


Now the newest GPT have published its academic performance. Here is the picture.
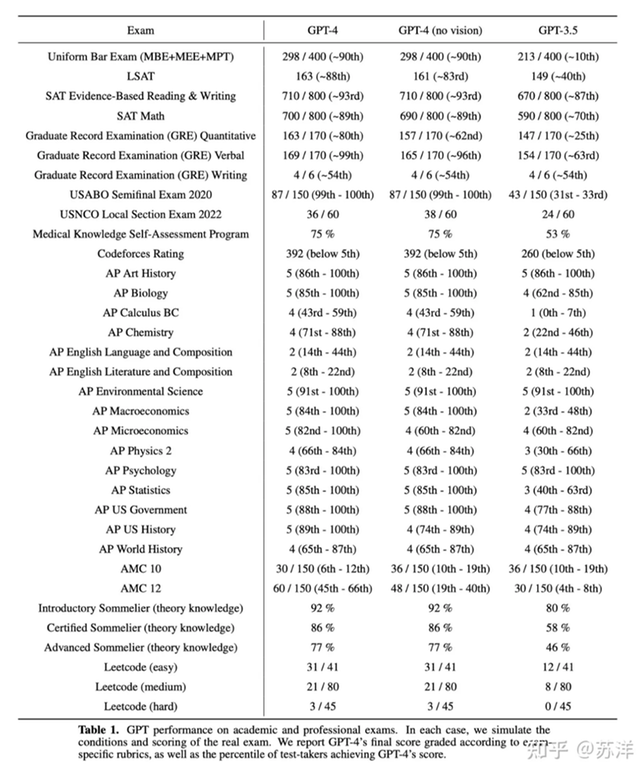
We can see from this picture that latest Chat-GPT have very outstanding performance at all kinds of exams GRE (beat me hard in GRE verbal), SAT, LSAT....
But for codeforces, original GPT only have a rating of 260, the GPT-4 is slightly better, with a rating of 392. Even a newbie can beat chatGPT-4 now (2023-03-14). Codeforces is the only one that GPT behave below 5%. Therefore, I am proud to say, competitive programming, like us codeforces, is one of the hardest obstacles chat-GPT will overcome.
The reason why I post this, is that many people, including me, worries that chat-GPT will destroy the competitive programming, like alphago destroy the go.
I am not saying it will not. However, think about it, why alphago vs Sedol lee or Jie Ke is most famous and shock the whole world? Because go is the hardest checkerboard game AI can beat, beat most famous go player means beat all checkerboard. We can also say, if AI beat tourist and rank No.1 in a contest, it means AI beat the whole education system, make all online exams and contests cheatable. Therefore, this contest will be shock the whole world again, end the old era and open the new era, and we contestants will all witness the history.






Okay the statistics show that ChatGPT is highly unsuccessful in algorithmic puzzles compared to others. For example, Leetcode(hard) only has a 7% success rate.
However, I wonder if we can simplify the problem statements ourselves. For example, we could clarify tricky problem statements to make it easier for ChatGPT to solve. Additionally, we could add our own observations to make the task more manageable for ChatGPT. So, I believe that the real success rate of ChatGPT could be higher than the results depicted on this table. But I am not an expert on this topic, it may be completely silly to think like that.
I agree with you that chatGPT can solve the problem easier with the help of human beings, like give it human beings observation, or make the problem statement easier. I see many posts that people train the chat-GPT to solve hard problem. It will surely increase the performance of chatGPT.
However, I don't think it will be meaningful. Because understanding what problem mean, and observing the problem, is also part of the competitive programming. It is called cheating if human being give chatGPT real guidance. The only guidance human can give to chatGPT is just the submission result, like WA, TLE, RE....
Running the code is considered non-human guidance as well.
You can ask ChatGPT to write a brute force solution to the problem, and you compare the generated solution with the brute force solution. It might even be possible for ChatGPT to fix the generated solution given the feedback.
I think it is even a good assistant for a competitive programmer to find out small test cases the programmer's code might fail.
