


→ Pay attention
Before contest
Rayan Programming Contest 2024 - Selection (Codeforces Round, Div. 1 + Div. 2)
4 days
Register now »
Rayan Programming Contest 2024 - Selection (Codeforces Round, Div. 1 + Div. 2)
4 days
Register now »
*has extra registration
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3993 |
| 2 | jiangly | 3743 |
| 3 | orzdevinwang | 3707 |
| 4 | Radewoosh | 3627 |
| 5 | jqdai0815 | 3620 |
| 6 | Benq | 3564 |
| 7 | Kevin114514 | 3443 |
| 8 | ksun48 | 3434 |
| 9 | Rewinding | 3397 |
| 10 | Um_nik | 3396 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 155 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 10 | nor | 152 |
→ Find user
→ Recent actions






Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Nov/26/2024 13:17:35 (k3).
Desktop version, switch to mobile version.
Supported by

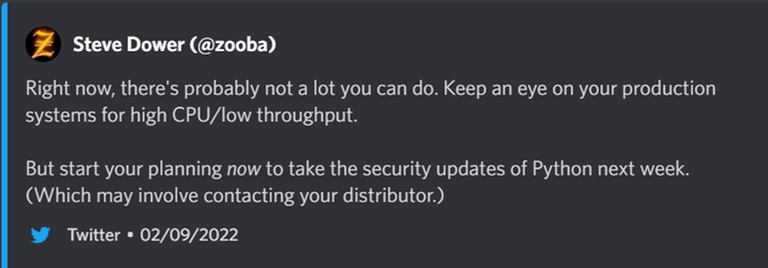
BREAKING NEWS: Another potential DoS attack discovered targeting Turing machines. The exploit is based on just using the program normally and then spend eternity waiting for the program to terminate because of the halting problem.
BREAKING NEWS: Another potential DoS attack discovered targeting Python programs. The exploit is based on just using the program normally and then spend eternity waiting for the program to terminate because it's Python
In all seriousness though, this is one of the dumbest things I have seen a language do to itself. It almost feels as if a person who was too lazy to sanitize their code decided to mess with the Python community and accidentally got this to pass.
Can someone tell me why this is a big deal that you can't just get away from by using a simple
len(a)orn.bit_length()check? It would have been a different thing if you could pass a generator toint(), but that is not the case.Or is the sole argument "people can't sanitize their code so we will break functionality everywhere just to spoonfeed them"? This arbitrary cutoff also goes against the Zen of Python (to read more about it,
import thisin a Python interpreter).If this is a security update, then what about the argument made in this PyPy issue where they mention that the Python devs didn't want a performance impact and sacrificed security (using anti-hash hacks, you can, in theory, DoS a service that uses
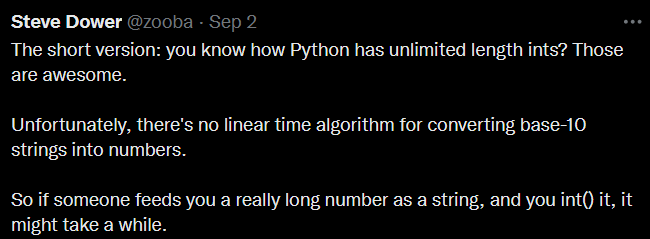
sets).Just for the record, I am told that GMP uses a much faster string to int (and vice-versa) implementation which is also subquadratic (which takes < 1s when Python takes > 8h). Of course, you can do a divide and conquer to get an $$$O(n \log^2 n)$$$ or similar algorithm, which, depending on the implementation, can be much faster than $$$O(n^2)$$$.
The more I see stuff about Python, the more it seems like it is trying to cater solely to people who can't write code for the sake of their lives.
pleb:
n * (n + 1) / 2pythonic:
np.sum([*range(0, n)])nope; it is still
n*(n+1)/2in python as well!PS: Downvotes Incoming, as the Pleb here is a low-rated person with some opinions :)
It's
n * (n - 1) // 2if $$$n \ge 0$$$,0otherwise.As a reminder to everybody the Python Community Code Of Conduct applies here.
Closing. This is fixed. We'll open new issues for any follow up work necessary.
Wrong again :) but I totally agree with all the other points that you have made.
I like to cite my sources, so here you go.
Haha, range(n) iterates from 0 to n-1, and isn't the same as first n natural numbers, besides that, if you use integer division and forget your brackets, u will end up with the wrong answer with a probability of 50% :)
Are you sure about that?
