


Recently I started making my own library for competitive programming; mainly for our ICPC notebook but also to use in online contests.
While I like the advantage that it gives to me, in my opinion it is against the sport. I don't think we should compete on who has dijkstra ready to be copy-pasted, and who needs to write it from scratch.
Obviously everyone can have their own library prepared, so that they will never have to code up dijkstra again, but this just means that the "quality of life" is worsened — why should we assume that everybody needs to do identical preprocessing to be on equal grounds? This just means we require more work from everybody in the community. Should we also ban vectors and sets and let everybody code their own?
The only downside I see of this is the sheer amount of work required to be 100% sure that the library is bug-free. Of course, it is still possible, just like std::set does it.
What do you think? I hope this post stirs up some discussion on this and maybe we'll improve the global experience from the sport.





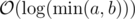 .
.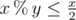 . This is due to:
. This is due to: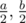 respectively. Once one of them becomes 0 the algorithm terminates, so the algorithm terminates in at most
respectively. Once one of them becomes 0 the algorithm terminates, so the algorithm terminates in at most 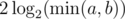 , which implies
, which implies 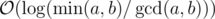
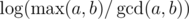 , and lastly notice that we can change the maximum to minimum, since after one step of the algorithm the current maximum is the previous minimum;
, and lastly notice that we can change the maximum to minimum, since after one step of the algorithm the current maximum is the previous minimum; 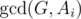 . The known time complexity analysis gives us the bound of
. The known time complexity analysis gives us the bound of 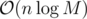 , for computing gcd
, for computing gcd 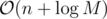 (for practical values of
(for practical values of  ). Why is that so? again, we can determine the time complexity more carefully:
). Why is that so? again, we can determine the time complexity more carefully: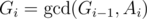
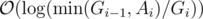 , which is worstcase
, which is worstcase 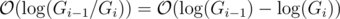 , so we will assume it's the latter.
, so we will assume it's the latter.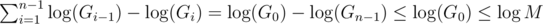
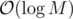 .
.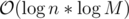 per query or update. We can use (1) to give
per query or update. We can use (1) to give 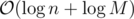 ; an update consists of a starting value, and repeatedly for
; an update consists of a starting value, and repeatedly for  steps we assign to it its gcd with some other value. Following (1), this takes the desired complexity. The same analysis is done for queries.
steps we assign to it its gcd with some other value. Following (1), this takes the desired complexity. The same analysis is done for queries.
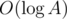 , where
, where 