


Привет, Codeforces!
В 04.06.2021 17:35 (Московское время) состоится Educational Codeforces Round 110 (рейтинговый для Див. 2).
Продолжается серия образовательных раундов в рамках инициативы Harbour.Space University! Подробности о сотрудничестве Harbour.Space University и Codeforces можно прочитать в посте.
Этот раунд будет рейтинговым для участников с рейтингом менее 2100. Соревнование будет проводиться по немного расширенным правилам ICPC. Штраф за каждую неверную посылку до посылки, являющейся полным решением, равен 10 минутам. После окончания раунда будет период времени длительностью в 12 часов, в течение которого вы можете попробовать взломать абсолютно любое решение (в том числе свое). Причем исходный код будет предоставлен не только для чтения, но и для копирования.
Вам будет предложено 6 или 7 задач на 2 часа. Мы надеемся, что вам они покажутся интересными.
Задачи вместе со мной придумывали и готовили Роман Roms Глазов, Адилбек adedalic Далабаев, Владимир vovuh Петров, Иван BledDest Андросов и Максим Neon Мещеряков. Также большое спасибо Михаилу MikeMirzayanov Мирзаянову за системы Polygon и Codeforces.
Удачи в раунде! Успешных решений!
Также от наших друзей и партнёров из Harbour.Space есть сообщение для вас:

Привет, Codeforces!
Пришло время для еще одной захватывающей возможности — стипендии от Harbour.Space!
Если вы любите технологии, любите творить и ищете сферу, где возможна увлекательная карьера, фронт-энд разработка может быть для вас! На этот раз мы разыскиваем талантливых людей для запуска нашей новой программы.
Мы предлагаем 50% стипендию для получения степени бакалавра и магистра, тем самым открывая двери в увлекательный мир информационных технологий для самых одаренных.
Требования:
- Диплом (и приложение с перечнем изученных предметов) о наивысшем достигнутом уровне образования
- Свободное владение английским языком
- Ваш CV
Что вы узнаете:
- Кодирование в соответствии с отраслевыми стандартами
- Ускоренное обучение
- Освоите новые технологии
- Фреймворки JavaScript, препроцессоры и методологии CSS, а также визуальный дизайн
- И многое другое
Не забудьте подать заявку до 30 июня 2021 года, чтобы получить стипендию и снизить плату за подачу заявления.
Некоторые преимущества обучения в Harbour.Space
- Мы меняем способ обучения
- Мы учимся на практике
- Мы ваш новый дом
Мы всегда рады видеть членов сообщества Codeforces, которые присоединяются к семье Harbour.Space. Подайте заявку сейчас, чтобы получить шанс учиться у лучших в этой области и начать свою карьеру!
Следите за новостями в LinkedIn, чтобы не упустить новые возможности. А так же загляните в наш Instagram, где мы делимся событиями студенческой жизни и историями успеха наших учеников.
Удачи в вашем раунде и до встречи в следующий раз!
Harbour.Space University
Поздравляем победителей:
| Место | Участник | Задач решено | Штраф |
|---|---|---|---|
| 1 | SSRS_ | 6 | 118 |
| 2 | Maksim1744 | 6 | 137 |
| 3 | Geothermal | 6 | 147 |
| 4 | neal | 6 | 154 |
| 5 | Ormlis | 6 | 167 |
Поздравляем лучших взломщиков:
| Место | Участник | Число взломов |
|---|---|---|
| 1 | Kawaii | 51:-7 |
| 2 | coder_ym_ | 28:-3 |
| 3 | meyi | 27:-4 |
| 4 | DespicableMonkey | 21 |
| 5 | DevilAeron | 20:-5 |
И, наконец, поздравляем людей, отправивших первое полное решение по задаче:
| Задача | Участник | Штраф |
|---|---|---|
| A | Geothermal | 0:00 |
| B | neal | 0:02 |
| C | Geothermal | 0:05 |
| D | SSRS_ | 0:12 |
| E | _runtimeTerror_ | 0:18 |
| F | xay5421 | 1:01 |
UPD: Разбор опубликован






Good Luck Everyone!!!
awoo i think there is a mistake in the announcement :
problemsbugaboosIs that Russian of problems?
bugaboos are bugaboos
bugaboos are in Canada!
Another BledDest Round !
Waiting for a nice BUGABOOSET !
Finally, there is a contest after a long time. Wishing good luck to everyone <3.
All the best everyone, will try to solve atleast 2 problems this time.
You won't be able to solve any problems. Because there will only be bugaboos to solve, I guess.
Hey man what is bugaboos??
can any one tell me why problems had becomes bugaboos
Found this: https://codeforces.me/blog/entry/91134
thanks bro
I never Imagined I would say this in my life I wish I can reach pupil XD XD XD
Wait till LTDT hears this lmao
it's just a joke I'm not serious I will overcome this
you got it! congrats
Wait till the system testing ends I have bad memories of being happy before it XD .. but anyway I'm still aiming for way more
i hope i can get top 10 in this contest
Good luck to everyone!
how many announcements would you like to do?