It's also possible that GPT-4 has the right ideas and understands the problem statement but writes buggy code. I think AlphaCode generates many solutions and filters out ones that don't compile or fail sample tests. I don't know how OpenAI tested GPT-4 on CodeForces but maybe this could make it perform better.
we will be the last ones standing
Previous state of the art was (in my understanding) alphacode, which got way better results than rating of 392. The first model to reach ratings of 2000 or 3000 or 4000, will probably* be a model which is trained specifically to be good at competitive programming and not a general language model
*Just my guess
fair. but why would anyone waste their time developing a model specifically for CP, what is the end gain?
and to be honest, I think an AI model reaching 2000 is an overreach.
They already made a bot for CP once, and it did better than anyone (at least anyone I know) expected. I don't see any reason why people wouldn't still be interested in creating a CP bot.
And for the AI reaching 2000, I expect there to be AIs with 2000 rating in less than five years. I'm not sure if five years ago we had an AI that could write any not copy-pasted code, but my guess is that we didn't. Last year Alphacode got to 54th percentile and the capability improvements of other areas with large language models seem to still improve.
At what rating do you think we'll be in 5 years?
what bot?
Alphacode:
Quick blogpost: https://www.deepmind.com/blog/competitive-programming-with-alphacode
The paper: https://arxiv.org/abs/2203.07814
I'm not sure there is any even now. I'm not expert on topic but from my understanding all these models are using "copy-pasted" code that way or another.
I don't see a strong case to be made that the code they are producing is copy pasted. For example GitHub copilot can take into account the context of the file when suggesting code which makes it hard for it to just copy paste.
Then you have no clue how GitHub Copilot is working at all. It's proven fact that it was trained based on GitHub repos (and not always public ones) and it copy-paste chunks of code from them quite frequently.
I haven't heard about such issues with ChatGPT and AlphaCode, but I'm sure they are also trained using some codebase and don't write code from scratch.
I misspoke a bit. What I was trying to say is that they can produce "novel" code that is not copy-pasted.
I doubt that. It definitely could adapt code for particular context (change variable names etc), provide valuable suggestions or mix chunks of code it got during training (maybe that's why it's not that obvious that it's "copy-pasted"), but it's very unlikely that it could really produce something original.
What would be a kind of task / code it could solve / produce that would make you think that it isn't just copy-pasting?
Something which cannot be derived in a trivial way using training codebase. I understand that it's pretty hard to check without actual codebase :) So to provide you with more concrete metric: let's say that it should be able to solve non-trivial CP problem which solution is not available publicly on internet or at least you cannot find it easily using data provided to AI tool you're gonna use. Only that will give us at least some sort of guarantee that it wasn't direct or modified copy-paste of something existing before.
What do you mean by copy-pasting? A reasonable amount of codes in GitHub are not well-designed and anti-pattern that the AI cannot rely on and should be considered "noise".
The codes are end 2 end AI-generated.
The AI model is way more sophisticated than you think. It produces novel codes, whether you want to believe or not.
Reusing the code from a codebase directly or after modification/adapting for the context. In other words, writing the code without inventing it from scratch.
And still copy-pasted.
I believe in what I see. And I provided previous commenter with an metric to prove that AI can do something novel. Use that if you want to convince me. Otherwise, I don't see any reason to continue debates.
I believe our disagreement stems from the choice of words, particularly the term "copy-paste." Setting aside AI models for a moment, let's consider writing code in C++. When programmers use "int" or name a variable "tmp," are they copying from one another? Or are they simply utilizing existing knowledge? When someone develops a solution, it can't be considered wholly original, as it is a combination of pre-existing knowledge. At the same time, it's not accurate to label it as mere copying and pasting of existing code.
This is a response from Chat GPT:
As an AI language model, I do not directly copy and paste from existing code or text. Instead, I generate responses based on the patterns and knowledge I have learned during my training. My training data includes a vast amount of text from various sources, such as websites, books, and code repositories. This enables me to provide relevant and helpful information when answering questions or discussing topics.I respect your point of view, and even though we might think differently, it's cool to exchange ideas.
