


I am not any expert in competitive programming, so this post is not about teaching you fellow coders any new things that you already don't know. Rather I am asking you high rated Div. 1 people to share your experience, problem solving approach of using STL(vector, pair, queue, priority queue, stack, set, map, algorithm) for good understanding of when and where to use STL.
I have already read the various STL tutorials on Topcoder(by DmitryKorolev): STL Tutorial 1 STL Tutorial 2
Codeforces: DFS using STL by evandrix
But after reading these I found out that they are just meant for giving you some basic understanding of "What is STL and its importance". These were very informative, but not so much helpful for contest programming as they didn't gave any practical idea or insight of in which cases a programmer should go for which STL.
I have very little experience of contest participation but in this short duration I went through codes of various people to learn their way of coding. There I found out that there is a powerful feature of the Standard Template Library (STL) – a great tool that, sometimes, can save you a lot of time in an algorithm competition. I learned that some people often have very short solutions by using the STL. Due to this they are able to write and submit their codes very fast. e.g.
vjudge3's pair usage for 297C - Splitting the Uniqueness
Mr.'s map, pair usage for 402B - Trees in a Row
Rebryk's queue usage for 371B - Fox Dividing Cheese
while for the same problem 404C - Restore Graph ig_dug's vector, pair and kaushik90's easy vectors
Above all I found that I was always relying on using arrays and due to this it was very difficult for me to handle the data and consequently I was not able to implement my approach. One more problem I felt later that I was confused for Which STL should I select for a given problem scenario. It happened at times that I needed pair but I was using two separate vectors.
So in the end I am requesting and inviting codeforces community to share their experiences of effective usage of STL for fast and short code writing. It would be very much benefiting if in your replies you explain your way of thinking in the perspective of using STL, Please explain how do you choose the appropriate STL(as in my case of confusion of selecting pair or 2 vectors) in the contest problem theory. If you want then you can cover all the STLs or you cover just one STL feature, but cover it with good explanation, examples and in detail.
This will really help the new learners.
Thanks. Happy solving.







STL gives you a chance to use advanced data structures and algorithms when you don't even know how to use C++ (as it was with me). You can also use simple algorithms like find(), lower_bound(), binary_search() to code faster (but usually it's easier to write several "for"s anyway).
How many different values in array A if 1 <= A[i] <= 10^6 , 1 <= n <= 10^5?Just push it in set<>, size is the answer! You don't need to iterate over it withexist[A[i]] = 1, i = 1..n and count += exist[i], i = 1..1000*1000.Why is it better? Because in case1 <= a[i] <= 10^18set<> works fine too. Even ifA[i] is a string, you simply need to calculate the hash values, and use the same approach. IfA[i] is the point (i,j) in table NxMyou can use valuesi*M + jto USE THE SAME APPROACH)) Of course, it's possible to solve this problems in different way, without set<> at all, and with much better complexity than NlogN, but it's a question of your targets)) So, I meant that it's better to try STL in different applications to simplify your code and reduce it's size, but you souldn't try to use it for "prefect code" or super short implementations of dfs or smth else. It smells like an attempt to create universal template for all problems)Please, it's the C++ standard library you're talking about, not the STL
Thanks for pointing out, I've changed the title of this post as "C++ STL".
Now that's even more confusing... but whatever
Whatever! lets not go into the nomenclature. Lets focus on the improving our problem solving skills. If we learn C++ standard libraries for this goal then this is the real purpose of this post... :)
Sure, see my other comment below for a more constructive constribution ;)
C++ standart library, not STL.
Here is an example where I abuse the C++ standard library in a really cruesome way to implement the fully dynamic variant of the convex hull trick to maintain the upper hull of a collection of linear functions.
