


Пожилой чекист спрашивает молодого "Знаешь, какое наше самое главное оружие, на букву Н" - хм... Наган? нет... может, Наручники? тоже нет... а что же? - Балда ты, наше главное оружие есть Нтеллект!
Заранее извиняюсь - этот маленький пост о вещах (системах контроля версий и багтрекерах) которые для кого-то (достаточно многих, обычно, уже вступивших на поприще профессиональной деятельности) банальны. В этом случае лучше его не читать. Ну а если кто поймёт что для него это в диковинку - рекомендую не полениться и изучить вопрос подробнее. (Впрочем, если вы используете их на работе, а дома нет - то возможно надо задуматься, почему это так и правильно ли это?)
Итак, здесь частенько всплывают вопросы типа "какую IDE вы рекомендуете/используете" и немного реже вопросы по поводу "какую ОС". Однако компьютер, ОС и компилятор любимого языка это лишь необходимый минимум того, что нужно программисту по жизни. Есть ещё несколько вещей которые и полезны в личном обиходе - и которые (если их употребить в качестве волшебных слов на самом первом собеседовании) заставят работодателя относиться к вам с бОльшим доверием.
Хотя не следует ждать, что если только вы освоите что-то из нижеперечисленного, то у вас тут же рейтинг поднимется и ник покраснеет. Нет. Просто, возможно, это поможет вам лучше организовать свою учёбу, свои разработки и т.п... ;-)
Системы контроля версий
А где мы храним свои исходники? В папочке, на флешке? Этот подход хорош только тем что он кажется естественным, однако рассмотрим пример: при участии в марафоне, или другом длинном соревновании (типа google ai-challenge) копятся десятки версий вашей программы - в таком случае порой очень хочется уметь быстро найти старую версию, сравнить исходники разных ревизий, отделить разработку какого-то сложного/спорного функционала в отдельную ветку, или вновь состряпать из нескольких веток одну новую и т.п.
Или если вы работаете над небольшой программулиной, проектом более чем одной парой рук - носить файлы друг другу на дискетке, конечно, архаично - но не менее архаично кидать их в общий сетевой каталог, спрашивая "а этот файл ты менял? нет, ну тогда я его затру!" (хотя есть ещё даже целые конторы которые до сих пор на флешках-папочках живут - ну это называется "мужественно создаём себе трудности и мужественно их преодолеваем!")
В профессиональной деятельности такие вопросы возникают вообще постоянно. Ну вот тут мы и приходим к использованию систем контроля версий.
Я не собираюсь описывать как с ними работать - на это есть громадные тюториалы и мануалы. Обычно всё это выглядит так: исходники (разных версий) хранятся в отдельном хранилище (репозитории), откуда вы себе для работы извлекаете нужную ревизию файлов (checkout), а потом, поработав с ними в своё удовольствие, можете сохранить обратно в репозиторий (commit). При этом до коммита вы можете сделать несколько полезных действий:
* update - обновить свои исходники (возможно уже изменённые) новыми версиями из репозитория, если ваш коллега успел там что-то поменять (или вы сами на другом компе поработали над частью проекта в выходные у бабушки, скажем);
* revert - заменить свои локальные изменённые исходники на оригинальные их версии из репозитория если поняли, что сделали что-то не то (таким образом все сделанные изменения будут убиты);
* diff - сравнить свою локальную версию с той что в репозитории (построчно, возможно с выделением цветами и т.п.);
* log - посмотреть сообщения сделанные при сохранении предыдущих ревизий
* и кстати, самому оставить вменяемое сообщение при коммите (например "исправлен баг описанный в тикете № 1529" - см ниже).
Главное то, что всё, что однажды сохранено в репозиторий, впоследствии в нём можно найти (и хранится это в достаточно эффективном по объёму виде). При этом использовать такие системы не обязательно для больших проектов. Можно завести в репозитории отдельные папки например, для задач с тимуса, CodeForces, ProjectEuler и т.п. - даже если большинство файлов будут иметь единственную ревизию, это всё равно будет удобно.
При этом вам не обязательно разворачивать систему контроля версий у себя на компьютере - можно пользоваться готовыми хранилищами в интернете (FreePository, Assembla) и т.п. Но можно и развернуть (это не очень сложно, однако вы можете обнаружить что вам нужно установить и веб-сервер типа Apache httpd, что впрочем тоже не так страшно, как звучит). Необходимым является только клиентский интерфейс, который позволяет пользователю "общаться" со своим репозиторием. Кстати в большинстве современных IDE уже встроены, как в NetBeans (или в виде плагинов, как в Eclipse) возможности для работы с популярными системами контроля версий. Ну кроме того в большинстве систем есть возможность доступа по http - т.е. можно зайти в репозиторий браузером и посмотреть что у нас там творится.
