


Всем привет!
Сегодня в 19:30 по Московскому времени состоится раунд Codeforces #238. Контест пройдёт в обоих дивизиях.
Раунд был подготовлен мной и cfk. Это мой 4-ый раунд и 2-ой раунд Кришьяниса. В этот раз, по-моему, задачи весьма необычные и, может, даже неожиданные. Мы уверены, что любой участник(ца) найдёт себе задачу по вкусу! Но нужно её найти. (:
Как всегда, спасибо Михаилу Мирзаянову (MikeMirzayanov) за проект Codeforces и систему Polygon, и Марии Беловой (Delinur) за перевод условий. Большое спасибо Геральду Агапову (Gerald) за помощь в подготовке контеста. Мне и Геральду повезло обсудить задачи очно во время зимних Петрозаводских сборов, что, по-моему, оказалось очень полезно.
Мы желаем вам захватывающего раунда!
UPD1: Распределение баллов:
DivI: 500 1000 2000 2000 2500
DivII: 500 1000 1500 2000 3000
Баллы выставлены относительно, чтобы стоимость каждой задачи делилась на 500, и была бы ближе к объективной оценке. Не пугайтесь, на самом деле задачи не настолько сложные. (:
UPD2: Поздравляем победителей!
DivI:
DivII:
UPD3: Замечательная статистика раунда от DmitriyH.
UPD4: Разбор опубликован здесь.







"Problems will be unusual and surprising". Hmmm... Sounds interesting. Good luck to everybody...!!!
haha,friend,You are very speedy.
haha,friend,You are very smarty -_-
Пора домой в желтые.
UPD Договорился ;(
Надо будет зайти в гости)
Подожди меня, нам по пути.
Пацан сказал — пацан сделал.
Не говори гоп, пока не перепрыгнешь.
Я бы не был так уверен — может и не хватить) Посмотри последний матч KuroNeko, к примеру.
First Contest in Iran's New year and unusuall problems!! Great!!
Every contest anybody has new year and should write about it. It's sooo interesting for us!
No, hardly every contest. Count contests per year and think: could there really be so many existing calendars?
On this round I wish all high ranking.
what about other rounds you still wish same thing
Not to mention his "wish" is impossible because everyone can't get high ranking. Unless almost nobody solves anything.
or all solve problems with same final score with probability
0.0000000000000000000000000000000000000000000001
Please don't in those little details
wish all participants a very happy Match ^_^
This round will be even unusual and surprising for me, if my solution of Problem-C gets AC and fails system test of Problem-A :)
Since you know that, so it won't be surprising ;)
Ёмкий набор тегов: codeforces, раунд, фармить вклад
Ночь, ледяная рябь канала,
Аптека, улица, фонарь.
Hi all, wanted to ask a simple query. How to find name of blogs in a tabled manner, In the right panel titled "Recent Actions", If I click on detailed, I can see comments of people over different blogs, But I dont want that. I want to see more number of blogs similar to ones shown in that panel itself. Eg. I would like to see around 30 entry per page for Recent actions, Is the any such option available somewhere on codeforces?
My first D1 round. So exited :O #mlc
E is 3000 seems that opening it during contest time is useless :D
Loving the pretty pictures.
Thanks for the contest I really really enjoyed C in DIV2 ;-) It's amazing problem !!!
I was going into BIT ideas, Then I thought that why is GF(2) given, find solution was really cute =D
Div1-A/Div2-C, aka "how to solve a problem while ignoring over half of the input". Pretty nice :P
Авторами подразумевалось, что Div2(C) в TL влезает с асимптотикой O(n^2 + nq)? С такой асимптотикой решение, которое я пытался взломать, приблизительно 0.75 секунд работает.
Чисто за n2 + nq не подразумевалось. За (n2 + nq) / 32 — может быть. То решение прошло тесты?