First case: they are using programming language basics, which everybody is familiar with. Second case: utilizing existing conventions in variable naming. Any of those aren't copy-paste because they don't require any idea and just are building blocks in the programs. But I understand your point and agree that there is quite thin line what should be labeled as copy-paste and what — shouldn't. In the current context I think it does make sense to stuck with something high-level, like solution to a problem in whole. So if AI can invent solution by itself — it definitely can "think", even if some pieces of code would be "part of existing knowledge". Otherwise, it just mimics what it saw in the training dataset and it's nothing else than sophisticated copy-paste. I hope that should be clear enough to polarize this discussion.
@gultai4ukr: I'm not expert on topic
But you sure are an expert on CF.
how is it a waste of time? A computer that can solve different kinds of problems on its own and with enough work, it might as well surpass humans in this domain too. Now imagine this becomes the norm. Every programmer would have a small pocket 'tourist' capable of optimizing their code near the max possible extent. It would revolutionize all software.
how often do you think programmers use any algorithms at their jobs? or write code that needs optimization from O(N^inf) to O(1)?
Just because you don't find it useful for your project doesn't mean others won't benefit from it. Apologies if my tone seems off, but I've heard this kind of comment way too often. You could have said the same thing to the folks who developed the gradient descent technique, and look where we are now – it's at the core of deep learning. So, let's keep an open mind, shall we?
Oh, no. The ML enthusiast has joined the chat.
I believe it's a matter of time. What ai is capable of doing currently is horrifying
What this shows, by the way, is that competitive programming (and similar activities like math olympiads) teaches young studs something beyond what is effectively tested by regular math/programming exams and software engineering interviews: a deeper level of thinking that is difficult to put to words and much more rare — leading to learning content that is also much sparser on the internet. Even with the expectation of considerable improvement in the future, this should be reassuring to anyone practicing this hobby regularly and a great incentive for the next generation to join in.
Or, you know, maybe the AI just gets confused why Alice receives so many arrays on her birthdays....
Apparently, because she still hasn't sent boobs to Bob. But it will be our human secret ;)
I wonder if the 3/45 Leetcode Hard attempts is one-shot or does it allow back-and-forth with the sample test cases like this.
My bet is that was without any guidance
I wonder why it does better in AMC 12 than AMC 10?
Although chat-gpt is not very good at solving algorithm competition problems, its translation function is very powerful. I often use it to translate English into Chinese. At the same time, it can also organize formats, such as automatically generating LaTeX format. I think it still has a great influence on me.
How did they find the rating of the bot? Did the researcher have ChatGpt participate in some virtuals? Also is there an ID for ChatGPT where we can see it's code.
AlphaGo did not destroy go in the same way stockfish didn't destroy chess... I love and enjoy it and it's even better when there's a superhuman engine on my phone to tell me where I went wrong. It's great to be proud that competitive programming remains unconquered, but it's not the end of the world if it is.
Maybe I’m wrong, but it’s hard to imagine a situation where a public AI model becomes stronger than the best competitive programmers but online programming contests don’t die out. The relevant differences between chess and Codeforces are that in chess, my understanding (as someone who doesn’t play chess…) is that (a) online chess platforms are pretty good at detecting blatant cheating, so only those who cheat in relatively subtle ways can go undetected, and (b) OTB tournaments are frequent enough to serve as the main form of serious competition, meaning that (1) players who consistently perform much better online than OTB may attract suspicion and (2) cheating online is not as problematic because OTB rating is considered the primary metric of skill.
Neither of these mitigating factors apply to CF. Even if we assume for the sake of argument that the hypothetical AI writes code that is watermarked in a way that can’t be removed through minor modifications, it seems reasonable to assume given the capability of ChatGPT to provide mostly reasonable explanations for the code it generates that an AI capable of solving any competitive programming problem will be able to explain the solution idea in words comparably well to an editorial (or, even if this is not the case at launch, it seems nearly certain that updated versions of the model will eventually develop this capability). This means that even in the best case, access to AI would give cheaters an advantage comparable to access to an editorial, which is clearly a game-breaking edge.