Какие системы наиболее употребимы? Пожалуй, CVS - хотя он сейчас считается малость устаревшим, потом SVN (Subversion) и Git. Нужно вводить в гугле "учебник по SVN" например и смотреть, как им пользоваться (имеет смысл делать это на языке который вам понятен). Под виндовс существуют очень удобные клиенты TortoiseSVN (TortoiseCVS, TortoiseGIT) - они прямо в проводнике помечают изменённые файлы красными флажками, неизменённые зелёными и т.п. (в учебниках вы найдёте кучу поясняющих картинок). В linux часто используется набор клиентских утилит для командной строки - ну они требуют привычки для использования, хотя тоже всё не так страшно, как звучит.
Различия в упомянутых (и других) системах достаточно сильны, однако не очень принципиальны - все они обеспечивают базовый функционал контроля версий.
Я лично сторонник SVN т.к. он сейчас довольно распространён и он есть на всех сервисах управления проектами которыми мне приходится пользоваться, впрочем всё может потихоньку измениться. Многие утверждают что Git это неимоверно круто. Посмотрим как-нибудь.
Кроме того рекомендовал бы, если нет опыта, не начинать знакомство с клиентов, встроенных в IDE (а то можете либо поломать голову, либо развить в себе неадекватные навыки - коммиты по одной ревизии на каждый файл и т.п.), а попробовать сначала отдельный (например TortoiseSVN, т.к. он наглядный).
Эти умения (и клиентские программулины) зачастую понадобятся вам и в тех случаях когда вы захотите поучаствовать в чужих проектах.
Картинка: Windows Explorer показывает папку, находящуюся под версионным контролем - TortoiseSVN расставил забавные флажки у папок. Открыто меню TortoiseSVN, встроенное в контекстное меню проводника.

Картинка: blame в TortoiseSVN - этот режим позволяет посмотреть для данного файла, кто и когда в нём какую правку вносил (см. номера ревизий слева), можно также копнуть и посмотреть что было в этой строке раньше и т.п. - классная вещь когда непонятно, кто накосячил или зачем этот кто-то это сделал (в частности сейчас виден комментарий автора, сделавшего данную правку, к коммиту с которым он сохранил этот файл в репозитории).

Багтрекеры
Точнее "Issue Tracker-ы". Не знаю стандартного перевода для термина. Это системы для исключительно банальной цели, которую многие однако недооценивают.
Допустим, я добавляю функционал в проект и вдруг замечаю, что где-то сбоку, при специфических обстоятельствах выскакивает дурацкая ошибка. Должен ли я сразу кидаться её исправлять?
В общем, нет. Я открываю багтрекер, создаю новый тикет "баг" и пишу в нём "Если в форме такой-то поле Имя длиннее чем столько-то символов, то приложение падает.", устанавливаю важность "пустяк" и жму кнопку "сохранить".
Или если по ходу работы мне пришло в голову что хорошо бы попробовать в используемом алгоритме такую-то простую эвристику - я не записываю это на бумажке, на холодильнике (тоже вариант, но ламерский), а пишу в багтрекер новый тикет класса "фича".
Впоследствии когда я не могу вспомнить чем заняться, я открываю трекер и вижу список недоделок или пожеланий. Выбираю из них либо самое важное, либо самое простое, делаю, проверяю, сохраняю (при работе в команде возможно проверяет другой человек) и пишу в соответствующий тикет "сделал так и так, сохранил в репозитории в ревизии 237". После чего тикет "закрываю" (resolve) так что он в дальнейшем не отображается в списке насущных задач.
Полезно держать несколько трекеров - скажем, по одному для каждого из насущных проектов и отдельный, допустим, для задач о которых вы где-то слышали и хотели бы когда-нибудь попробовать порешать, но сейчас у вас нет времени или скиллов. Да хоть для покупок в магазине, которые приходится пока отложить на потом... ;-)
Удобный трекер обычно может иметь веб-интерфейс (так нескольким человекам легче работать с одним трекером - просто в браузере набрали его адрес и ура), возможность делать ссылки между тикетами или назначать одни тикеты дочерними для других. Кроме того, как уже ясно, многие любят использовать трекер который удобно совмещается с любимой системой контроля версий. Это не очень принципиально, но тоже полезно. Некоторые трекеры содержат в себе wiki, к другим её можно подключить. Большинство трекеров позволяют кастомизацию в широких пределах (нам обычно хочется лишь привести вид к симпатичному, отредактировав css-файл).
