


1898B - Milica and String
Author: n0sk1ll
In one move, Milica can replace the whole string with $$$\texttt{AA} \ldots \texttt{A}$$$. In her second move, she can replace a prefix of length $$$k$$$ with $$$\texttt{BB} \ldots \texttt{B}$$$. The process takes no more than $$$2$$$ operations. The question remains — when can we do better?
In the hint section, we showed that the minimum number of operations is $$$0$$$, $$$1$$$, or $$$2$$$. We have $$$3$$$ cases:
No operations are needed if $$$s$$$ already contains $$$k$$$ characters $$$\texttt{B}$$$.
Else, we can use brute force to check if changing some prefix leads to $$$s$$$ having $$$k$$$ $$$\texttt{B}$$$s. If we find such a prefix, we print it as the answer, and use only one operation. There are $$$O(n)$$$ possibilities. Implementing them takes $$$O(n)$$$ or $$$O(n^2)$$$ time.
Else, we use the two operations described in the hint section.
A fun fact is that only one operation is enough. Can you prove it?
1898B - Милена и поклонник
Author: OutrunMyGun & n0sk1ll
Try a greedy approach. That is, split each $$$a_i$$$ only as many times as necessary (and try to create almost equal parts).
We will iterate over the array from right to left. Then, as described in the hint section, we will split the current $$$a_i$$$ and create almost equal parts. For example, $$$5$$$ split into three parts forms the subarray $$$[1,2,2]$$$. Splitting $$$8$$$ into four parts forms the subarray $$$[2,2,2,2]$$$. Notice that the subarrays must be sorted. Because we want to perform as few splits as possible, the rightmost endpoint value should be as high as possible (as long as it is lower than or equal to the leftmost endpoint of the splitting of $$$a_{i+1}$$$ if it exists).
When we iterate over the array, it is enough to set the current $$$a_i$$$ to the leftmost endpoint of the splitting (the smallest current value). It will help to calculate the optimal splitting of $$$a_{i-1}$$$. For the current $$$a_i$$$, we want to find the least $$$k$$$ such that we can split $$$a_{i-1}$$$ into $$$k$$$ parts so the rightmost endpoint is less than or equal to $$$a_i$$$. More formally, we want $$$\lceil \frac{a_{i-1}}{k} \rceil \leq a_i$$$ to hold. Afterwards, we set $$$a_{i-1}$$$ to $$$\lfloor \frac{a_{i-1}}{k} \rfloor$$$ and continue with our algorithm. The simplest way to find the desired $$$k$$$ is to apply the following formula:
The answer is the sum over all $$$k-1$$$.
There are $$$q \leq 2\cdot 10^5$$$ queries: given an index $$$i$$$ and an integer $$$x>1$$$, set $$$a_i := \lceil \frac{a_i}{x} \rceil$$$. Modify the array and print the answer to the original problem. Please note that the queries stack.
1898C - Разноцветная сетка
Author: n0sk1ll
The solution does not exist only for "small" $$$k$$$ or when $$$n+m-k$$$ is an odd integer. Try to find a construction otherwise.
Read the hint for the condition of the solution's existence. We present a single construction that solves the problem for each valid $$$k$$$.
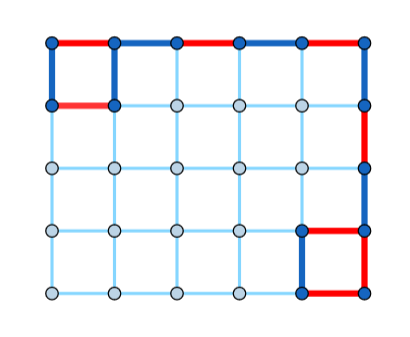
One can verify that the pattern holds in general.
How would you write a checker? That is, how would you check that a valid walk of length $$$k+1$$$ exists in the given grid (with all the edges colored beforehand)?
