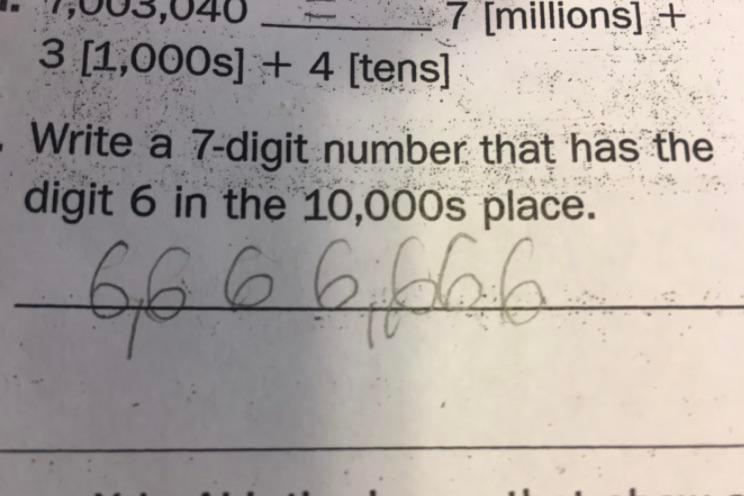I recently solved https://cses.fi/problemset/task/1193/, and I found that using pointers here was a natural way to efficiently keep track of the shortest path. At first I had a vector of type obj, each of which contained a pointer to the type obj, but I soon learned that these objects were not actually returning their own memory location! Instead they seemed to take on the memory location of the front of the queue. To try and fix this, I changed it to be a queue of type obj*, but now I could no longer add things to the queue like this q.push({0,0,"",nullptr}), instead I could only get it to work by adding a constructor to obj, and building objects on the heap. Am I missing a simpler/elegant way of doing this?
The solution in question: https://cses.fi/paste/0c68129b81b0a8252c88f4/