One might argue that cheating is a risk already given that it’s possible to discuss problems with others without being caught. However, this seems like a relatively minor concern at the Div. 1 level, since there are few people strong enough that it would be significantly advantageous to cheat off of them and those people have no incentive to share their code with others, meaning the only plausible form of cheating is people around the same level sharing solutions, which requires one of them to actually solve the problem first. Cheating using AI would be (a) much easier, since you don’t need to find other people to cheat with, and (b), much more significant, since immediate access to what is effectively an editorial would in my view be a far greater advantage than access to a solution only after someone else of a comparable skill level solves the problem. Perhaps I’m pessimistic, but I find it difficult to trust that if a quick and easy way to cheat for a 500+ rating point advantage existed, there wouldn’t be a sizable number of people (even among competitors who are skilled enough to implement solutions to 3000+ problems) who would abuse it. As such, AI strikes me as a practically existential threat to online competitive programming (if you disagree, please convince me I’m wrong—I’d love to be incorrect about this, since if I’m right it seems like we could have only a few years of Codeforces left…).
Moreover, if online contests lose their competitive integrity, competitive programming will lose much of its appeal as an activity, as in-person contests are not nearly frequent enough to serve as the primary metric of skill. I certainly would not have continued competing past high school if ICPC was the only “real” contest that existed; in fact, my primary goal over the last four years has been to improve my performance on Codeforces, with on-site contests as a secondary focus. All this is to say that when considering purely its effects on competitive programming, I’m not sure the rise of AI models stronger than any human competitor is something to celebrate.
AI strikes me as a practically existential threat to online competitive programming
I am never going to say "Technically correct, the best kind of correct" again.
You are right. Indeed currently wanting AI to be able to solve complex problems (I have nothing against it) would be profitable if people would make good use of it. Unfortunately there will always be those people who want to cheat for online competitions in order to increase their rankings or to pass certain qualifications. On the other hand, it could be useful if you want to understand something very quickly and you don't have the time and above all there are no people available to help you. It is a matter of using AI well. We'll see what will happen next...
I am pretty sure if AI becomes better than top competitive programmers CF dying out will be our last concern :)
I believe the MO/adhoc meta will save competitive programming from AI — I find it very hard to believe that AI (for at least the next decade or so) will be able to get a non-trivial score at the IMO (on completely unseen problems, i.e., without any test set leakage) even with rules naively stuck on top of natural language models as they are now. Non-trivial score as in not counting trivial problems like the ones AI has already solved: for instance, here.
Even if routine implementation problems and "optimize using a data structure" problems end up being solvable by AI, if you give it problems with non-trivial observations, I am confident that it's not possible for it to join the pieces together in a logical manner, at least at the current stages of AI development.
Sure, it can guide competitors towards some ideas that can be helpful — I'm not denying that. In my opinion, the usage of AI can only increase the lower bound by a benign amount (immeasurably small, for now). I would definitely like to see an AI that performs at the expert/candidate master level — that is when I think things would become interesting. The reason games like chess and Go are so thoroughly beaten by AI is in part the limited "branching factor" of their search space, which in the case of competitive programming or MO problem solving is too high (so high that it's theoretically undecidable) to be feasibly exploited systematically. Not saying that problem-solving is something that only humans are capable of, but instead claiming that understanding how problem-solving works is still an unsolved problem.
Until then, considering how the current state of the art in AI's performance in competitive programming is limited to either copy-pasting code from other sources (Copilot) or having a perfect score on training data and zero performance on test data (ChatGPT-4), I think there's still a long way to go before we find
Do you want to bet that a computer will not be able to solve any recent IMO problem (given the statement) before 2029? Any reasonable amount, or just on reputation?
It's not even about AI; the IMO is a bad benchmark except if you impose some no-calculator restriction. It's pretty likely that what you say can't be done in a decade can be done right now.
