


Hi everybody.
Deadline24 is an international programming marathon, organized continually since 2009 by Future Processing. During the contest, the teams of three tackle algorithmic problems.
The marathon is composed of two phases. The qualifying round starts on March 12. For 5 clock hours, the teams will be solving tasks and generating responses assessed by the verification server. This stage of the competition is remote. Then, the best teams of the qualifying round will meet at the 24-hour finals held on April 22-23, 2017, in Katowice (Poland).
The teams can sign up until March 9, 2017 (23.59 CET). Registration is available on the contest website www.deadline24.pl.
You can get familiar with the type and difficulty level of the tasks in the Qualifying round by competing in the GYM contest on this Thursday and will last 5 hours (check your timezone here). It will be a replay contest of the Qualifying Round 2016. The contest will appear in Codeforces GYM soon. Because of technical limitations, the scoring and final ranking system of that replay contest is not identical to the one used during the qualifying round — don't forget to visit the contest website (www.deadline24.pl) to read full rules (e.g. submitting time matters and you submit output files instead of codes).
I'm not one of organizers but I competed in some of previous editions and I enjoyed finals a lot. Now I was asked to help a bit with the GYM replay. On behalf of the organizers, I want to thank Mike Mirzayanov for his help in promoting the competition on CF.
Don't forget that the registration ends on Thursday! Good luck in the qualifying round.
UPD: the GYM contest will start with the delay of 30 minutes. Sorry for the inconvenience.






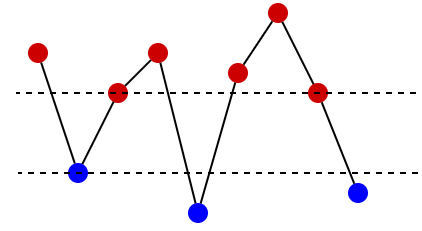
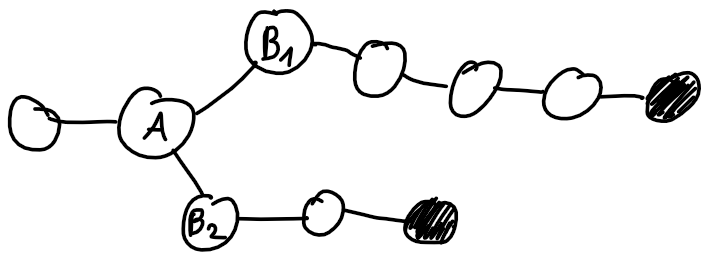
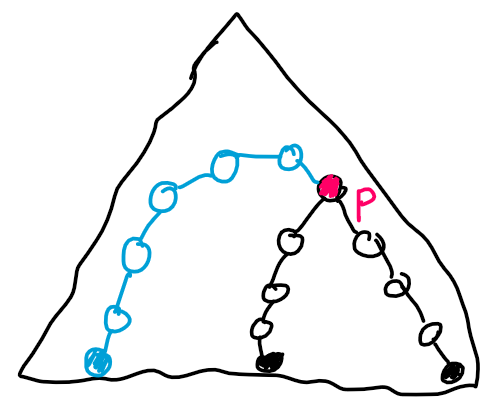
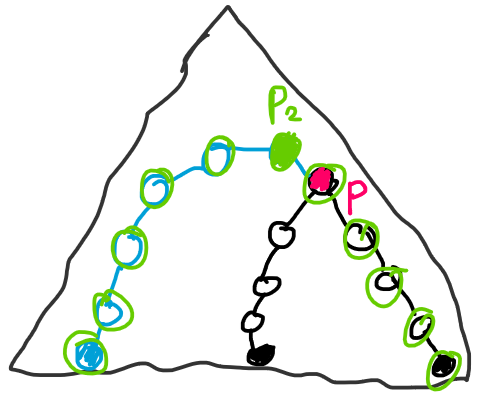
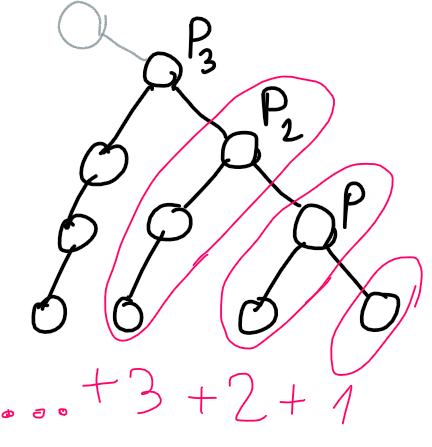
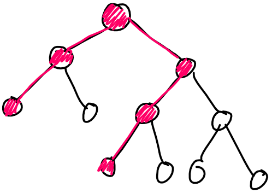
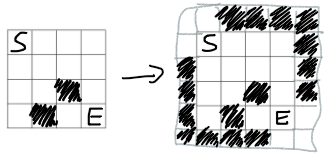
 . What should be stored in such a tree?
. What should be stored in such a tree?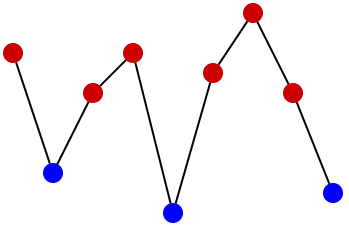
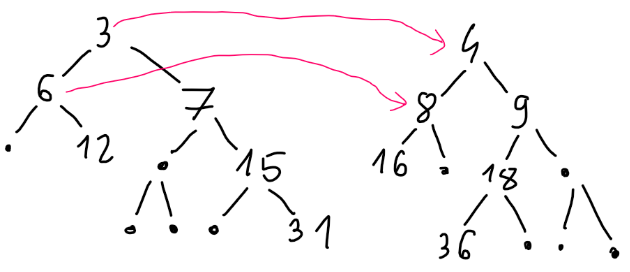
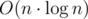 code in C++, with binary search:
code in C++, with binary search: 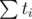 from the starting cell. That sum can't exceed
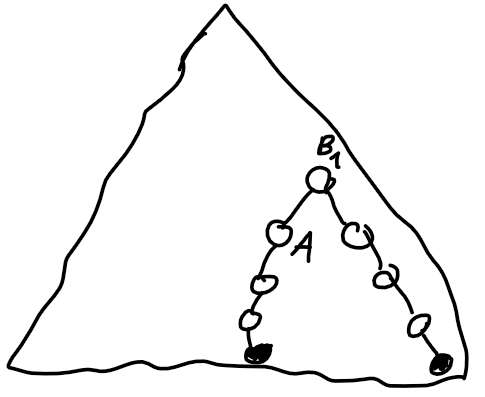
from the starting cell. That sum can't exceed 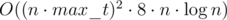 what is enough to get AC. It isn't hard to get rid of the logarithm factor what you can see in the last code below.
what is enough to get AC. It isn't hard to get rid of the logarithm factor what you can see in the last code below.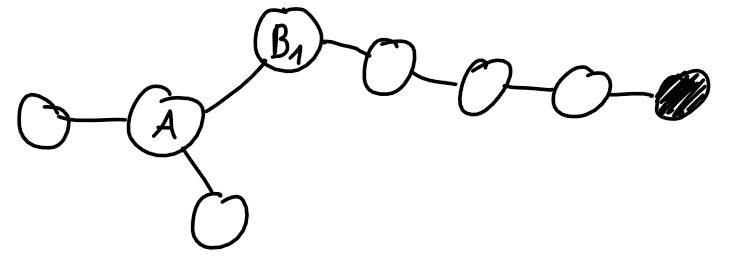
 . The limit from the statement is
. The limit from the statement is 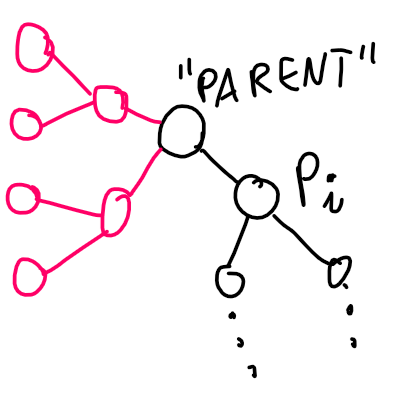
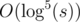 or better.
or better.
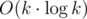 where
where 