DAAAAMNNN, Operator Precedence and Order of Execution! This whole comment chain isn't as unnecessary as I imagined it to be, as it taught me something :). But I still feel this is spam compared to all the awesome real problems you have been discussing :).
Looked for this being related to weird crypto nerds wanting to upstream their weird nerd use cases rather than defaulting to proper weird nerd 'skill issue' for all things. Was disappointed to not be disappointed.
The heck does it even mean?
UPD: ah, I see...
Since I don't follow Python developments much, I wasn't expecting the vulnerability to be one I already knew about...
Of course, I assume the real problem isn't so much that int/str conversion is slow as it is some combination of:
(It could be argued that 1 is a special case of 2.)
I'd like to see some day a language and ecosystem that really takes a
Trusted/Untrusteddistinction seriously, so that passingUntrustedinput to a function meant forTrustedinputs is an error at compile-time (or at module-load-time for interpreted languages). But I have a hunch that the Python ecosystem will never get there...The funny part about multiplication in Python is that the Decimal module switches method of multiplication between quadratic, Karatsuba and NTT (AFAIK, normal ints switch between the former two) based on the size, so basically using the Decimal module you can simulate FFT but its hard to explain to others because its really FFT and not FFT at the same time (in a sense that it does use FFT but we didn't really "implement" it ourselves)
This is so bizarre. What's the smallest $$$\varepsilon$$$ such that an $$$O(n^\varepsilon)$$$ algorithm deserves a CVE? More or less than 1.5?
Toom-3 multiplication: "$$$O(n^{1.465})$$$ is fine... right? sweats"
Is imachug okay? I dislike the notion that this thread might have radicalized him (sic). Like, it's one thing to kekeke at things from a safe distance, but once a fellow cp'er actually goes over there and does something even more cringe... the black mirror this casts on our accomplishments of sand is... even more depressing than my not having any to speak of :P
What is funnier is that they respond by closing the issue with a "Code of Conduct" notice (sure, the comment might have been a bit too aggressive, but it's questionable to completely ignore the valid points made). I feel imachug's comment was quite valid and not really cringe since it concerns the future of a very widely used language and the points made in the issue about how this change will have people relying on it make it all the more important to make a more informed decision.
are you kidding me, this breaks some of my things
can we just fork python into notTrashPython or goodPython or something
also, I found imachug's comment very informative, so I am thankful for that and agree with nor on this one
Let's hope PyPy doesn't go forward with these changes, though I am highly doubtful that it will be the case, since they try to use CPython as a reference implementation.
unpopular opinion: can't we just be given the choice to be able to use Cython? thinking
grah, sure, not out to attack, and definitely not out to defend the dumb change...
To me, I saw a line being crossed, like once you engage the people actually doing the work, you're no longer in cynical "why bother" territory (e.g. happy to self relegate and kekeke about dumb tweets after the fact) and instead operating under the assumption that there's a non-zero chance of course correction... therefore: why not maximize those non-zero odds?
Even charitably ignoring gaffes in tone (meh), opportunistic aim, and reactionary timing, there were mistakes about the facts of the dumb fix. Like, the strawman of having to recompile requires you to ignore the 'configurable by environment variable' part... and while I agree: what a terrible cop out to account for a change I don't want in the first place! dynamics like that, where the post launches into the abstract at the expense of the boring mechanics/facts... it's not surprising or funny to see someone 'nope.' out of that stabby energy. It's a missed opportunity (if operating under the assumption of non-zero chance of course correction).
Sorry to similarly beg off, just found out I'm not actually free during the upcoming contest. Ultimately (tl;dr), saw a train wreck, wanted to check in on our boy... hope the badly chosen entry point doesn't sour future attempts at contribution because I want cp to have a good endgame (even if I'll likely retire well short of it).
You're somewhat right.
I'm sorry.
I'm well aware that I'm a bit of a misanthrope, an opportunist, I'm often way too harsh, and my soft skills are, well, lacking. I try to compensate for that most of the time, but sometimes I slip or don't limit the anger seeping through the keyboard well enough, and you get something like that comment.
But I think the main problem is not that I replied. If I didn't, we'd have the same result in the end. I also deliberately didn't link myself to the competitive programming community. I read the comments of this post and realized the feelings are generally not as negative as I expected them to be, so no harm done here either. As for engaging the people actually doing the work, well, what's the point in lol'ing at this on Codeforces? I honestly don't understand why one would do that without trying to correct the (perhaps even benign) mistake.
