


CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
21:01:59
Зарегистрироваться »
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |





It seems clear that one day, possibly in the near future, tourist won't be the only one at $$$4000+$$$ rating. I think that this raises a bigger issue, though: there are too many LGMs. Of course, this is just an opinion, but I don't think that the word "legendary" should be thrown around this often. For example, wrt chess, Magnus Carlsen and Bobby Fischer are legendary. Hikaru Nakamura is very very good, but he is not legendary. Also, I don't think anyone would consider the current world champion Ding Liren legendary.
To be honest, the only person on cf with true legendary status might be tourist. In fact, we can tell that he is the only legendary one because he has his own rank. If any of the other LGMs were legendary, they would also have their own rank (or something like that to signify true legendary status). So maybe $$$3000-3999$$$ should have a different name.
Hello everyone. I came up with this problem today (I'm not sure if it is original, but I really hope it is), and I am just wondering if it would be a good div. 2 A.
Problem statement:
You are given an array $$$a$$$ of distinct elements, and, because you like hygienic things, you want to sort it in ascending order. Unfortunately, you can't run a normal sorting algorithm on the array. In fact, you can only perform one type of operation that goes like this:
- You can reorder the array in any way you want. But one constraint must be satisfied: the reordered array must be different from what it was before. For example, the array $$$[1, 2, 3]$$$ can be reordered to $$$[1, 3, 2]$$$, but it cannot be reordered to $$$[1, 2, 3]$$$. Note that, in a string of operations, you can return to previous states of the array. For example, $$$[1, 2, 3] \implies [1, 3, 2] \implies [1, 2, 3]$$$ is valid.
Because sorting the array was too easy for you, you decide to challenge yourself by answering $$$n + 1$$$ queries. The $$$i^{th}$$$ query asks the question: can you sort the array $$$a$$$ in exactly $$$i - 1$$$ operations? Note that the queries are $$$1$$$-indexed.
Input:
The first line of each test contains one integer: $$$n$$$ $$$(2 \le n \le 2 \cdot 10^5)$$$, which denotes the length of the array. The next line contains $$$n$$$ space-separated integers $$$a_1, a_2, \cdots a_n$$$ $$$(1 \le a_i \le 10^9)$$$. All $$$a_i$$$ are pairwise distinct.
Output:
For each test, output $$$n + 1$$$ space-separated integers, the $$$i^{th}$$$ integer being the answer to the $$$i^{th}$$$ query. If the answer to the $$$i^{th}$$$ query is true, the $$$i^{th}$$$ integer is $$$1$$$. Otherwise, it is $$$0$$$.
For example, the answer to the array $$$1\,2\,3$$$ would be $$$1\,0\,1\,1$$$, because you cannot sort the array using $$$1$$$ operation, but you can sort it using $$$0, 2, 3$$$ operations.
I'd also appreciate some feedback if you have the time. If you saw this as a Div. 2 A, would you consider it a bad/average/good problem?
Problem statement:
Unfortunately, your time has come. You have just passed away, and you find yourself standing face to face with God. Since you were a decent person in your life, God decides to give you a choice. He presents you with two options.
Option 1: Your consciousness is destroyed forever. You won't be able to sense anything. You simply do not exist anymore.
Option 2: You roll a fair $$$1\,000$$$-sided die. On $$$999$$$ of the sides, the word heaven is written. On the remaining side, the word hell is written. If the die lands on heaven, you experience eternal bliss and euphoria. If the die lands on hell, you experience eternal torment.
Which option do you choose?
It looks like Rust doesn't have bitset in its std. Is there any alternative?
This problem: https://codeforces.me/contest/733/problem/E
is the exact same as this one: https://codeforces.me/contest/1936/problem/B
except the former one is like 8 years older than the latter one. The former one is rated $$$2400$$$, while the latter one is rated $$$2000$$$. Does this mean that a candidate master today would've been a grandmaster 8 years ago?
what if we just force them to stay in prison until they solve a super hard $$$3500$$$-rated codeforces IQ problem? Maybe the worst criminals would have to solve a $$$3500$$$-rated IQ problem, but the more tame ones would only have to do like a $$$3000$$$-rated problem. This could make it easier for smarter criminals to get out of prison so that they can continue contributing to society. For the most part, unfortunately, dumber criminals are pretty much a lost cause. Solving a $$$3500$$$-rated IQ problem is no easy task, of course. It might take years for the average criminal to solve one.