In a much earlier comment on CF, I've been of the view that it's not impossible to come up with something that automatically solves geo problems, and this opinion is not inconsistent with what I said above — because IMO geometry is "trivial" in the sense of being decidable (and once you know enough theorems it's quite mechanical and doesn't even need diagrams — speaking from experience).
What I said here was something non-trivial in the current AI context, like constructive combinatorics problems and so on, and not something mechanical.
Well, I think adhoc/constructive problems will be the first one to be conquered among CP problems if it happens. Think about how you approach such problems. A lot of cases, you try to solve many small cases, find pattern, and generalize it. This is exactly where machines outperform humans — they have a good sense on what "pattern" is (it is a mathematical model) and they have much better computing power to prove the hypothesis in small cases. I can imagine a machine struggling "find range inversion count query faster than n^2" but cheesing out some AGC D/Es.
Actually, the way of solving adhoc problems are also pretty machinery. Sometimes, you just take several patterns as a hypothesis, and brute force to see what is right and whatnot. Machines would do much faster.
On the other hand, I'm not sure if this is something that benefits greatly from the GPT revolution. Maybe this is more of a PL/formal verification stuff.
Indeed, when I said it is very hard for a language model, I was referring to how GPT stuff doesn't seem like it will help much.
In my previous comment I had linked the recent (not so recent by AI standards, though) paper by Meta that developed a theorem prover which could solve a few IMO problems. Their approach seems to be different from "looking at examples and trying to prove" and follows more of a mechanical approach by fitting concepts together like Lego blocks (essentially a search on a graph), and unless such "exploratory" analysis of problems can be automated, it feels like current approaches are missing out on something. AI theory is aware of this in some sense — they call it the exploration-exploitation tradeoff. This is why I think hard adhoc and constructive problems (those at the IMO 2/5 or AGC D/E level at the very least) are still a long way from being solved by AI. I won't call it learning unless it can come up with novel approaches like considering some seemingly unrelated idea that magically solves the problem and explain why the motivation behind the solution too. Until then, it's just matrix multiplication to me.
However, there are non-AI tools that automate such "guess and prove" ideas to some extent.
There also has been research on "learning" tasks at human speed by DeepMind (I recommend reading the paper, it's very cool), but it still does seem very far from being able to solve IMO problems.
Yeah, my claim is that the relative difficulty of adhoc problems should be much easier for machines rather than humans. This is essentially adhoc constructive problems solved by machines.
And I don't know why machines should provide motivation for their solution, do humans are able to provide them..?
I remember reading this paper when it came out, and they claimed that the algorithm is better in terms of the number of multiplications for a certain small step, and it reduces the constant factor in Strassen's algorithm accordingly. However, it doesn't make the time complexity better, or reason about the optimization itself — the tensor decomposition task was well-defined and the RL application here was just to find a set of steps that work correctly. In theory, this could have been done by other methods such as simulated annealing on some kind of sets of proof trees, but this paper was remarkable because they considered the decomposition task like a game, and then used game AI base knowledge to solve it.
Given enough computation resources, it can indeed help find more optimal solutions to a problem, just because it can do brute-force faster. However, this paper is not an example of solving "generic" problems. At the current stage of AI, we can definitely use machines for specialized tasks by applying human creativity to arrive at some general setups that solve certain kinds of problems (the Meta AI paper is also similar).
However, for being able to reliably solve an Anton problem, I believe AI in its current stage needs more work. One can argue that we can use the same kind of RL as used in that paper in the theorem-proving domain, but the difficulty for RL approaches increases rapidly with "allowed moves" and the state space size, both of which are very vast if you consider all adhoc problems.
Most of this discussion is hypothetical, though, and maybe I will turn out to be wrong (I would be glad, though, if I'm wrong and some cool AI comes up that can solve non-trivial adhoc problems — it'll definitely be an engineering marvel).