No, the main problem is that I was the only person who retorted. You also mentioned reactionary timing and, well, you're right, but I've got a better job than monitoring the bug tracker of every single tool I use, and when I did notice the problem thanks to this post, I replied almost immediately. What I don't understand is why others didn't do the same so that we had a chance to fix the problem earlier; this is as much my fault as everyone else's. There are lots of people using Python for competitive programming. There are lots of cryptographers out there. I'm certain there are thousands of developers who rely on this feature, perhaps unknowingly via a dependency, but none of them deemed it necessary to reply. If anyone, like [profile:nor], or [profile:-is-this-fft-], or even you replied, I would upvote your comment and move on. With complete lack of vocal disapproval, I didn't have much choice.
With that out of the way, to more specific notes:
Mea culpa. I didn't read the snippet by mdickinson thoroughly enough and mistook the sign in the comparison with
_PY_LONG_MAX_STR_DIGITS_THRESHOLD. I thought the check was "if it's more than_PY_LONG_MAX_STR_DIGITS_THRESHOLD, abort immediately", rather than "if it's less than_PY_LONG_MAX_STR_DIGITS_THRESHOLD, report success immediately". Still does not seem like the brightest idea, though, if people want to lower the threshold more than that for increased timing guarantees.Sometimes there's no simple answer--you can explain why the idea is terrible, but not find a better alternative. The goal of my comment was to say "guys, that's won't work, let's try to think of something else and fix the algorithm", rather than provide the ultimate solution. That's how I interpreted the "let's just add the limit" idea, anyway: it was the simplest fix they bothered to think of.
On a more positive note: we have in fact chosen the entry point years ago. There are issues by CPers on PyPy and CPython bug trackers regarding hash-based data structures and certain optimizations. I'm sure my little tantrum doesn't make the trust in CP plummet given that a single person's opinion shouldn't outweigh previous contributions by others.
Just to clarify on the timeline a bit (from my understanding; please correct me if I am wrong): it seems the "bug" was reported a couple of years ago, and there were internal discussions about this CVE that was kept private. About a month ago, this was posted as an issue on the CPython github (with a resolution, which means that this decision was never meant to be overturned in the first place). The OP (probably) got to know of this issue from the tweet, which was much after this happened. No amount of discussion at that point could have gotten them to change the behavior which was already pushed.
Regarding the reason I didn't comment on the Github issue: I was rendered speechless by their absolutely flawless handling of the issue, so I felt I should avoid expressing my mortal concerns on such a platform, and limit my exercise of freedom of expression to a platform with mortals like me. Not to discredit you, I believe you said what all of us wanted to, since there is no other way of putting across concerns than to talk it out.
One thing I didn't like about this change at all was its treatment as a CVE, which (according to them) meant that they had to come up with solutions in absolute secrecy. I believe the categorization of this "bug" as a CVE is just wrong — you can just call near about any non-trivial bug or inefficiency a CVE if this is a CVE. They use this to justify not having taken opinions from everyone, and it is astonishing to see that none of them cared enough to do enough research on the problem at hand, and all of them jumped to the trivial (and most destructive) change possible.
The entire reason why I posted this blog is that found this whole thing to be both laughable and stupid, and that I wanted to create awarness about it.
str <=> intconversion running in O(n^2) was being treated as some huge secret vulnerability in Python, even though this arguably isn't even a bug, let alone a CVE. I'm not able to find any open discussion about the issue before they decided their (in my opinion) highly controversial solution of putting weird arbitrary limits everywhere (that are on by default). They even backported this as far back as Python 3.7.While I agree your comment was harsh, you put into words what me and I'm sure many others were thinking. I think your criticism was on point. It seems to me that the authors didn't even realize what they did was controversial, and I think that your comment was food for thought for them.
Here is a document describing their thoughts about issue and their fix of introducing limits. Here are some quotes
From a test suite perspective of running all “~million” Python tests in Google’s huge internal codebase (which includes those of a large percentage of popular PyPI packages) on a 3.9 interpreter carrying this patch: It was extremely rare to find any tests tripped up by this change! Futurama “good news everyone!” meme. ...