Hello everyone. If it took you a short time to implement C2 last contest, can you please share your solution? I'd really appreciate it.
Does anyone know how to approach this one?
You are given an undirected weighted graph $$$G$$$ that is not necessarily connected. In this weighted graph, there is a subset of nodes called highlighted nodes. It is guaranteed that the induced subgraph containing these highlighted nodes is connected.
You are also given $$$q$$$ queries. Each query consists of one integer that changes the status of the node corresponding to that integer. That is: if the node is highlighted, it becomes unhighlighted, and if it is unhighlighted, it becomes highlighted. After each query, it is guaranteed that the induced subgraph of highlighted nodes will always either be an empty graph or connected.
For each query, you must find the maximum length of a simple path having the following properties:
The path's length is at least $$$1$$$.
The first node in the simple path is a highlighted node.
There is only one highlighted node in the simple path.
For each query, print the answer on its own line. If there are no simple paths with these properties, print "N/A" (without the quotes) on its own line.
Input:
Each test begins with two integers $$$n,\,m$$$ $$$(1 \le n \le 10^5,\,1 \le m \le 2 \cdot 10^5)$$$: the number of nodes in $$$G$$$ and the number of edges in $$$G$$$ respectively.
The next $$$m$$$ lines contain three integers $$$u,\,v,\,w$$$ $$$(1 \le u \le n,\,1 \le v \le n,\,-1 \le w \le 10^9;\,w \ne 0)$$$, indicating that there is an edge with weight $$$w$$$ connecting $$$u$$$ and $$$v$$$. It is guaranteed that for every pair of vertices, there is at most $$$1$$$ edge connecting them. Furthermore, it is guaranteed that no self-loops exist.
The next line contains a single integer $$$h$$$: the number of highlighted nodes. On the line after that, $$$h$$$ integers follow $$$(1 \le h_i \le n)$$$ — the original highlighted nodes.
The next line contains a single integer $$$q$$$: the number of queries $$$(1 \le q \le 10^5)$$$. The next $$$q$$$ lines consist of a single integer $$$r$$$, which changes the status of node $$$r$$$. It is guaranteed that the induced subgraph containing the highlighted nodes is always either empty or connected.
Output:
For each query, print the length of the longest simple path with the properties above. If no such path exists, print "N/A" without the quotes.
For this problem: https://codeforces.me/contest/1981/problem/D, in the case where $$$m$$$ is even, why is it true that the longest path with unique edges (but not necessarily unique vertices) happens when you remove $$$\frac{m}{2} - 1$$$ edges? I get that there is then a Eulerian path in the graph because it has two nodes with an odd degree, but how can we be sure that there isn't a path with more unique edges in the original graph without any removals?
This was the first round where a "smart" AI could've potentially been used for solutions. Aside from a cheater or two, everyone seems to have performed normally. There weren't a trillion C-E solves.
This just goes to show that the AI is just another possibility for cheaters. Other possibilities include telegram servers with thousands of users and masters who livestream A-E on youtube for fun. Even if the AI were 3000-rated, I don't think that it would significantly impact competitive programming as we know it. Keep in mind that competitive programming as we know it does have some cheaters.
I was reading this: https://cp-algorithms.com/data_structures/segment_tree.html (segment tree) and I noticed something crazy. The create function is unnecessary. You can just call $$$n$$$ update functions. This could actually save 1-2 minutes of typing. Maybe even 10-20 minutes if the segment tree is especially weird.
Edit: okay, I see how this is not optimal. It looks like this would have a time complexity of $$$O(n \cdot log(n))$$$, while the normal creation method has a time complexity of $$$O(n)$$$.