Какой трекер использовать? Они существуют как для огромных команд, так и для небольших, в т.ч. единоличных. Правда, большинство из них используют в качестве хранилища какую-либо из известных БД.
Если интересно повозиться с настройкой трекера самому, можно попробовать Mantis, Trac или RoundUp. Первый из них на PHP, остальные два на Питоне (при этом эти два могут использовать встроенную БД, так что её не придётся настраивать отдельно - хотя запустить mysql сервер и создать в нём базу - прямо скажем не ахти какая задача). Трекеров на Java свободных мало, желающие могут поэкспериментировать например с JTrac (или вот популярная JIRA предлагает себя всего за 10долл для маленьких проектов либо бесплатно для опенсорсных?).
Я сам имел дело с разными багтрекерами (mantis, bugzilla, redmine, trac, jtrac) - но когда выбирал для личных потребностей, то скачал RoundUp - мне оказалось его легче настроить, кроме того на сервере, где я его размещал, не было возможности использовать существующую СУБД, а отдельную под багтрекер заводить не хотелось и притом интерфейс мне не показался слишком отвратительным с первого взгляда (особенно когда я слегка поправил стили). Возможностей у него не ахти как много, но внутренние ссылки я наконец нашёл а это одно из самых важных.
Кроме того можно взять "hosted" трекер - т.е. размещённый в интернете и поддерживаемый какой-то конторой, позволяющей завести бесплатно несколько трекеров под собственные проекты. Типичный пример Unfuddle. Если же вы разрабатываете проект на каком-то из известных ресурсов типа SourceForge, то вы скорее всего найдёте здесь встроенные трекер и репозиторий для своих целей.
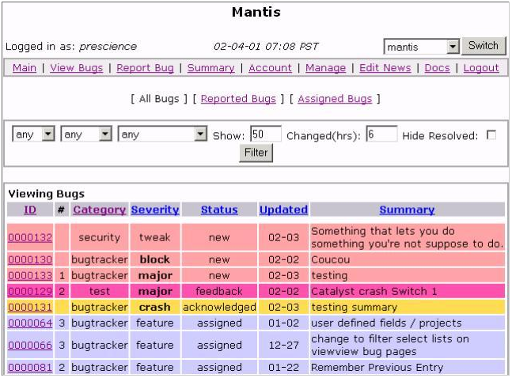
Картинка: список тикетов в Mantis - цвет означает состояние (открыт, отработан, возвращён и т.п.). Видна также "серьёзность" задач и к какому проекту они относятся (мантис позволяет сразу несколько проектов видеть).
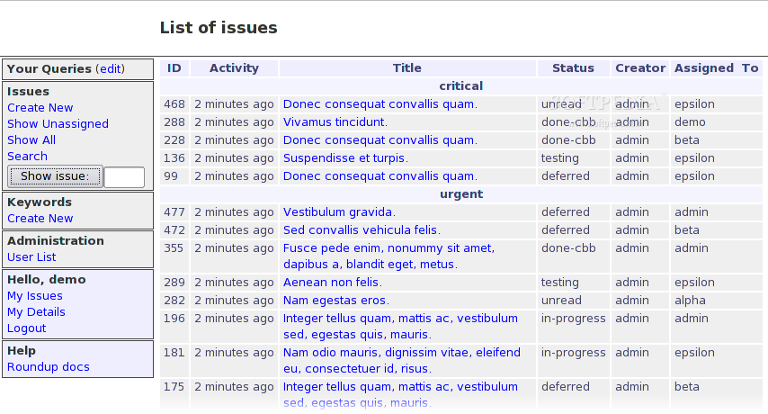
Картинка: список тикетов в RoundUp (по умолчанию группировка по важности - видно, кто создал и на кого назначил задачу).
Картинка: просмотр тикета в RoundUp, видны сообщения, добавленные в разных стадиях работы и история изменения тикета. Видно что цвета, шрифты и т.п. несложно поменять на приятные/кислотные, ненужные поля (типа "зарегистрироваться) удалить и т.п. а ссылка на другой тикет появляется сама если вписать "issue #" (или "msg #" - ссылка на конкретное сообщение к тикету).

Для иных разработчиков иметь аккаунты в нескольких общественных багтрекерах и репозиториях так же естественно как иметь аккаунты в почте и соцсети. Если вы используете подобные софтины (не на работе!), то отпишитесь в комментах о своих предпочтениях.
P.S. Думал, стоит ли в связи с багтрекерами отдельно написать о СУБД, раз уж их можно использовать не только для багтрекера (ха-ха) но и для своих разработок, даже небольших - но что-то подсказывает что это уж совсем будет тупо, общеизвестно и значительно менее актуально.