1898D - Абсолютная красота
Author: n0sk1ll
If $$$a_i > b_i$$$, swap them. Imagine the pairs $$$(a_i,b_i)$$$ as intervals. How can we visualize the problem?
The pair $$$(a_i,b_i)$$$ represents some interval, and $$$|a_i - b_i|$$$ is its length. Let us try to maximize the sum of the intervals' lengths. We present three cases of what a swap does to two arbitrary intervals.



Notice how the sum of the lengths increases only in the first case. We want the distance between the first interval's right endpoint and the second interval's left endpoint to be as large as possible. So we choose integers $$$i$$$ and $$$j$$$ such that $$$i \neq j$$$ and $$$a_j - b_i$$$ is maximized. We add twice the value, if it is positive, to the original absolute beauty. If the value is $$$0$$$ or negative, we simply do nothing.
To quickly find the maximum of $$$a_j - b_i$$$ over all $$$i$$$ and $$$j$$$, we find the maximum of $$$a_1,a_2,\ldots a_n$$$ and the minimum of $$$b_1,b_2, \ldots b_n$$$. Subtracting the two extremum values produces the desired result.
How to handle point updates? (change a single value in either $$$a$$$ or $$$b$$$, and print the answer after each query.)
1898E - София и строки
Author: OutrunMyGun
Notice how sorting only the substrings of length $$$2$$$ is enough. Try a greedy approach.
We sort only the substrings of length $$$2$$$. We can swap two adjacent characters if the first is greater than or equal to the second. Let us fix some character $$$s_i$$$ and presume we want to change its position to $$$j$$$. We have to perform the described swaps if they are possible. More formally:
- if $$$j<i$$$, then every character in the segment $$$s_j s_{j+1} \ldots s_{i-1}$$$ must be greater than or equal to $$$s_i$$$;
- if $$$i<j$$$, then every character in the segment $$$s_{i+1} s_{i+2} \ldots s_j$$$ must be smaller than or equal to $$$s_i$$$.
We want to reorder the string $$$s$$$ and get the string $$$s'$$$. Then, we check if we can delete some characters in $$$s'$$$ to achieve $$$t$$$. In other words, we want $$$t$$$ to be a subsequence of $$$s'$$$. A general algorithm that checks if the string $$$a$$$ is a subsequence of the string $$$b$$$ is as follows. We iterate through $$$a$$$, and for each character, we find its first next appearance in $$$b$$$. If such a character does not exist, we conclude that $$$a$$$ is not a subsequence of $$$b$$$. If we complete the iteration gracefully, then $$$a$$$ is a subsequence of $$$b$$$. We will try to check if $$$t$$$ is a subsequence of $$$s$$$, but we allow ourselves to modify $$$s$$$ along the way.
We maintain $$$26$$$ queues for positions of each lowercase English letter in the string $$$s$$$. We iterate through the string $$$t$$$, and for every character $$$t_i$$$, we try to move the first available equivalent character in $$$s$$$ to position $$$i$$$. In other words, at every moment, the prefix of string $$$s$$$ is equal to the prefix of string $$$t$$$ (if possible). For the current character $$$t_i$$$ and the corresponding $$$s_j$$$, prefixes $$$t_1t_2\dots t_{i-1}$$$ and $$$s_1s_2\dots s_{i-1}$$$ are the same, which means that $$$j\geq i$$$. To move $$$s_j$$$ to position $$$i$$$, we need to delete all characters between $$$s_i$$$ and $$$s_j$$$ that are smaller than $$$s_j$$$. We will delete them and all characters from the current prefix $$$s_1s_2\dots s_{i-1}$$$ from the queues because they are no longer candidates for $$$s_j$$$. By doing so, $$$s_j$$$ will be the first character in the corresponding queue. If at some moment in our greedy algorithm, the queue we are looking for becomes empty, then the answer is "NO". Otherwise, we will make the prefix $$$s_1s_2\dots s_m$$$ equal to the $$$t$$$ and delete the remaining characters from $$$s$$$.