Regarding motivation for their solution: I think it's just a matter of preference. I would definitely want a correct proof for a problem, and it's an added bonus if the path to that solution is interpretable. This is more on the meta side of things, and the model is not really required to be able to reason about itself, but I feel that generalization (and not overfitting to examples) has to come with some inherent stuff. For example, a lot of RL approaches are interpretable, because we can look at the state space graph and the transition probabilities (and the values relevant to the Bellman DP equations at every step) and get an idea of why the exact steps that the AI took were chosen.
Yeah, I know that the paper didn't get even close to SOTA and stuffs, I think I can just say that ad hoc problems "tends to" (not all!) require small moves and space size, since they have short solution, and pattern matching are very helpful. Right?
I agree with that, heuristics can definitely reduce the search space a lot.
However, for a person who's new to problem-solving, there would be a ton of failed attempts, and the final solution will still be very short, and that too after a lot of cleaning up. For instance, in the proofs shown in the Meta AI paper, they noted that a lot of used tactics were redundant, and though the found proof was long but correct, the cleanup ended up with a solution that was very short. In this sense, slick proofs might not be very "searchable" and need more insight and wishful thinking to be able to reach.
I think one more fundamental issue with such things is that there are very few rigorous proofs for adhoc problems. This makes the task especially difficult because learning patterns is hard if you don't have some guidance. There's an obvious example that shows that giving appropriate guidance won't be so easy either. For example, greedy solutions — the solution description is simple but in editorials (which can potentially be used as training set), we rarely find proofs of correctness that can be analyzed by some NLP and restructured into a rigorous proof that the AI can be given as a learning input. Humans reason very approximately, then rigorize their solution, and if it doesn't work rigorously, they try to amend it. One way of making AI learn with just human inputs is to try to account for this process, but it's unnecessarily complex.
I've thought about trying to come up with such an automated problem-solving setup multiple times, but the effort seems to be very disproportionate compared to the perceived results. I think the current training set (of editorials and so on) would be more usable if there was a tool that could convert proofs into formal proofs (in Lean or something) and then Lean checks if they're correct. Then the AI (theorem prover) can use those Lean proofs to learn, and the resulting Lean proof can be summarized by another tool into a human readable format.
Surprised that no one has mentioned it yet(perhaps it's not so popular).
There's an initiative going on for awhile called the IMO Grand Challenge, where a bunch of smart people(including Reid Barton, one of the top CPers who used to compete in the TCO days) have come together to develop an AI whose ultimate goal is to compete side by side with humans and win a gold medal.
If this turns out to be successful, most likely CP would be no more, atleast not as we know it today. :(
My personal view is that we're a long way from this turning to reality(the IMO challenge has been going for 4 years-ish now). I hope it doesn't, I want to enjoy CP with my fellow competitors.
This challenge is probably the reason why IMO gets a mention in the linked Meta AI paper, which is why I didn't link to it. One of the USPs of that paper was that it "solved 10 IMO problems, 5x more than others."
Well... maybe every contest becomes implementationforces then
AI can solve all geometry problems by coordinate bashing.
I believe that even if you can't solve any problem in the contest, you can get the rating of this.
Only solve one problem in Div. 3 round? I think gpt4's performance is better when it solves leetcode problem.
I tested ChatGPT 3.5 and got better ranking during 3 contests (737), check my profile. I think those results are pessimistic. I'll keep experimenting with GPT-4 in the next contests...
you need to participate in at least 6 contests to know your real rating.
I saw that you only managed to do the first two problems from the last div. 4 round. When I tried this (also with ChatGPT 3.5), it managed to solve D as well on the first try (maybe because I specifically requested a solution in Python?). It also managed to solve G1 when I told it to use sorting, and (almost) solve E when I told it to use DP.
That's interesting. I retried now on Problem D, but didn't manage to get the right solution in Python, did you copy also the example testcases? It seems the GPT output is highly dependant on the input string & whether we give hints or not, but I didn't give any hint to GPT..
It could also be that I was mixing the use of GPT playground (which I believe based on GPT 3) when the GPT 3.5 becomes inaccessible due to load issue.
