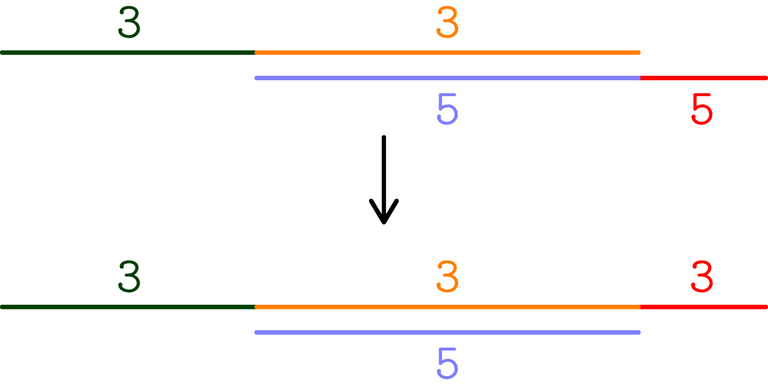
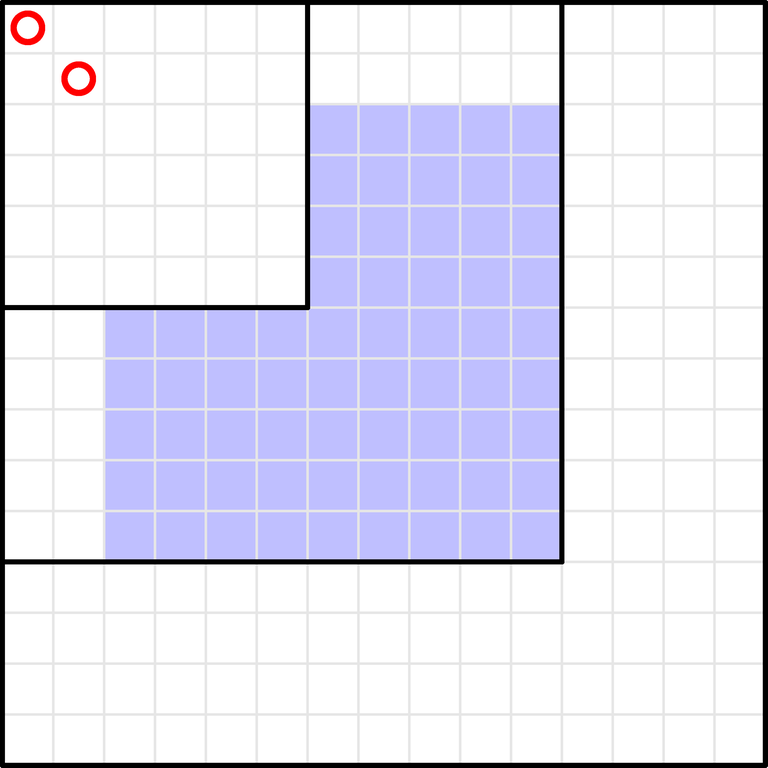
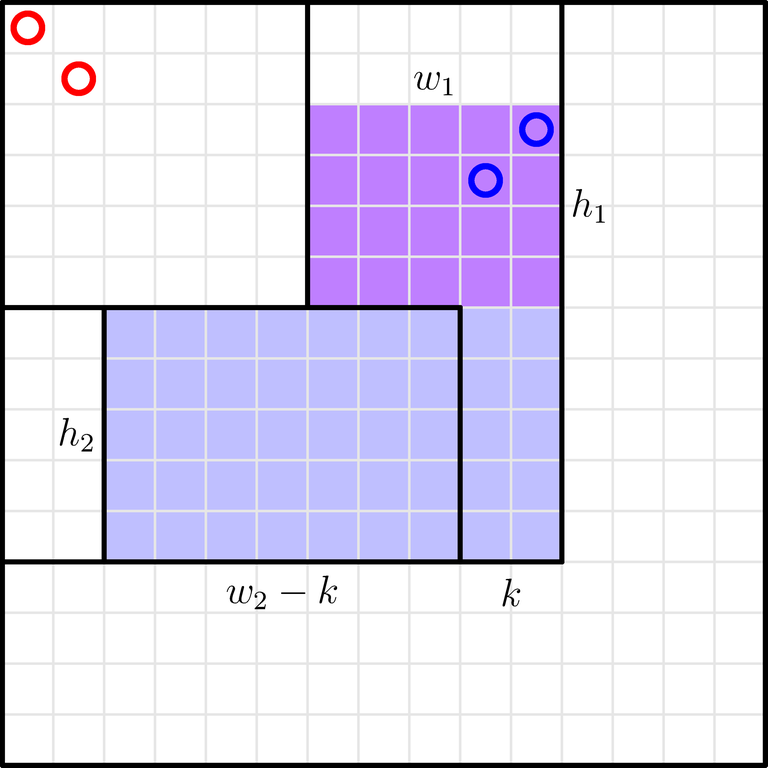
Today I've taken part in AtCoder Regular Contest 186, solved problem E and spent the remaining 90 minutes not solving anything.
Then I've taken part in Codeforces Global Round 27 and spent 90 minutes solving 2035D - Yet Another Real Number Problem.
How to stop being stupid?