... Thus we do not anticipate that most Python users will ever notice the limit. The rare few that do get an understandable error message, and can work around it in their application by adopting hexadecimal for example, or use our well documented ability to change or disable the limit. [I expect a stackoverflow question discoverable via an error message search to wind up with an answer pointing that out as well]
Another thing I want to note on is that there is a good, valid, and "easy" fix for the entire issue. Just use better algorithms! Even this simple pure vanilla Python implementation runs 10 times faster than built in
int()for 2e6 digits.It runs in subquadratic time since Python multiplication uses Karatsuba. If Python had used a faster big int multiplication algorithm than Karatsuba based on FFT, like GMP does,
str_to_intcould run a 1000 times faster than whatint()currently does for 2e6 digits.Here is a comment just posted by gpshead (member of Python Steering Council, and the author of the fix involving arbitrary limits) on an old issue about speeding up
str <=> intconversion.Bigint's really feel like a neat computer science toy most of the time. We've got them, but what actually uses integers larger than 64 or 128 bits?
-gpshead
At least he is good at derailing and shutting down conversations.
Here is a comment posted by tim-one, which summarizes everything: "It's closed because nobody appears to be both willing and able to pursue it"
There's exactly 0 people in the whole world, who happen to have both motivation and coding skills to make it happen. Also being noisy and obnoxious is unlikely to motivate anyone.
Actually that is not true. People have very seriously wanted to do this in the past. See for example this. But at the time Guido told him not to do it.
That said, at that time, no one saw quadratic
int <=> strconversion as being a big issue either.Next week they will discover SQL injection.
The fix? Python will throw a ValueError if you try to create a string containing any of "INSERT", "UPDATE" or "DELETE".
The reasoning? "Everyone auditing all existing code for this, sanitizing text inputs, and maintaining that practice everywhere is not feasible nor is it what we deem the vast majority of our users want to do."
and maybe, just maybe, that's when SQL becomes anti-Pythonic
Python HAHAHAHAHA !
Python is doomed I guess.
The decision itself is one thing but their answers cause me to doubt that python is in hands of people who understand what they're doing at all.
: Let's solve this vulnerability by hardcoding some arbitrary number in source code, seems like a good solution.
: There is this thing called fft
: Yeah, we will improve the algorithm but we will do it later so that people will get used to our limits and we will not be able to remove them. Clever, hah?
: this would speed up bigint multiplication and division
: could you provide practical applications when you would need fast arithmetic?
: you know that your fix that you merged, does not work because you check it only after you did quadratic calculations?
: oh, right...
What the heck am I reading?
Thanks to this link provided by pajenegod, now the way how Python developers handled this CVE makes perfect sense to me. And I think that it was a very reasonable solution.
Basically, there is a slow built-in bigint implementation in Python and also a fast state of the art external GMP library. Python developers don't feel like doing any work to improve the built-in implementation, because improving it to be as good as GMP would be a monumental effort. From the purely technical point of view, just using GMP as a backend would be a perfect solution. But Python can't always use GMP as a mandatory dependency, because the GMP's LGPL license is too restrictive for some of the Python users.
Now about the CVE fix. Most users dealing with reasonably small numbers won't be affected at all. And those, who manage to trigger ValueError in their code, should actually consider using GMP via something like https://pypi.org/project/gmpy2/ and enjoy much better performance. If they can't or don't want to do this, then
Competitive programmers won't be affected on the Codeforces platform if Mike takes care of disabling this "Integer String Conversion Length Limitation" after upgrading Python. Moreover, competitive programming problems are normally designed not to require bigints anyway.
If somebody still doesn't like the current situation, then they are welcome to implement a new state of the art GMP replacement library with a less restrictive license and convince Python developers to use it.
One motivation to use Python is problems with bigints. You don't even know that...
If that's what you propose, you should be the one to do the convincing.
Of course I wouldn't know about your motivation without you telling me about it. After all, I don't have a crystal ball to read your mind. Though it doesn't look like you had any real opportunity to use Python on the Codeforces platform for this purpose (or for any other purpose) since 2020. Do you have any idea why is it so?
Also if you are looking for a decent bigint support for competitive programming, then Ruby is probably a better choice than Python. Because Ruby uses GMP and this makes it much faster. Here's pajenegod's code from this comment converted to Ruby and benchmarked against Python:
If both Ruby and Python are using GMP, then they have nearly identical performance (the Python version of
str_to_intfunction can also take advantage of GMP ifpow5 = [5]is replaced withpow5 = [gmpy2.mpz(5)]in the code). But if Python has no access togmpy2module, then it is much slower than Ruby.You can try to run these programs on Codeforces customtest or AtCoder customtest. Though none of these platforms have
gmpy2module installed for Python at the moment.Now to sum it up:
gmpy2for Python and this is again an ideological/political issue (Codeforces only offers standard built-in libraries for all programming languages without any extras and this is bad for Haskell folks too).As I already mentioned in my previous comment, the CVE fix doesn't affect me and I don't need to do anything. And I don't think that the CVE fix really affects you either, but feel free to correct me if you disagree.