I asked
and copied the entire problem statement, including the examples.
Update: I got now as well the right solution for Problem D, after explicitly asking GPT to optimize the code for speed.
https://codeforces.me/contest/1791/submission/197627585
I don't think LLMs will ever beat humans because they learn from human-written content, which is extremely scarce and difficult for AI to understand at this point for all advanced CP stuff. However another form of AI almost certainly will beat us at some point. But by then AI will have taken over almost all informational aspects of life.
I can sense "Therefore, I am proud to say, competitive programming, like us codeforces, is the hard obstacle chat-GPT will overcome" aging badly.
Imagine that using chatGPT to solve 2A/2B and save a minute
It's faster to solve them on your own anyway
One minute is not worth a risk to get 50 points penalty :)
How about using GPT to generate CP problems (with solution)
Interesting idea, but obvious downside is that everybody will be able to solve it using GPT
I actually tried that with 3.5 (ChatGPT). It was unable to generate any original problem and mostly just standard problems. Therefore it couldn't generate good problems. Which makes sense because it was trained to predict what words come next in already existing texts.
While it surely could come up with a completely new problem, it is quite unlikely as most of chat GPTs responses seem kind of standard.
Edit 2: Just did 10 requests to generate a problem. Here is the outcome:
Honestly, even though most problems are standard, a few of them are interesting. (P10 even appeared in CF round recently.)
I wrote an essay on why text prediction is not just memorization; practically everyone on ML Twitter agrees with the sentiment.
Let me clarify. I never said that ChatGPT is just memorizing. Instead, it is observing patterns in language, like relationships between tokens and such. With that, it is able to generate text. However, it doesn't have the knowledge of the meaning behind the words.
I said that it cannot generate original problems based on my experience with it. It definitely could generate a totally new problem, but most of the time it will just come up with something well known or NP hard. And that is kind of what you would expect from a text predictor.
I will make an edit to the previous comment to clear it up.
ChatGPT is much more sophisticated than that, and is capable of generating full paragraphs that are coherent and meaningful.
From a philosophical perspective, ChatGPT does not engage in true creation, as it is simply discovering patterns from existing knowledge. This is similar to how a mathematician finds a solution to a specific problem, or how a poet writes a poem, or an artist paints an artwork — they are not truly creating something from nothing, but rather drawing upon existing knowledge and patterns. Even Einstein's rules of gravity were not created by him, but rather discovered as existing patterns in the universe.
Pretty sure that my reply to the previous comment elaborates what I mean.
it shows that cp will be the last one standing on the world:)!!!
It's better to fund 1 Bill to codeforces , see Microsoft.
I think chatGPT will remain newbie for a long time.
AI is hard to understand the problem, and it need to think an algorithm to solve it, and write code like ourselves.
Yes, computers may KNOW all the algorithms, but AI isn't able to USE them like real person, so it will be hard to find the solution.
Am I the only one interpreting this as possibly 1292 instead? Since the new ratings abstract the absolute rating and 392 after the first contest is equivalent to 1400 + (392-500) = 1292.
Then it would not be possible for ChatGPT-3 to have a rating of 260, because it's impossible to get a -240 delta in the first contest.
Neat observation! I didn't think of that
Writing the prompt correctly may make GPT solve Harder Questions too
How would you know, you cannot solve hard questions
Competitive programmers shouldn't worry about ChatGPT, as this tool only looks like a very intelligent text-based search engine, not a real artificial intelligence (based on defs). He only knows the answers to the questions he has seen and cannot create something new by combining things (not complex ones). In other words, it has no creativity and definitely cannot solve the new algorithmic questions that are proposed in each contest! People like to make unrealistic stories about artificial intelligence, but the truth is that humans still don't reached artificial intelligence in the sense that it has in people's minds (and of course its technical meaning, and these are all attempts to find a way towards it).
But anyway, if you look at it from another point of view, it is just like a human child, it's like it's been a kid for years and that's why he looks smarter than other kids! I see a future when this child grows up!
Time to test chat gpt on JEE Advanced