essence, a "which word is likely to come next" model. With that being said, and I'm paraphrasing from what I've heard others say since I'm nowhere at the level to solve those problems, F was a knowledge problem of Burnside's lemma with a bit of a twist.
I can't say for certain how these models will evolve; o3 got a super high score on ARC-AGI (a general reasoning task set), which could help its performance on problems like B. On the other hand, we have no idea if these results are embellished or how exactly they're calculating this, so only time will tell.
Dude, I feel big threat
If o3 really has deep understanding of competitive programming core principles I think it also means it can become a great problemsetting assistant. Of course it won't be able to make AGC-level problems but imagine having more frequent solid div.2 contests that would be great.
Is this a real life?
How do these things perform on marathon tasks? Psyho
Last visit: 2 months ago
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/
this paper covers it, tldr it outperforms top teams on hashcode because it can come out with really good scoring functions and that's the focus of the parent paper called funsearch https://www.nature.com/articles/s41586-023-06924-6
I don't see why people are paranoid about those insane ratings claimed by OpenAI. I guess they're worried about cheaters, but why? Competitive programming isn't only about Codeforces — it's a whole community. In every school and country, we know each other personally, we see each other solve problems live, and we compete against each other in onsite contests. So we know each other's level. When we see someone who we know isn't a strong competitive programmer suddenly ranking in the top 5 of a Codeforces contest, it doesn't mean much. We just feel sorry for them that they've started cheating. It will be more funny when we see a red coder who can't qualify for ICPC nationals from their university.
i think you're not seeing the bigger picture, the implications for the competitive programming are huge. 1) we might lose sponsors/sponsored contests because now contest performance isn't a signal for hiring or even skill? 2) let's not kid ourselves, but a lot of people are here just to grind out cp for a job / cv and that's totally fine. now they will be skewing the ratings for literally everyone. 3) from 2 it may follow that codeforces elo system completely breaks and we'll have no rating? the incentive to compete is completely gone which will further drive down the size of the active community there are many more, i bet you could even prompt chatgpt for them :D
we'll have no rating
And then we will have no cheaters. Happy ending
It will be more funny when we see a red coder who can't qualify for ICPC nationals from their university.
It's not funny, it happens quite often, for example, at our university(
Red was just an example, A more accurate example would be a team of newbies qualifying while a team of reds fails to do so. don't tell me it's still not funny
I think it has major implications for the whole world, not only competitve programming. For example, pace of mathematical research can easily double almost overnight (realistically over like a year period).
According to this article, it does not seem practical for the average user to run?
Quoting, "Granted, the high compute setting was exceedingly expensive — in the order of thousands of dollars per task, according to ARC-AGI co-creator Francois Chollet."
However, this is indeed a large step forward for AI.
;(
Do I still have a chance to reach LGM before AI?
OpenAI is lying. I bought 1 month of o1 and it is not nearly 1900 rating. It is as bad as me. I think they lie on purpose because they are burning a lot of money and they want people to buy their model.
Day by day I am getting mindfucked with these latest AI updates so much that I might lose my sanity.
I'm a bit skeptical. o1 is claimed to have a rating around 1800 and I've seen it fail on many div2Bs.
If I already have lower rating than o1-preview, why should I be concerned?
after we have rank Tourist for 4000 ratings, maybe we can have GPT for 4500 or so in the near future.
WYSI
Cheers
What does the light blue part on o3 mean here? Doesn't seem like the video explained it.
A lot more compute?
Amazing and unbelievable!
I recently subscribed to o1 (not the pro version) in the hope of clearing out some undesirable problems in BOJ mashups, and I got skeptical if this AI is even close to 1600. It can solve some known problems, which probably some Googling will also do. However, in general, the GPT still gets stuck in incorrect solutions very well and has trouble understanding why their solution is incorrect at all.
So, how did the GPT get a gold medal in IOI? Probably because it was able to submit many times. So, if I give them 10,000 counterexamples, it will eventually solve my problem. Maybe I could also get GPT to do 1600-level results if I gave them counterexamples all the time.
In other words, GPT generates solutions decently well, but it is bad at fact-checking. But fact-checking should be the easiest part of this game: You only need to write a stress test. Then why is this not provided on the GPT model? I assume that they are just not able to meet the computational requirements.
I don't think the results are fabricated at all (unlike Google, which I believe fabricates their results) and believe even at o1 model GPT can find a good spot, especially with the recent CF meta emphasizing "ad-hoc" problems which are easy to verify and find a pattern. But this is a void promise if it is impossible to replicate in consumer level. I wonder if o3 is any different.
You can write the code yourself to prompt it to stress-test. I think that shouldn't be part of the default model served to users, it would add too much computation, while 99% of the time during dev use cases users will just feed untestable snippets.
People have already submitted o1-mini solutions in contest and gotten 2200 performance multiple times.