Because it doesn't have the fine control I want. Performance isn't a problem if I can improve it easily, which I can't. I use Python often to test out simple things and C++ for "serious" code, and I know how to combine them.
(Btw, it's the same with Ruby, so no reason why I should use either aside from rare cases like april fools. C++ doesn't have bigint support out of the box, but is flexible enough that I can add it.)
However, the fact that you write this shows that you know it can't be my motivation, so you start your post by intentionally misinterpreting things!
And yet, you're telling people what to do. You don't need to post anything, but you do.
It affects me outside CF.
FWIW, "safe Haskell" is not GHC's default behavior, and Codeforces stopped passing
-XSafein February 2021, just a couple of weeks after gksato bumped that post.I mean the missing useful modules in the Codeforces Haskell setup, such as Data.Vector.Unboxed. For example, this Haskell submission for the AtCoder Beginner Contest 228 problem C — Final Day won't run on Codeforces:
That's only a bare compiler setup without any extras. If some of the useful functionality is not provided out of the box (such as
gmpy2ornumpyfor Python), then the users are handicapped on Codeforces and CodeChef. AtCoder is better. And Meta Hacker Cup is the best because of absolute unrestricted freedom in programming languages and libraries selection.OK. The blog link you provided isn't very relevant to that. The situation with
gmpy2andnumpyis much worse; Python users have no hope of getting similar functionality with anywhere near the same performance. But the available alternatives to the Haskellvectorpackage are not less efficient: They are mostly just more inconvenient to use efficiently.Improving Python's default bigint behavior to be as good as GMP would indeed be a monumental effort and mostly a waste of time. But GMP's speed is also overkill for the purpose of mitigating possible int/str conversion-speed attacks.
But note that the reason provided for not improving the speed of these conversions was not "we don't have the resources to develop and maintain an implementation of the faster algorithms" but rather:
Forgive me if I expect the Python Security Response Team to research more effectively than this.
I believe the issue is how the definitions of a suitable compromise for the Python Steering Council and the competitive programming community differ.
A reasonable compromise in my opinion is to not optimize it to state-of-the-art (and thereby let go of an all-or-nothing approach to this debate) but just making it "good enough" for some definition of "good enough", since you can get decent improvements by using a simple (not heavily optimized) implementation of Schönhage-Strassen for larger numbers.
The approach taken by them is to simply disregard any optimization possible since optimizing it to the point of GMP is impractical for them, and breaking functionality is a suitable solution in their opinion. If they care enough for this issue, why not choose the better solution? Their reasoning is also very weird: if they really don't want users to change their code, why are they adding a breaking change instead? If I were a beginner, I definitely won't expect an innocent line of code like
int(input())to give me a value error at an arbitrary cutoff. Also, it's not easy to control the size of integers in certain situations, as pointed out by Tim in this comment. It is not just user input, but also stuff like parsing and dumping of expressions in a symbolic computation library that doesn't use GMP that will be affected by this.Regarding the point that "this change won't affect a lot of people": counterintuitive behavior that triggers very rarely is a bad design practice (principle of least surprise). It's harder to make tests for such situations in real life code too — the fact that "this doesn't trigger tests" shouldn't be a cause for celebration, but one for concern.
Regarding "those, who manage to trigger ValueError in their code, should actually consider using GMP": a language should have sane defaults. If people are using bigints, they would expect arbitrary precision integer arithmetic to work seamlessly and correctly. If there is a limit on the size of things that work, the presence of a limit should be uniform across all functionality (for instance, that is how stuff works in C/C++/Java), right? In the spirit of this change, shouldn't Python devs also limit bigints to a certain reasonable limit, and leave us with a finite size bigint? Also, CPython bigint division is quadratic, so what happens after user input triggers quadratic division should also be handled in the CVE, and this is another argument in favor of adding an arbitrary limit to integer division, if this solution is to be extrapolated.
Giving options to get by this arbitrary restriction is a classic example of retrofitting solutions to problems posed by poor solutions, and just gives a false sense of control over the situation.