(authors): YES
meme king indeed!! getting meme ideas mid contest
<3
https://www.youtube.com/watch?v=REOoXnMaeZQ:
This guy is literally live-streaming solving the contest, while broadcasting the code. I didn't watch for long enough to get the codeforces handle, but this needs to be stopped. Perhaps this contest needs to be unrated?
EDIT: His handle is rebel_roar
live-streaming? More like live-embarrasing-himself
That dude streaming be like -
Petition to make all CF rounds unrated cause someone cheats anyways.
So if I perform bad in a contest, I can just go live stream and the contest will become unrated?
Though his livestream is very informative.
About what not to do in cp.
Is E binary lifting? I think I coded O(QlogQ) but TLE
Edit: nvm I was one edit distance from AC, original code was wrong. Messed up the definitions of A and C.
I was thinking of binary lifting too... but how do you find which ancestor node to start taking gold from?
The farthest ancestor with gold>0
So the solution is, since c[i] > c[p[i]], the optimal strategy is to always take every possible ton of gold from the top node on the path. If all the gold of one node is taken, then all the ancestors of it and itself would never involve in any other gold-taking queries. Therefore you need to jump to the node with minimum dep such that there is still gold in it.
Consider one chain starting from the root and going down. The top node of every query type 2 monotonically goes down, therefore complexity is O(QlogQ).
sahaun hope this helps.
OH OH OH, I know now!
Thanks! Also thanks to sharath101 for the solution which cleared it up for me.
But how to update the nodes at the beginning of each path to zero in an efficient manner?
I don't understand your question.
If you are at some node v, the amount of gold you can take is take = min(A[v], w), just A[v]-=take?
Hi, Suppose we have path = (1, 2, 3, 4, 5) where root = 1 and tons a = (1, 1, 1, 1, 1) for each vertex in this path. If we need to get 4 tons, we must set to 0 all a_i for i=1..4 instead of a_v -= 4. I'm not sure.
Oh, just do them one by one.
But in this case we don't need binary lifting, We just go from root to a node until we get all w.
No, if for every query you start from the root you will have O(query type 2×depth) complexity, and the depth can be O(query type 1) so it is O(Q^2).
That's why you need binary lifting to find the uppermost nonzero node on the path. This node always goes downwards so it works.
ok, but binary lifting will not reduce the complexity of query type 1 for node v. It will continue at O(nq) or O(q^2) because after find the node u in the path p(r,v) at O(log n) we need to do a linear visit O(n) on each vertex from u to v. But is ok and thank you for your answers.
No it is not O(nq). The top node continuously goes down, and the node you end at for some query is the top node for the next query(on this path). So the traversing part is O(Q).
I did it using binary lifting. Essentially for each query, I lifted to the farthest ancestor with gold>0 and kept doing it until I reach the required gold. Since a node gets lifted to only once, complexity would be O(QlogQ). AC in 1.6s
Could you please elaborate ? How to find the nodes which have the minium cost per ton until W_i gold are taken ? as the cost can be minimum in the lower nodes also right ?
According to the question, a node will always have lesser cost than its child. So we consider looking at the farthest ancestor first.
Oh! Yeah. My bad, I read it but then after reading the question I totally forgot it. Thanks.
I have used the same approach but I am getting TLE by this https://codeforces.me/contest/1535/submission/118481202
I feel you, also got my AC 8 minutes after the contest, since I didn't manage the binary lifting in time :( (So yes, binary lifting worked for me)
Im dumb, C is not hard
No offence but C was not properly written.
which line you were confused in ?
They say the string is beautiful if it contains 0. 1. and ?. On the other hand is 0? is an example of beautiful string and it doesn't contain 1. It is confusing for at least me, don't know about others. They could've written 0, 1, or ?
No, they say the string is beautiful if it consists of 0, 1 and ?.
e.g. see https://math.stackexchange.com/questions/271991/exact-meaning-of-consists-of
Okay but it is still the same thing. it consists of 0, 1 and ? implies that it consists of every character that is mentioned.
No, it does not imply that
"Let a_n be an arithmetic progression of length 3 consisting of prime numbers", does not imply that a_n contains every single prime number
but this means every a_n is a prime number which is similar to what i said.
It consists of 0, 1 and ? means that the string would have atleast one 0, one 1, and one ?. I understand it this way. So many announcements in between contest means its not only me who didn't understand it rather many people understood it different way. That doesn't change the fact that it was poorly written and explained.
The standard meaning of "A consists of Bs" is that every element of A is a B. I've never seen it used to imply that every B appears in A.
Okay, maybe I'm salty because i couldn't solve it. I'll try to read problems better from next time.
But that's the thing. If so many people have to search up the definition to understand what it means, it should be restated.
On the other hand, they could have explained the sample test cases to clear it up faster than with the announcements.
You should have checked example ??? in test case .
I perceived it in a way that each question mark will be a 1 or 0 for whole string and not that it can differ for each substring . My bad, but a test case where they would have explained such scenario would have suerly helped.