Hello everyone. The reason for this blog is that I haven't seen much talk about solutions to this type of problem here, so I'd like to provide a basic introduction of it to this community.
Let's first look at the naive solution to this problem.
The naive solution to this problem for an array-like data structure $$$A$$$ is, for each element $$$A_i$$$, iterate through the entire data structure, and if you find an element $$$A_j$$$ satisfying $$$A_j < A_i$$$, move onto the next element $$$A_{i + 1}$$$. If you don't, you have your answer, $$$A_i$$$.
This is how one might implement such a solution in python:
Unfortunately, this works in $$$O(n^2)$$$ time. How can we optimize this? We can use dynamic programming.
For a $$$1$$$-indexed array-like data structure $$$A$$$ of length $$$n$$$, let's define $$$dp_i$$$ as the minimum element that appears in the substructure $$$A[i...n]$$$.
It is clear that the minimum element that appears in $$$A[n...n]$$$ is simply $$$A_n$$$. Therefore, our base case is $$$dp_{n} = A_n$$$. For indices $$$1...n - 1$$$, we can construct our answer using this recurrence relation: $$$dp_i = min(A_i, dp_{i + 1})$$$. It is clear that the answer to our problem is $$$dp_1$$$.
This works in $$$O(n)$$$ time and $$$O(n)$$$ space. A trick to reduce the space complexity is to notice that the recurrence relation doesn't need anything other than $$$dp_{i + 1}$$$ when calculating $$$dp_i$$$. Therefore, instead of creating a $$$dp$$$ array, we can simply update the value of $$$dp_{i + 1}$$$ using a variable.
Here is how you might implement this in python:
That is all. I hope you learned something!
I thought of this problem today, and since I don't really have much problem-creating experience, I would like to hear the opinions of experienced problem creators on whether or not it would be a good div. 2 A. Feel free to try it if you would like. I have added the solution.
Problem:
One day, $$$n$$$ people are made aware of the website codeforces.com. Let's call this day day $$$0$$$. The day after day $$$0$$$ is called day $$$1$$$, the day after that is day $$$2$$$, and so on. If you randomly select $$$1$$$ of these $$$n$$$ people, what is the expected value of the absolute difference between the day they were made aware of codeforces and the day they created a codeforces account? If the expected value is too big to fit inside a 32-bit integer, output $$$-1$$$.
Input:
The first line of each test, $$$t$$$, is the number of testcases $$$(0 \le t \le 10^3)$$$. Each testcase consists of a single integer, $$$n$$$ $$$(1 \le n \le 10^6)$$$.
Output:
For each testcase, print the expected value. It can be shown that if the expected value is less than the largest 32-bit integer, the expected value is an integer itself.
You are given an integer $$$n$$$. Let $$$S$$$ be the set of all strings of length $$$n$$$ that contain only lowercase Latin characters. So $$$S$$$ will have $$$26^n$$$ elements.
You pick a random string $$$s$$$ from set $$$S$$$, then you pick a random index $$$i$$$ from the range $$$[2, n]$$$. What is the expected value of $$$z_i$$$, where $$$z_i$$$ is the value of the $$$Z$$$-function of $$$s$$$ at index $$$i$$$?
What is your least favorite type of problem / least favorite topic? I personally do not like graph problems.
I was solving a problem when I accidentally found this weird feature in python:
list1 = [1]
list1.append(list1)
print(list1[1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][1][0])
You can append a list to itself. This code prints 1.
list1 = []
list1.append(list1)
print(list1[0][0][0][0][0][0])
This will print [[...]]. I guess it prints this to show that the list tunnels on forever.
It makes sense but it still seems like an odd feature. I can't see how this would be useful.
A master, as you probably know, is someone in the 2100-2299 rating range. I believe that I have made a pretty accurate estimation of the average IQ of a master, but I would like to hear CF users' thoughts on this. The wisdom of the crowd usually trumps the guesses of any individual person.
So please, add a thumbs up to the range in which you believe the average IQ of a master falls under.