At least
int(input())throwing exceptions is kind of natural when parsing user input. You'd normally get a value error if someone tries to input a string that isn't a number. However something likeprint(x)returning an error for an integer (just because it happens to have > 4000 digits) is much more unnatural. Code written before the 4000 limit was introduced would not have taken this into account.I don't know the point of limiting int to string conversion either. If big ints are not allowed to be part of the input, then how could they unexpectedly appear in the output? Creating a big integer from small integers would also require using multiplication, which is kind of slow, so it isn't like
str(x)is a bottleneck.As a reminder to everybody the Python Community Code Of Conduct applies here.
Closing. This is fixed. We'll open new issues for any follow up work necessary.
Oh boy Python fucked the dog on that one. Twice.
purplesyringa totally agreed, it's not a vulnerability but an inefficiency and can't be solved in any other way than making it more efficient. Hard limit on number of digits would be an anti-solution, while soft limit is a non-solution to the problem at hand and could let it slip under the radar. Above all, it's a complete category error.
Here are some more interesting links about this issue:
int/str conversions broken by latest CPython bugfix releases #24033
discuss.python: Int/str conversions broken in latest Python bugfix releases
news.ycombinator.com: Prevent DoS by large int-str conversions
PR for fast int -> str conversion
I wonder if next week there will be a new CVE from people sending 4200 9s and the server trying to print the number + 1.
https://docs.python.org/3.10/library/stdtypes.html#int-max-str-digits
Are they really that stupid or do they just not care?
As a reminder to everybody the Python Community Code Of Conduct applies here.
Closing. This is fixed. We'll open new issues for any follow up work necessary.
You are absolutely right. There's no shortage of smart people and the Python community will resolve this issue in an iterative fashion (by opening additional issues and additional pull request as needed) with or without imachug. They can easily afford to kick out rude jerks and won't miss anything by doing this.
smart people?
This is kinda true.
The replies at https://stackoverflow.com/questions/25561635/difference-between-subquadratic-and-quadratic-algorithm seem to agree that sub-quadratic means "anything between linear and quadratic". Are they wrong? Or do the best known algorithms not fall into this category?
Also are they talking about average case time complexity or worst case time complexity?
Even the best known algorithms for sorting have sub-quadratic complexity. We decided to use bubble sort as our in-built sort because $$$O(n \log n)$$$ algorithms are too hard for our tiny brains, but we are like 95% sure we will be able to implement and (more importantly) maintain bubble sort. People tend to use in-built sort without thinking, and waiting for 10 seconds to sort an array sounds like a security vulnerability, so after 2 years of deliberation we decided that we will restrict sorting to arrays of length at most 4300 which will ruin thousands of existing programs but hey, now Python is secure.
Something can be true and dumb at the same time.
Imagine a competitive programming contest and an easy problem with constraints, which clearly allow a very simplistic naive bruteforce solution. Would you use bruteforce or spend more time on implementing a more advanced algorithm with better time complexity? And if you have ever resorted to bruteforce in such situation, would you claim that you picked bruteforce because "algorithms are too hard for your tiny brain"? Or agree with somebody else making this claim?
Based on what Python developer Tim Peters said, he implemented bigint support two decades ago and this code was kept mostly unmodified since then. The code did the job and the users were mostly satisfied with it for the tasks that they did with Python.
Now the requirements/constraints have changed for Python. Because specifically crafted malicious input data needs to be also taken into account. The bigint code is not "good enough" anymore and Python developers are currently working on resolving this issue.
Can you provide some examples of these existing ruined programs? Python developers clearly stated that the limit was selected to be large enough not to break existing applications and have done some extensive tests.
Google sarcasm
Near-quadratic and sub-quadratic are just "vague words" according to the Python Steering Council. From what I can tell, no one of them knows algorithms or time complexity at all.
@ mmaxio comment
We now know that $$$O(n \log n)$$$ is not a vulnerability, but $$$O(n \log^2 n)$$$ apparently is.
Based on the data I have so far, I would suggest the following hypothesis: $$$T(n)$$$ constitutes a vulnerability if and only if $$$\sum_{n=1}^{\infty} \frac{1}{T(n)}$$$ converges.
It wouldn't be surprising if Python devs say that an algorithm that is exponential only when $$$n$$$ is a power of 2 (and linear elsewhere) is not a vulnerability, because you can raise a ValueError at powers of 2.
The "even" is the thing that pops out at me the most. What is wrong with having an $$$O(n \log n)$$$ algorithm? Is it worse than the $$$O(n^2)$$$ algorithm that they provide? Please don't say it is about the constant factor. We are talking about large $$$n$$$, and GMP implementations prove that you can do vastly better. You don't even need to look at the highly-optimized implementations; I am sure that if you implement them in a relatively easy way, you would still be much better than using a quadratic algorithm. Writing a Karatsuba-esque algorithm is not hard either.