Нет, не прошло. Я торопился, и составил тест из 10^6 запросов на инвертирование одной и той же строки. Скорее всего, оно хорошо кешировалось и из-за этого залезло в TL, с инвертированием столбца было бы иначе.
Ясно. Народ, а кто-нибудь сдал какое-нибудь решение с битсетами?
А такое решение вообще есть?)
У меня есть только искусственное, которое проходит во время. По сути там я каждый запрос умножаю строку на столбик с помощью битсетов, но это произведение умножается на 2 и пропадает (это сложно не заметить во время контеста и убрать).
Awesome problems. I really enjoyed solving C and D. Thanks for the contest.
Haha, I spent most of time on problem C and didn't solve it. :( Good contest though.
Ok, i just solved it.
Very nice problemset, I found my problem! It was Div1 C :)
Nice contest, the pretty complicated at first Div1 A turned out to be awsome. What was the main idea behind D? I used a stack and LCA, but got WA. I imagined that the stack part was wrong, but couldn't find any counterexample after looking for it 10 minutes. Do you have one? (I would like to add that the stack used line intesections, not just simple comparisons)
Stack works when you can't see a hill again after removing it, which doesn't work in this case.
The LCA is correct (that's pretty easy to see). To find the next hill a climber goes to from hill i, you add the points from right to left, remember the top convex hull (well, it's actually a concave curve, but it uses the same idea as convex hull algorithm) of these points, update it when adding points and always pick the leftmost point in the hull so far (after the just added point, from which the climbers go to the next point of the hull). This can be done using vector cross product — as long as the leftmost 2 points of the hull (if they exist) are placed in such a way that the leftmost one is below the line from the just being added point to the one to its right, you remove the leftmost point of the hull — because it won't be in the top convex curve ever again. It works the same way as the standard convex hull algorithm.
Another contest where D appears simpler than C. At least to those who are used to more algorithmic problems — like me :D. Too bad I missed the start of the contest (thanks to the modern world's stupid shopping obsession), I think I could've done well.
Thanks a lot for the pointers, In order to understand why my stack is not right, do you have a small handly counterexemple? thanks.
Edit: I tried to build a counterexample like this:
On an exemple like this, my stack alg runs as follows:
And now we have our tree, on which we apply a LCA algorithm.
Depends on the exact approach. Just be satisfied with the general guideline that stack is useful if you're sure that you can't use a discarded element again. In this case, it fails because heights of hills can vary greatly — you can discard and use again any hill many times.
If you want a good counterexample, you can always look for it yourself — try the case that gives WA; if it's too large, try generating your own and comparing against AC solutions, etc etc.
I edited my approach ^, I also corrected a few small mistakes and got ACC. Please note that my stack pop criterion is geometry heavy, something like
No need to try to understand the formulas, all I did was to check if a segment intersects another.
It could quite possibly be the same thing I was talking about. (Convex hull can as well be implemented with stack.) I just expect an algorithm that's called just "stack" to have storing the hills on a stack to be the most complex idea in it :D
My best performance in cf ever(Div2 5th place wink). Thanks a lot for the mathy contest :D
And I am probably going to fall at my lowest rating in the last 2 years or so. Last two contests have been miserable for me. Making a lot of silly mistakes, I dont know what has happened. :( T_T . But both of these contest had very exciting problems.
Почему 6106684 ловит TL на претестах?
ios_base::sync_with_stdio(0); есть, и входные/выходные данные не double.
Вывод по одному символу. Такие решения у нас работали по 4 секунды.
А почему так?
Действительно, если поменять на
то АС за 0.218 — 6117108
Я даже не знаю, если честно... Призываются мастеры С++.
удалил
Дело в том, что при попытке ввода, неявно вызывается cout.flush(). Это связанно с тем, что в консоли перед тем, как запросить кокой-либо ввод от пользователя, необходимо показать ему последний вывод, а значит отчистить буфер. Решается это строкой: cin.tie(nullptr);
Спасибо, 6117776 — заработало.
