


It is known (well, as long as Tarjan's proof is correct, and it is believed to be) that DSU with path compression and rank heuristics works in O(α(n)), where α(n) is an inverse Ackermann function. However, there is a rumor in the community that if you do not use the rank heuristic than the DSU runs as fast, if not faster. For years it was a controversial topic. I remember some holywars on CF with ones arguing for a random heuristic and others claiming they have a counter-test where DSU runs in 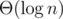 independently of rand() calls.
independently of rand() calls.
Recently I was looking through the proceedings of SODA (a conference on Computer Science) and found a paper by Tarjan et al. The abstract states:
Recent experiments suggest that in practice, a naïve linking method works just as well if not better than linking by rank, in spite of being theoretically inferior. How can this be? We prove that randomized linking is asymptotically as efficient as linking by rank. This result provides theory that matches the experiments, which implicitly do randomized linking as a result of the way the input instances are generated.
This paper is relatively old (2014), though I haven't yet heard of it and decided to share with you.
A whole paper can be found here.


