


Hi everyone!
Yeah, you guessed it right, after a long four month break after the latest div. 1 round which was not dedicated to any official competition, you will once again have the unique opportunity to participate in usual codeforces round. No t-shirts for top-x competitors! No multi-level selection system for the opportunity to compete in final! No esoteric languages or marathon-like problems! We even will not tell you the scoring untill the very end of the round! That's it, like the good old days.
So this round was prepared for you by Ivan Smirnov (ifsmirnov) and me (adamant). We want to thank Max Akhmedov (Zlobober), Alex Frolov (fcspartakm), Edvard Davtyan (Edvard) and Mike Mirzayanov (MikeMirzayanov) for the help in round preparing, and useful advice. Special thank to Edvard for taking the role of coordinator this time and traditionally MikeMirzayanov for polygon and codeforces systems.
Good luck to everyone! We really hope that you will have a lot of fun participating in this round :)
UPD. Score distribution:
Div. 2: 500-1000-1500-2000-3000
Div. 1: 500-1000-2000-2000-3000
UPD. 2. Also thanks a lot to Alex Fetisov (AlexFetisov). Forgive me, please, I have totally forgotten about you :)
UPD. 3. If you missed the editorial, you can find it here.






 online (ie, answer will be received for each prefix).
online (ie, answer will be received for each prefix). 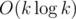 offline. The first algorithm with such an assessment was offered by David Eppstein in 1992, reducing it to fully dynamic minimum spanning tree problem, but here we will focus on a simple algorithm, proposed in 2012 by Sergei
offline. The first algorithm with such an assessment was offered by David Eppstein in 1992, reducing it to fully dynamic minimum spanning tree problem, but here we will focus on a simple algorithm, proposed in 2012 by Sergei 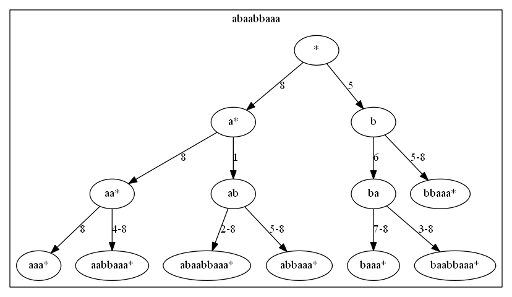
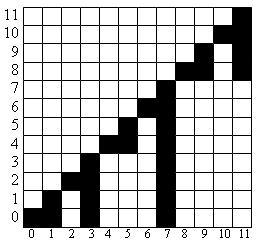 Let the index of cell in the array be the value of element in the set and let the value in the cell be the amount of element in cell. Then we can easily do all required operations in the logarithmic time. Really, the insertion of element
Let the index of cell in the array be the value of element in the set and let the value in the cell be the amount of element in cell. Then we can easily do all required operations in the logarithmic time. Really, the insertion of element 