Если эту строку банально дописать в свой шаблон — это может где-то вылезть боком, за исключением интерактивных задач?
Не, эта строка всего-лишь "отвязывает" cin от cout. Просто не будет cout.flush(); вызываться, не более.
Да ладно?
Я имею ввиду, с командой
ios_base::sync_with_stdio(0), а неscanf/printf.Имеется в виду использование cout
Я, конечно, еще вчера писал на паскале, но, кажется, printf != cout.
Nice contest! Interesting and solvable problem :)
Объясните, пожалуйста, популярно, почему каждый флип меняет парность ответа?
раскрой скобки в выражении
там получится что ответом является сумма произведений диагональных элементов
аааа, тьфууу.. вот дурак.. Заметил, что каждый два раза, но протупил выбрасывть их.. спасибо
А если точнее, то просто сумма диагональных элементов. А каждый флип просто инкрементит ответ.
Как искать в задаче Div1-D для конкретной горы a нужную нам(правую) гору b
Изначально скажем, что этот "предок" — первая справа гора, если такая вообще есть.
Далее будем делать итеративный "подъем" — если наш предок не закрывает видимость на своего предка, то делаем нашим предком предка нашего предка. Иначе останавливаемся. Фактически в задаче от нас требуют выпуклую оболочку — и этот алгоритм проще понять, представив его, как построение выпуклой оболочки.
Понятно, что каждая новая вершина добавит в выпуклую оболочку не более одного ребра, и каждое ребро мы из оболочки выбросим не более одного раза, поэтому сложность такого построения графа — O(N).
I got TLE in Div1 A on pretest 7. I had used cin cout with ios::sync_with_stdio(false). Until now I used to think that this method is faster than scanf printf. But when I changed this to scanf printf , the code was accepted. What is the reason for this?
cin/cout does usually works longer than printf/scanf...
use read/write instead!
Each operation on
cinflushescoutby default. Usecin.tie(NULL);to prevent this.Are
#define endl '\n'andios :: sync_with_stdio(false)enough?Together with
cin.tie(NULL);this is probably about all you can do to speed up iostreams.Also with
std::strings it helps to.reserve()the maximum number of characters before inputting a string, and to reuse the same string object if possible:Not just with strings. If you have a
vector<>which you construct by adding elements (my implementation of interval trees, for instance),.reserve()can cut down on time and memory nicely.Note a line in my template:
#define dibs reserve:DПрошу администрацию обратить внимание на взломы (их не много), там есть пара очень подозрительных...
Чем же подозрительных?
Да, знаем. :)
есть решение с заведомо неверным ответом на тест 1 20(которое взломали), аккаунт зареган 11 часов назад
Very nice problem :) it's really surprising !
-.- but I late to realize that
А можно еще попросить, объяснить, почему мое решение на А упало? не понимаю :(
Thanks to authors for illustrations! Very helpful!
Great Round ! too bad my C couldn't make it through the system tests :D, I realized after that it had a very simpler solution than i thought
Как раскрыть скобки в задаче С? а то у меня не получается получить формулу.
Там нет формулы. Просто если увидеть, что каждое произведение по сути встречается дважды
В итоге получается сумма произведений диагональных элементов, что в свою очередь является просто суммой диагональных элементов. Произведения всех остальных пар производятся дважды и дают в результате либо 0, либо (2 * 1) % 2 = 0, стало быть, их можно не учитывать вовсе.
Очевидно [прямо из условия следует], что ответом на задачу будет
По свойству следа матрицы получаем:
UPD: Пояснение здесь
А что за свойство следа такое? Имеется в виду только по модулю 2?
Если кого запутал, я ненарочно.
Виноват.
Пояснение здесь
матрица a размера n*n
скобки
(a(1,1)*a(1,1)+a(1,2)*a(2,1)+...a(1,n)*a(n,1))+(a(1,2)*a(2,1)+a(2,2)*a(2,2)+...a(2,n)*a(n,2))+ ...