Slightly unrelated: I don't think you can quote the replies at the stack overflow link as authoritative. Subquadratic means $$$o(n^2)$$$, with the little-o notation. Even $$$O(\log n)$$$ is subquadratic.
If they are talking about a CVE, I think it is ideal to assume that it is about worst case time complexity.
This kind of reasoning sounds familiar, let's look at some other examples:
Boyer-Moore algorithm also "proves" that substring searching can be done vastly better than a naive implementation. Except that its worst case time complexity is less than ideal and it can be used as a DoS attack vector. At least one Python user learned about this during Meta Hacker Cup round 1.
Hash tables "prove" that key->value lookups can be done with a better time complexity than O(logN). Except that HashDoS mitigations are necessary when dealing with untrusted input. Also the initial fixes turned out to be flawed and the issue had to be revisited again in Python and in the other programming languages.
Quicksort "proves" that sorting can be done vastly better than a naive O(N^2) bubble sort. Except that it is plagued by a bad worst case time complexity again. But the story doesn't end here. Python and the other programming languages used Timsort, which was supposed to be designed for O(NlogN) worst case time complexity, but initially it turned out to be not the case due to a bug and needed to be patched up. I think Java people on Codeforces are still affected by this bug even today.
All of these examples above are not something abstract or outlandish. Python developers witnessed all of this themselves when working on their code. So you can't be surprised that they may be a little bit sceptical and won't happily buy your statement that I quoted. GMP is fast, but I don't think that many of its users have ever tried to attack themselves. Yes, we can be sure that it's fast for typical average use cases and this is great. But can we be sure about its worst case time complexity when handling maliciously constructed input? Maybe the answer is yes, but I still would like to confirm that a strict proof exists.
Bigints as a DoS attack vector is a relatively new thing. I expect that the world best security researchers and computer scientists will be interested in thoroughly investigating it and may find something interesting within the next few years. Python will be fine.
My point was that GMP implementations are proof of the fact that you can write implementations for complicated algorithms for arbitrary precision arithmetic that run fast. As far as the worst case complexity is concerned, if you read the docs for, say, base conversion, they specify explicitly that it is not quadratic, and it is an implementation of algorithms from some paper which analyzes the algorithm rigorously. This makes most of your points invalid in terms of applicability to this context, but you have some good points if I was talking about ignoring the worst case.
Just to add something about the current state of affairs: there are multiple pull requests in CPython aiming to improve int multiplication, division and base conversion, all(?) of them being $$$\tilde{O}(n)$$$ (at least you can use multiplication to implement both of the others in such a complexity), and it seems like even when implemented in Python itself, they are much faster than the current CPython implementations and don't suffer from scaling issues. Let's hope they make it to CPython at some point.
I think you're factually incorrect about Java sort. Timsort is now used correctly in the Java collections sort (so it is guaranteed $$$O(n \log n)$$$), and for primitive types, they use dual-pivot quicksort, which has an $$$O(n^2)$$$ worst case just like one-pivot quicksort, but is harder to trigger. The latter is why people have issues with sorting in Java.
For Boyer-Moore and hashing, I agree with you. I am told that Python 3.10 has linear time find and count (that is as of now, can't say if that will be changed in the future).
By the way, if anyone reading this dislikes this change and is a maintainer of a Python library, you should put
sys.set_int_max_str_digits(0)in your initialization code, even if you don't actually need it, as an effective form of protest.It's expressly approved by Gregory P. Smith (gpshead) himself!
Yes, I'm serious, I have the source right here! https://github.com/sympy/sympy/issues/24033#issuecomment-1242330172
Here is another update. Seems nothing will make the developers change their mind.
My main issue with the change is that I belive limiting
str(x)does nothing but create bugs and frustration, and I think I have a pretty good argument against it. So I tried posting about that on discussion.python.com. Alsostr(x)being slow is not even part of the CVE description, and I haven't heard them motivate the reason for limiting it.TLDR
"i set up a fence gate to stop thieves, it was really expensive but i think it's worth it"
"but you have no fence"
"that's not relevant to the discussion"
Oh yeah, hexadecimal output on codeforces, just sounds like usual codeforces but hell breaks loose
I think David is correct here, although he didn't explain his position very clearly. The point is that a) it is common for programs to log internal data, including bigints, and b) some programs might receive hexadecimal input and parse it into bigints. The bigint would then be converted to a string during logging.