IQ range:
For reference, the IQ score percentiles are roughly:
$$$100 = 50$$$
$$$110 \approx 75$$$
$$$120 \approx 91$$$
$$$130 \approx 98$$$
$$$140 \approx 99.5$$$
$$$150 \approx 99.95$$$
Hello. I can't seem to figure out this problem's solution. I've read the editorial and I understand the first part but when the author says:
"To further optimize this solution, another transformation is needed. Ideally, we would like each ai to contribute to the answer independently of other values. And this can almost be achieved. Notice that the maximum returns 0 only if ai<ai−1 for any k, not just for k=1. This may require proof, but it is quite obvious."
I just don't get what this means. I also don't know what he's tryna do with the ci coefficient. I'd really appreciate it if someone here could explain it to me.

Hello everyone,
I have updated the rating distribution histogram for this year and I have created rating percentiles so you can find out how you compare against other active users. I define an active user as a user who has 1) participated in the last 6 months and 2) participated in at least 6 contests. The second condition is to ensure that the user's rating is stabilized.
Here is the chart (n = 89352): 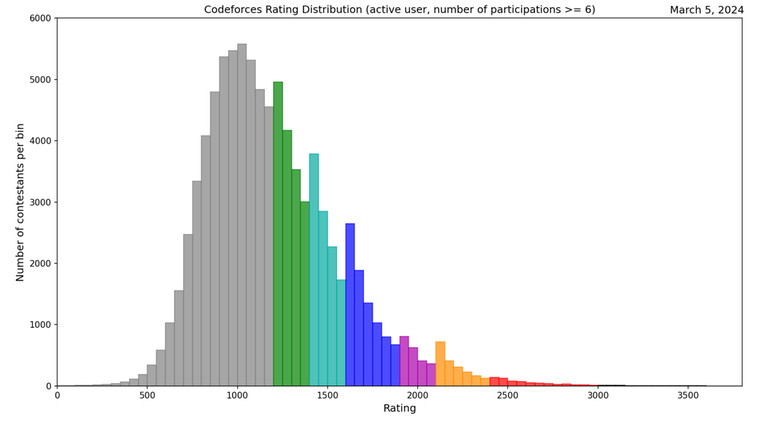
{kind=link}
And here are some previous years' histograms: 2023 note: uses >= 5 contest participations instead of >= 6 participations. 2021 note: the author of this post wrote the script that creates very nice histograms so credit to him.
Some interesting facts:
The median Codeforces rating is 1143. The mean rounded to the nearest integer is 1205. The standard deviation is 378 rounded down to the nearest integer.
A rating of 1900 places you at the 94th percentile.
A rating of 2400 places you at the 99.2nd percentile.
The minimum rating for an LGM, 3000, is at the 99.93rd percentile.
55% of Codeforces users are gray.
If you want to see an exact rating percentile, go here.
If you want to see the rating data, go here. The data is in python dictionary format.
That is all, I hope this was interesting.
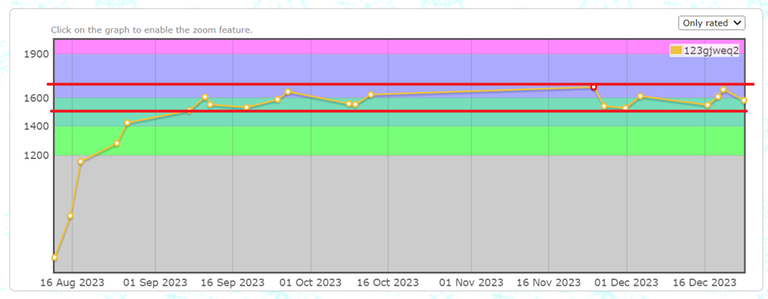
My rating is remarkably stable. I bet you wish you were me with how stable my rating is. I was worried for a second that I might accidentally improve in the recent pinely contest, but thankfully I couldn't solve C and luckily for me my rating converged right under expert: the place where it is meant to stay forever.
My personal favorite has got to be tries. Almost every problem out there can be solved using some variation of a trie, which is why they are so cool. It feels like everything in programming, in one way or another, is, in an abstract sense, a trie.