(a(n,1)*a(1,n)+a(n,2)*a(2,n)+...a(n,n)*a(n,n))
скобки по строкам — отбрасываем(они не влияют)
получаем ситуацию, когда каждая пара произведений (кроме a(i,i)*a(i,i)) встречается по два раза их сумма всегда ноль(1+1=0б 0+0=0) остаются пары: a(1,1)*a(1,1)+a(2,2)*a(2,2)+...+a(n,n)*a(n,n)=a(1,1)+a(2,2)+a(3,3)
Ну а каждое изменение матрицы меняет только одни диагональный элемент. всё
По сути, нам нужно посчитать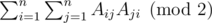 . Сразу можно видеть повторения. :)
. Сразу можно видеть повторения. :)
То, что претесты проходит решение, в котором if (n%2==1)res=1-res; (т.е., работающее только для нечетных n) — это хитрая задумка, чтобы было пространство для взломов, или же случайно так получилось?)
Упс... XD
Illustrations were so helpful.
Хороший контест для неосиляторов сложных задач, вроде меня. Спасибо автору за этот раунд, и за контест в ПТЗ.
Спасибо... :) Рад, что наш контест в ПТЗ понравился.
Зачем вообще такие неразумные ограничения в div2 C/div1 A ??? Вся фишка в том, что переключение с ввода на вывод работает слишком долго??? Но это же глупо ловить решения на таком проколе.... И еще я вообще не понял, почему, в общем-то правильные решения мои решения, отосланные во время контеста на Delhi, сыпались по RE на 3 тесте — там вообще пустая выдача, а они же, но на FPC, доходили до 7 теста, где получали TL. И все это устаканилось только после того, как выдачу сделал одну — в самом конце.
Чтобы запретить оптимизированные решения за n2 + nq, в общем.
Зачем тебе вообще закрывать output при вводе/выводе не из файла? Первый раз слышу
не вижу вашего сабмита на ОК
UPD. аа все, пардон
when will the ratings be updated?
Rating updated just now. +26 :p
удалил.
стало можна просматривать чужой код уже.
решение 6116164 меня устроило :)
P.S. очень красивое решение, кстати
Why the Codeforces Judge Doesnot Give Runtime Error in Situation When Size of array is Smaller than that Required... Rather It gives WRONG ANSWER. In some Judges like spoj WE get RUNTIME ERROR. Got WA on test7 PROBLEM C DIV 2 due to shorter array size,I concentrated on other Bugs rather than Array size which i missed ... so Discouraging
global array overflow will not lead to runtime error(if only a little), but local one does. overflowed parts may not be initialized correctly.
UPD overflowed 2-dimensional array will get wrong answer. See the implementation of 2d arrays: the i+1-th row is placed right after the i-th row. So if you write overflow data in i-th row the result is the data in i+1-th row is modified.
When you do something wrong in C++, you don't get a runtime error. You get undefined behavior, and today you saw one of the many ways how it can behave.
When the editorial posted then?
The editorial will be posted tomorrow, we are working on it!
Thanks. I'm waiting for it
please can any one tell me why the judgement verdict "SKIPPED" is shown ........??
Maybe you have copied the solution or commented about the solution outside
Thx for contest, I am very happy for my participation, in final I got +163 ratig points) thx a lot
чем то эти две посылки очень похожи, или мне кажется? 6115340 6116302
Can someone please help me by pointing out why 6118389 solution fails but 6118249 passes ? (Only difference is the part commented out in the AC solution)
The code that has been commented out should have no effect on the final solution, since
(X +- (2*Y))%2is same asX%2.EDIT : Will not work in if 2*Y > X.
I had a similar solution which failed on case 50. Weirdly, converting everything to long long got AC.
Still WA. there shouldnt be a problem for long long in any case. The maximum value would be
1000*1000Я один такой неудачник, кого разлогинивало каждые 5 минут?
