


Hint: When does some vowel stay in string?
Iterate over the string, output only consonants and vowels which don't have a vowel before them.
Hint 1: It's never profitable to go back. No prizes left where you have already gone.
Hint 2: The optimal collecting order will be: some prefix of prizes to you and the other prizes to your friend (some suffix).
You can find the total time with the knowledge of the prefix length. The final formula is 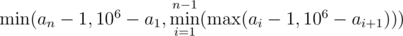 .
.
Hint: At first we will solve the problem mentioned in the statement. The formula is 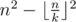 . Firstly, each submatrix k × k should have at least one row with zero in it. Exactly
. Firstly, each submatrix k × k should have at least one row with zero in it. Exactly 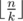 non-intersecting submatrices fit in matrix n × k. The same with the columns. So you should have at least this amount squared zeros.
non-intersecting submatrices fit in matrix n × k. The same with the columns. So you should have at least this amount squared zeros.
Now that you know the formula, you can iterate over n and find the correct value. The lowest non-zero value you can get for some n is having k = 2. So you can estimate n as about 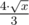 .
.
Now let's get k for some fixed n. 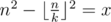

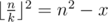
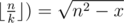
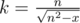 . Due to rounding down, it's enough to check only this value of k.
. Due to rounding down, it's enough to check only this value of k.
The function of the path length is not that different from the usual one. You can multiply edge weights by two and run Dijkstra in the following manner. Set disti = ai for all 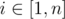 and push these values to heap. When finished, disti will be equal to the shortest path.
and push these values to heap. When finished, disti will be equal to the shortest path.
Hint 1: Count the number of times each number appears in the sum of all fa.
Hint 2: Try to find a sufficient and necessary condition that ai appears in fa of a permutation.
Hint 3: Prove that ai appears if and only if all elements appearing before it are strictly less than it (other than the largest element). And then try to solve the problem first in O(n2).
Now try to solve to simplify your solution with O(n2).
It is easy to see that i-th element appears in fa if and only if all elements appearing before it in the array are less than it, so if we define li as the number of elements less than ai the answer will be equal to:
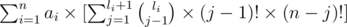
By determining the index of ai, if it is on the index j then we have to choose j - 1 of the li elements smaller than it and then permuting them and then permuting the other elements. We can find all li with complexity of O(n log n). If we were to implement this, the complexity would equal to O(n2).
Now let's make our formula better. So let's open it like so:
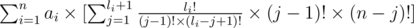
and then it equals to:
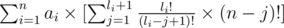
and now let's take out the li! ,
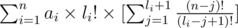
now let's multiply the inside the first sigma by 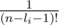 and the second sigma by (n - li - 1)! and it gets equal to:
and the second sigma by (n - li - 1)! and it gets equal to:
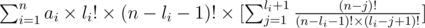
and it is easy to see it equals to:
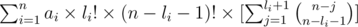
and using the fact that
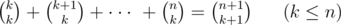
it will equal to:
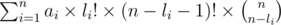
So the final answer will equal to:
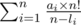
of which can be easily implemented in O(n log n). Make sure to not add the answer for maximum number in the sequence.
There is also another solution that you can read here \url{http://codeforces.me/blog/entry/57783?#comment-414657}.
Let's denote n = |s|.
Hint: There is a simple 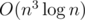 solution: dp[m][mask] — best answer if we considered first m characters of the string and a mask of erased substrings. However, storing a string as a result of each state won't fit neither into time limit nor into memory limit. Can we make it faster?
solution: dp[m][mask] — best answer if we considered first m characters of the string and a mask of erased substrings. However, storing a string as a result of each state won't fit neither into time limit nor into memory limit. Can we make it faster?
Let's try to apply some greedy observations. Since each state represents a possible prefix of the resulting string, then among two states dp[m1][mask1] and dp[m2][mask2] such that the lenghts of corresponding prefixes are equal, but the best answers for states are not equal, we don't have to consider the state with lexicographically greater answer. So actually for every length of prefix there exists only one best prefix we will get, and we may store a boolean in each state instead of a string. The boolean will denote if it is possible to get to corresponding state with minimum possible prefix.
To calculate this, we iterate on the lengths of prefixes of the resulting string. When we fix the length of prefix, we firstly consider dynamic programming transitions that denote deleting a substring (since they don't add any character). Then among all states dp[m][mask] that allow us to reach some fixed length of prefix and have dp[m][mask] = true we pick the best character we can use to proceed to next prefix (and for a fixed state that's actually (m + 1)-th character of the string).
This is  , but in fact it's pretty fast.
, but in fact it's pretty fast.
This is a more complex version of problem G from Educational Round 27. You can find its editorial here.
To solve the problem we consider now, you have to use a technique known as dynamic connectivity. Let's build a segment tree over queries: each vertex of the segment tree will contain a list of all edges existing in the graph on the corresponding segment of queries. If some edge exists from query l to query r, then it's like an addition operation on segment [l, r] in segment tree (but instead of addition, we insert this edge into the list of edges on a segment, and we make no pushes). Then if we write some data structure that will allow to add an edge and rollback operations we applied to the structure, then we will be able to solve the problem by DFS on segment tree: when we enter a vertex, we add all edges in the list of this vertex; when we are in a leaf, we calculate the required answer for the corresponding moment of time; and when we leave a vertex, we rollback all changes we made there.
What data structure do we need? Firstly, we will have to use DSU maintaining the distance to the leader (to maintain the length of \textit{some} path between two vertices). Don't use path compression, this won't work well since we have to do rollbacks.
Secondly, we have to maintain the base of all cycles in the graph (since the graph is always connected, it doesn't matter that some cycles may be unreachable: by the time we get to leaves of the segment tree, these cycles will become reachable, so there's no need to store a separate base for each component). A convenient way to store the base is to make an array of 30 elements, initially filled with zeroes (we denote this array as a). i-th element of the array will denote some number in a base such that i-th bit is largest in the number. Adding some number x to this base is really easy: we iterate on bits from 29-th to 0-th, and if some bit j is equal to 1 in x, and a[j] ≠ 0, then we just set 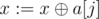 (let's call this process \textit{reduction}, we will need it later). If we get 0 after doing these operations, then the number we tried to add won't affect the base, and we don't need to do anything; otherwise, let k be the highmost bit equal to 1 in x, and then we set a[k]: = x.
(let's call this process \textit{reduction}, we will need it later). If we get 0 after doing these operations, then the number we tried to add won't affect the base, and we don't need to do anything; otherwise, let k be the highmost bit equal to 1 in x, and then we set a[k]: = x.
This method of handling the base of cycles also allows us to answer queries of type 3 easily: firstly, we pick the length of some path from DSU (let it be p), and secondly, we just apply \textit{reduction} to p, and this will be our answer.