Whether the hexadecimal integer was parsed as part of a YAML input is unimportant -- perhaps YAML was a poor choice of example, since there are easier ways to DOS a program using YAML. But surely there are other contexts in which python programs would parse hexadecimal integers, and those should be taken into consideration too.
Of course, this is just bickering about a minor detail that doesn't matter much for the broader discussion.
Regardless:
It seems to me that they're somehow trying to retroactively justify this change, and not even accept any compromises or rollbacks, by positing various hypothetical upside scenarios that services accepting untrusted inputs without sanitizing them could be slowed down, while ignoring any hypothetical or real downsides. It's a kind of "toxic optimism" that can be used to justify any change, no matter how disruptive
Flagging and deleting pajenegod's comment on this, instead of actually making an argument for why it's off-topic, doesn't speak well for their motives for redirecting discussion onto a platform they have such control of
My comment is not technically deleted. It got "community flagged" (by I think davidism) and is now hidden for being "off-topic". They have been very aggressive about hiding comments. However some other people did get their comments removed for no good reason as far as I can tell, other than being dissapproving of the changes.
What I've realized talking to the devs is that they view Python as being some server up in the cloud. And all it is doing is parsing ints. Errors are completely fine since that would just result in a 500 internal server error, but if parsing an int takes more than 0.1 ms then it is the end of the world.
They have said things like
They simply don't belive in input sanitization. Having the limits as a opt-in feature is a no good either, that would just be too much work to turn on.
They also don't belive in big ints:
Wait a second. What's your opinion on (Integer anti-hash hack) Sets and dictionaries run in O(n^2) time? Do you believe that this is an invalid ticket because the users must explicitly do input sanitization in their code and it's a good thing?
Are you serious? If you are being super pedantic, you could say input sanitization includes handling such cases, but in real life, this is just impractical. There is a limit to how much you can sanitize inputs, and things like sanitizing bigint inputs are trivial to check, compared to the much harder (and time-consuming, possibly too hard and useless) problem of input sanitization for hash collisions. The main point being discussed here is that it doesn't make sense to break functionality as a replacement to not do input sanitization (and arguments made by pajenegod are made under the assumption that this is actually a serious security issue that cannot be solved without limiting integers — which is something Python devs believe in ardently since this was the best solution they could come up with after 2 years of deep deliberation and nothing seems to be able to convince them otherwise).
A better workaround according to pretty much everyone (other than you) in this blog's comments boils down to adding fixes so that the attack vector is not an attack vector anymore — for instance, using more secure hashes for ints as well (in the integer hashing case), and fixing time complexity of int<->str conversions (in the context of this blog post).
By the way, the way you put forth your points with largely irrelevant hyperbole derails the discussion a lot. It would have been another thing if there was something relevant, but you seem to point out random stuff that seems to be relevant, but there is pretty much always a better (AND practical) solution at hand which ends up proving the point that the other person is making. Maybe we just have different perspectives on a lot of things, like how much people are willing to compromise for the sake of certain issues (as in, finding a middle ground rather than an all-or-nothing approach to things), and your solutions are practical for you. This is also one reason why I intend to stop responding to your comments that try to provoke a reaction with meaningless "what if" references to other problems.
For me, it's just that at the end of the day I don't want to have to keep thinking "oh I used a builtin, will this throw an error?", and don't want my code/scripts outside Codeforces to break either with these reckless breaking changes which could have been avoided with a strictly better way of dealing with things. If you are taking an input supposed to be an integer that is a 1 MB string, there are three cases — you want your program to be fast, you're okay with slow execution as long as the answer is correct or you simply don't know that it has a pitfall. The current solution only satisfies users of the first type (people of the second type need to bother themselves with installing gmpy or set this ugly limit [and face horrible execution times that could have been made better] to avoid issues, and people of the third type will just straight up face errors). Making things faster satisfies everyone, since it is fast (and if you are complaining about the speed that scales roughly linearly with the input size, then either you don't understand that taking input itself needs linear time or you just need gmpy at this point, and if that is still an issue, just manually sanitize your inputs and stop complaining), it is guaranteed to work (so the second type of people have no issues with it) and it doesn't take people of the third type by surprise.
Here is another update. The discussion thread on discuss.python.com is now closed cause of babyrage by the developers/forum moderator. So here are some of the highlights
I'm just chilling and reading discussions daily, but still, everytime I see this, I'm done:
Honestly. What a shitstorm.