Не скажу чтобы сильно мешало — всего раз 4-5 за час контеста логиниться пришлось — но любопытно, на чьей стороне такая фича :-o
Аналогично
меня не только выбрасывало но и язык на английский меняло
If the result of the judging is Compilation Error, Denial of judgement (or similar) or if the solution didn't pass the first pretest, then this solution won't be considered in calculating results. I take this rule from here
Now I ask If this is the only solution I submit it wrong and get wrong answer in the first pretest so it won't be considered in calculating so it doesn't considered as a try so system has to deal with me as out of contest at this moment like the case of you didn't submit anything. Now,
why my rate change ?
I think this rule only means that there are no penalties for a compilation error or failed on pretest 1 ...
However, I think it is quite fair to get your rating changed, cause u actually tried to solve a problem during the contest ...
you are right :)
Как решается С?
Построим дерево обхода. Запустим рекурсивную процедуру, которая будет разбивать все ребра в поддереве (в том числе обратные ребра, которые начинаются в поддереве) на пути длины 2, возможно, используя ребро, входящее сверху в корень поддерева. После рекурсивных вызовов для детей непристроенными будут только некоторые ребра, инцидентные корню поддерева; в зависимости от четности, либо берем ребро наверх, либо нет.
Собственно, явно дерево строить не нужно, можно за один ДФС все сделать.
Я не знаю, как рассуждал Endagorion, поэтому опишу свою цепочку рассуждений (решение в итоге получается идентичное):
Итого, моя реализация — DFS для разворачивания ребер и восстановление ответа циклом.
А будет ли разбор?
Будет завтра.
Thanks for the round!
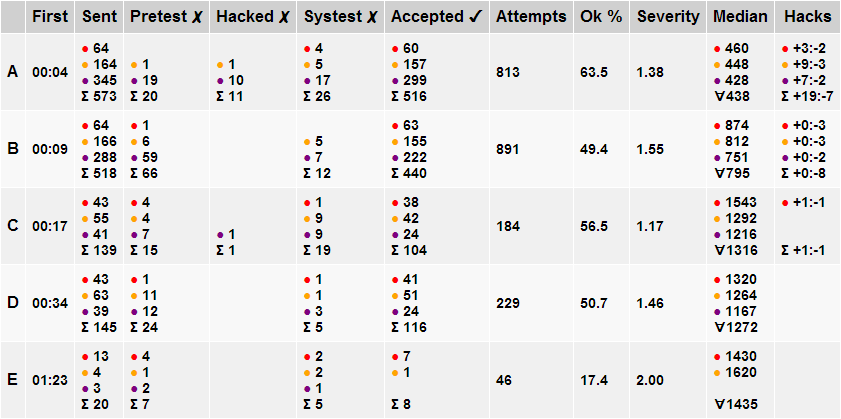
Maybe it makes sense to integrate your statistics into codeforces instead of creating a blog?
first contest and become purple. happy~ >.<
Is there a quicker method for console input in java, other than BufferedReader or scanner?seems that using either of them cannot pass problem c in div2?
Just now I translated my code into c++, and I used "scanf" for console input.It passed.
I used BufferedReader in java (Scanner will not do with 1000000 lines) and it worked perfect.
By the way I see no solution with BufferedReader among your 3 submissions.
It is here. http://codeforces.me/contest/405/submission/6114625 Did I make some mistakes?
No mistakes, but probably there really are some points to improve:
For 1000*1000 matrix your two pairs of nested loops will give 10^6 iterations each (and this is not necessary as I've told) so you probably spend significant time in vain and then there remained too few time for printing answer with "print".
Check my solution (it is similar except details mentioned): 6111736 — it really takes less than 200ms... So I do not think you need to resort to C, though surely Java is slower :)
Thank you very much for your suggestion!
Many Java coders use a self-written FastScanner class or something similar. For implementation details please look at any of my submissions.
OK, thank you!
i'm not expert, but i dont see what's the difference between ur
FastScannerandjava.io.BufferedReader.can u please explain the difference? thanks.
Oh, it seems that you don't know Java at all...