Note how I have a
multiset<Line>that maintains the set of lines, ordered by slope. Now I had the problem that to search the matching line for a given X coordinate ineval, I need to binary search on the intersection points of adjacent lines. Unfortunatelymultisethas no option to let me customize the binary search, so I give every line astd::function<const Line*()>, so that it can look up it's successor while comparing. Then I abuselower_boundto do the binary search, using a special query line.Line::operator<contains a hack so that it behaves differently when comparing against such a special query line.This is nasty, but it's short, fast enough and gets the job done, which is all that matters for me
Actually, you could get much shorter code if your structure were to inherit from
multiset<Line>:) Then instead of e.g.begin(lines)you havebegin(), instead oflines.insert(...)you have justinsert(...), and you can useiteratoras a type (instead of thetypedef-edIt). You also haveempty()automatically :)Otherwise it's a neat implementation, I like it. Although instead of
succI prefer to have adouble xLeftwhich is the x-coordinate of the intersection with the previous line in the set. It is easy to binary-search on ineval.@dj3500 Good observation about the inheritance. I guess having
xLeftinstead ofsuccavoids a lot of the ugly hackiness here, not sure why I didn't think of that. I guess I didn't think it was easy to maintain, but it seems to be.Yes, it is sufficient to compute it for
yandnext(y)at the end ofinsert.I thought that
succwas considered your technical/C++11-features tour-de-force here, not ugly hacking :PNo I would never dare to do something like this if it was avoidable at a reasonable cost :P It's interesting that it's possible, but it's not anywhere near elegant or clean
Ahh now I remember. The problem was that I wanted to represent the intersection implicitly using two lines, rather than expressing it as an imprecise floating point value. Still I could just have a
mutable Line* predecessorproperty instead of thestd::function, which should be a bit simpler. And simple is always better :)Yes, I see. But the doubles are not that bad. For example, I recently solved a problem with this structure where I needed to use long doubles anyway (instead of long longs) in the final line of
badto get accepted.Yes, I had the same problem in the CodeChef challenge that I used this for. I guess I would need to get incredibly unlucky for this to shoot me in the foot, but if there is a choice, I'd rather be safe than sorry :)
That was brilliant @niklasb , I can understand the algorithm for Dynamic variant of the trick, but i have never seen such usage of STL.
I have a few doubts regarding C++ usage (I am only asking because i could not find much on google). 1. How does this work in language** auto y = insert({ m, b });** line 25 2. what is the name or the idea behind , this mutable function<const Line*()> succ; in Line 4 ? 3. How does the ** bool operator<(const Line& rhs) const** work ?
These questions might sound really dumb,but i just need a stack-overflow link to the name of these ideas i will learn them myself..
(1) is just just the
autokeyword from C++11 together with an initializer list as the constructor argument forstd::pair. (2) is a usage of the classstd::functionintroduced by the C++11 standard. It's a hack because I need an iterator to the element successor in the comparator (3) is just a standard operator overload, with the trick that it behaves differently when comparing a line and a query and when comparing a line to another lineAfter some time with the code I think it has a problem. When a new line is inserted, the function succ must be updated for the new line after all the erases. Also, the succ of the new line's previous should be updated as well.
my suggestion for fixing this issue:
Do you have a test case where the version without your fix gives the wrong answer?
Yes, I found the problem while solving 91E - Иглу-небоскреб (I've built a segment tree of CHT's). When I relied on the original code the first input example wasn't correct. This is the WA solution 59667839. This is the submission with my fix that got Accepted 59662177. These solutions are identical except the changes in the "insertLine" function. (The code is a bit different for the purpose of the question)
Thank you very much, but as mentioned above this implementation has some issues and bugs. For those wondering, here is the better version of Convex Hull Trick online.
I also use
map<vector>in 404C- Restore Graph problem to make much simpler implementation : 6083798one suggestion. rather than using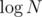 , and the rest of the code can remain exactly the same.
, and the rest of the code can remain exactly the same.
map<int,vi> pathu can usevi path[MAX]. this will reduce ur time complexity by a factor ofPS: note that this will not work if u want to access large indices like
path[1<<30]. in that case u will have to usemaponly.I see. Since the problem only in range 10^5 using array is more efficient right?
I didnt notice this while implementing. Thank you
As long as you have enough memory it will be a lot of more efficient.