Why is this greedy approach optimal? Let's suppose for some character $$$t_{i_1}$$$ we chose $$$s_{j_1}$$$ and for $$$t_{i_2}$$$ we chose $$$s_{j_2}$$$, such that $$$i_1< i_2$$$, $$$j_1>j_2$$$ and $$$t_{i_1}=t_{i_2}=s_{j_1}=s_{j_2}$$$. We need to prove that if we can move $$$s_{j_1}$$$ to position $$$i_1$$$ and $$$t_{i_2}$$$ to position $$$i_2$$$, when we can move $$$s_{j_2}$$$ to $$$i_1$$$ and $$$s_{j_1}$$$ to $$$i_2$$$. In the moment when we chose $$$s_{j_1}$$$, prefixes $$$t_1t_2\dots t_{i_1-1}$$$ and $$$s_1s_2\dots s_{i_1-1}$$$ are the same, so $$$j_1\geq i_1$$$. Similarly, $$$j_2\geq i_2$$$, which means the only possibility is $$$i_1<i_2\leq j_2<j_1$$$.
If we can move $$$s_{j_1}$$$ to position $$$i_1$$$, than we can also move $$$s_{j_2}$$$ to $$$i_1$$$ because $$$s_{j_1}=s_{j_2}$$$ and $$$j_2<j_1$$$. Also, if we can move $$$s_{j_1}$$$ to $$$i_1$$$, than we can move $$$s_{j_1}$$$ to $$$i_2$$$ because $$$i_1<i_2$$$, from which it follows that we can move $$$s_{j_2}$$$ to $$$i_2$$$, because $$$s_{j_2}=s_{j_1}$$$ and $$$j_2<j_1$$$.
The overall complexity is $$$O(\alpha \cdot (n+m))$$$, where $$$\alpha$$$ is the alphabet size ($$$\alpha=26$$$ in this problem).
Solve the problem when the size of the alphabet is arbitrary (up to $$$n$$$).
1898F - Вова и побег из матрицы
Author: n0sk1ll
To solve the problem for matrices of $$$3$$$-rd type, find the shortest path to $$$2$$$ closest exits with a modification of BFS. Block all cells not belonging to the path with obstacles.
For a matrix of type $$$1$$$, Misha can block all empty cells (except the one Vova stands on).
For a matrix of type $$$2$$$, Misha finds the shortest path to some exit with a single BFS and then blocks every other cell.
Matrices of type $$$3$$$ are more complicated. We want to find two shortest paths to the two closest exits and block the remaining empty cells.
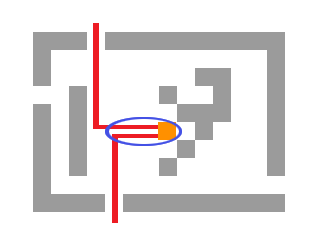
But, notice how the paths will likely share their beginnings. We do not have to count those cells twice. Let's take a look at the junction where the two paths merge. If we first fix the junction, finding the shortest path to Vova can be done by running a single BFS and precalculating the shortest distances from each cell to Vova. Finding the shortest path from the junction to the two closest exits can also be done with BFS and precalculation. We modify the BFS, making it multi-source, with a source in each exit. Also, we will allow each cell to be visited twice (but by different exits). We will need to maintain the following data for each cell:
- How many times was it visited;
- The last exit/source that visited it;
- The sum of paths from all exits/sources that visited the cell so far.
Running the BFS with proper implementation produces the answer. When everything said is precalculated, we fix the junction in $$$O(nm)$$$ ways (each empty cell can be a valid junction), and then calculate the shortest path from Vova to the two closest cells in $$$O(1)$$$ per junction.
Total complexity is $$$O(nm)$$$.
Solve the problem with LCA, or report that such a solution does not exist.