Please read about BufferedReader. Then please read about Scanner. Then please understand that FastScanner is a recreation of Scanner's most useful features for competitive programming that works fast (contrary to Scanner). Then you won't ask such stupid questions.
I'm waiting for editorial .
thank you
me too
hehe
Никак разбора не дождусь
The tutorial will be tomorrow they said. Wait for it, they said. -_- :DDD
Read it, I say now. :)
For those, who didn't find it — see the tutorial Here :DD Thanks gen for the excellent round! :)))
Thanks everybody for participating in this round! We would like to hear your thoughts: what did you like very much or not so much? What can we improve in our next round? (Apart from the late tutorial, sorry for that..)
The Style and the format of problems were very interesting (especially prob. C and D in div. 2)! I liked the problem statements, they were very clear and easily understandable.
Maybe the only thing that I didn't like so much, is that there was little opportunity of hacking someone's solution, maybe for some of us it's good, but I think that passing the pretests almost meant passing the System Testing.
But, in general I hope seeing more this kind of rounds here at CF. It can serve as an ideal example for the upcoming contests. We are waiting for other, even more interesting and challenging problems!
Thank you for the hard efforts ! :)
I liked that the authors messed with my head in Div1 B/Div2 D by making an example where |X| did not equal |Y| (because one term was 0 and could be omitted), and then writing
instead of
Thanks for organizing the round. I tried to solve problems A-C in Div1. Problem C was excellent: a "natural" problem and a very clear problem statement. Problems A and B were also interesting, but they were somewhat difficult to understand due to the complex problem statements. In addition, it's not nice when cin and cout are too slow (and warning about this makes the problem statement even longer) — maybe it wouldn't have been necessary to use so large test cases.
Cin and cout aren't too slow if you use the right tricks. (Okay, they are sometimes, but such problems are very rare.) It's not actually an author's obligation to warn about it, and in some problems it even seems unnecessary (200000 integers is hardly an extra large test case) — take it as gen's generousness of sorts :D
I think div1 problems (A-D, I don't know how to solve E so far) are really awesome. Thank you for the contest.
I found E simpler than C and D. Don't be afraid of it, it isn't hard at all.
Yes, during the contest I try to solve E after a lot vain work on C and D. However it requires more patience which I am lack of. Finally I solve it in the practice.
Непонравились прыжки количества данных в претестах, например в задании "D" (Div.2) первые 9 претестов дают макс. 9 данных, а 10-ый претест дает — 500 000 (макс. количество). Из-за этого трудно определить — сколько времени нехвотает для решения.(мое решение паскалем ели справилось — 935 мс (6129758), но незнаю, сколько нехватает другими языками)
По идее, для проверки того, укладывается ли в таймлимит Ваше решение, стоит пользоваться вкладкой "Запуск".
Кстати, в Вашем случае проблема с медленным вводом/выводом. К сожалению, я в Паскале не разбираюсь, поэтому вопросы по поводу быстрого ввода/вывода на этом языке явно не ко мне.
С другой стороны: если, например, в претестах 5 и 6 соответственно ограничения 10000 и 100000, большой ли смысл ускорять решение, которое не работает для 10000 только до такой степени, чтобы оно свалилось на 100000? Скорее, лучше сразу получить информацию, что решение не проходит во время в худшем случае (то есть макстест).
Согласен, но если разница по-меньше, например 120 мс (из 1 с) в тесте с 10к (когда макс — 100к), то можно предположить что на макс-тесте будет работать 1,2 с (если O(n)), тогда можно поковыряться в коде и иногда найти, где ускорить.
Ну дело в том, что сейчас хорошим тоном считается класть мактест в претесты. Так что можно на это рассчитывать. К тому же, каким образом во время соревнования можно узнать, какие ограничения даны в тесте? Поэтому мне лучше нравится политика: «ТЛЕ на претестах, значит не проходит макстест».
239 ?
http://codeforces.me/contests/407,408