


Can anyone Guide me how to optimize this relation 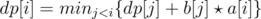 where b[j]>=b[j+1] and a[i]<=a[i+1] .I know for optimization use convex hull trick and i read convex hull trick ,but i don't know how to use this trick to optimize this Dp relation.
where b[j]>=b[j+1] and a[i]<=a[i+1] .I know for optimization use convex hull trick and i read convex hull trick ,but i don't know how to use this trick to optimize this Dp relation.
→ Pay attention
Before contest
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
09:29:29
Register now »
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
09:29:29
Register now »
*has extra registration
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 4 | atcoder_official | 161 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
→ Find user
→ Recent actions






Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Nov/23/2024 08:05:32 (k3).
Desktop version, switch to mobile version.
Supported by

Well initially start with an empty set of lines, then after you calculate dp(i) add the line Ax+B witb A=b(i) and B=dp(i). Then if at some point you want to calculate dp(i) then you just run a query with x=a(i). The b(j)<=b(j+1) allows adding lines without using a dynamic set and a(i)<=a(i+1) allows solving the problem using pointer walk on the set of lines instead of doing binary each time, thus reducing the running time to amortized O(1) per query.
Sorry for using () instead of [] im writing from a phone.