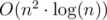 .
.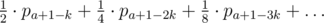 .
.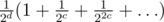 where
where 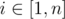 let's keep the distance to the next power of 42. After each "add on the interval" we should find the minimum and check if it's positive. If not then we should change value of the closest power of
let's keep the distance to the next power of 42. After each "add on the interval" we should find the minimum and check if it's positive. If not then we should change value of the closest power of 
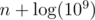 . Changing one coefficient affects up to
. Changing one coefficient affects up to 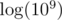 consecutive bits there and we want to get a sequence with only
consecutive bits there and we want to get a sequence with only 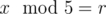 (and at the end we want at least
(and at the end we want at least 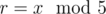 ). At the same time, we should keep people in
). At the same time, we should keep people in 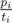 and it doesn't depend on a constant
and it doesn't depend on a constant 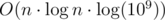 or faster. Can you solve the problem in linear time?
or faster. Can you solve the problem in linear time?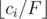 . Then, check if the max flow in this graph is at least
. Then, check if the max flow in this graph is at least 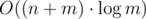 where
where 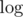 is from using set of forbidden edges.
is from using set of forbidden edges. but you could get AC with very fast solution with extra
but you could get AC with very fast solution with extra 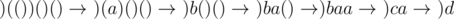
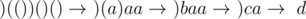


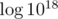 values to consider because we don't care about numbers much larger than
values to consider because we don't care about numbers much larger than  . The answer will be equal to the sum of values of
. The answer will be equal to the sum of values of  . Creating an additional array with prefix sums will allow us to calculate such a sum in
. Creating an additional array with prefix sums will allow us to calculate such a sum in 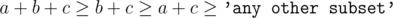 .
.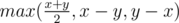 . The explanation isn't complicated. We can't be faster than
. The explanation isn't complicated. We can't be faster than 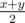 because we fight at most two criminals in each hour. And maybe e.g.
because we fight at most two criminals in each hour. And maybe e.g. 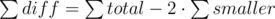 where every sum denotes the sum over
where every sum denotes the sum over 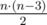 possible divisions.
possible divisions.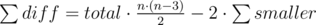
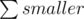 and then we will get
and then we will get 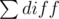 (this is what we're looking for).
(this is what we're looking for).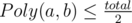 .
.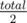 then we should increase
then we should increase 