I don't agree, I found of the 2 custom definitions (unstable, beautiful) quite precise.
In fact I got quite annoyed at the announcements, e.g. 'Strings "0" and "1" are unstable.', well this follows from the definition since there are no adjacent characters...
The authors made more than enough announcements imo, let's not play blame-game after each contest. :')
Was E a standard problem? I couldn't think of an approach, but it felt pretty standard.
I was seeing like basically it was something that trees was getting split, as we can avoid the one that had already become zero, but was having no clue on how to pass the information of this least non-zero ancestor easily to its subtree child. I thought going with dsu, but again processing was to be done in online way, so got no way :(
I had the same idea and was thinking along the lines of LCA. But there is a chance that root is non zero but I encounter some ancestor that is zero, while binary lifting.
If a node's value is 0 then all its ancestors must also be 0. So binary lifting works just fine.
After binary lifting do we just run a dfs?
We can use the ancestor data to visit each nonzero ancestor in descending order, subtracting gold from each one until we satisfy the query or exhaust all nodes on the path.
https://codeforces.me/contest/1535/submission/118439439 Can someone tell me why this is giving WA ?
That C was a headache. Looking at the submissions seems like there is a greedy 5 liner somewhere. Managed to do it using some weird 3d dp. If anyone is interested.
...
It was pretty easy. You just need to iterate over two cases
10101...and01010.... Then just remove overcounted blocks of????....Thanks for letting me sleep in peace knowing the solution.
can u explain why u have subtracted the count of "????..." from the ans?
they were counted twice...once in 10101 and once in 010101
Think simple yet elegant
I managed to do it using 2d DP, there's a special case for question marks though
I did the same as you for the dp.
However, for the ans, you just need to do the following: for(int i = 0; i< n; i++) ans += max(dp[i][0], dp[i][1]);
Yes correct, because whatever you count in minimum will be included in maximum. So just take contribution of maximum.
why taking max(dp[i][0], dp[i][1]) works?? can u pls explain??
dp[i][j] means: if the i-character is set to j, the maximum number of characters we can take before i(including i), such that this substring is beautiful. In other words, the (i — dp[i][j] + 1)-th to the i-th character is the maximum substring ending at i with S[i] set to j.
We are taking max because '?' can be set to either '1' or '0'.
The formula should be evident now.
It helped..thanks a lot man
Also we can just do ans += max(dp[i][0], dp[i][1])
why taking max(dp[i][0], dp[i][1]) works?? can u pls explain??
Because DPij means the number of good substrings which end at position i if we place in j (0 or 1). So we only care about maximum of these values, because all you count in minimum will be included in maximum.
I used two pointers lol. Just have two arrays, one for the occurrences of each character for odd indices and the other for even indices. Whenever you move along the string you can change the arrays accordingly and check whether it can be made unstable.
I was getting TLE on D. I only suspect string concatenation. But why could that give TLE. Isn't it O(1) in C++.
My submission: 118431680.
There's no way string concatenation can be O(1)
appending one character at end of string is O(1) in C++.
And that only if we use
str+="ch",str=str+"ch"is still O(n).or we can use
push_back()method for O(1) too.Damn bro, you are right only changing t=t+"0" to t+="0" gave AC. 118441663
But can anyone tell why that happens? I used to think, both are just different ways of writing.
str = str+"ch"creates a copy ofstr, appends"ch"tostrand then assigns it back to thestraddress. Whilestr += "ch"directly places"ch"behind the address ofstr.Thanks
you stole my 1-gon.I was gonna write the same.
this is what cheems told me "This is pretty obvious. t+= s just appends the string s while t = t + s first creates a new string by concatenating t and s and then copies it into t once again. Hence the extra time."
For problem D:
It's a binary tree with values representing how many possible winners can be up to this node.
Root is last character of string s. If '?' is a leaf then its value is 2 If '?' isnt a leaf its value is sum of their children If '1' its value is value of right son or 1 if its a leaf If '0' its value is value of left son or 1 if its a leaf
Can someone told me if that's true? I came up with that idea but couldnt implement it efficiently.
That is correct. I passed with this approach.
I got wa on tc 12 with same idea :(
Yes, and for update just go traversing through all its parents that will be O(k).
Yes, the complexity of each update would always be O(k) since the depth of the tree is k.
Yeah bro. At first time i was also confused of how to implement it but then i realized: you should try Segment Tree. Hihi nice problem =)
How to solve in F when length of all strings < $$$sqrt(N)$$$?
Hint: you should bruteforce substring which you want to sort
Yes, I tried this during whole contest, but could not come up with a solution. If I bruteforce such substrings won't it be $$$O({len}^3)$$$? because every time I need to check if its sorted as well as both its endpoints are breaking the sorting order.
Let me explain in more detail.
We want to count the number of pairs of strings that one can be obtained from the other by sorting a fixed substring.
All strings will be divided into groups by prefix and suffix, so that the parts not affected by sorting are equal.
For each group, we will count separately.
Now you need to count the number of pairs of strings that their first and last letters are different, and at least one of them is sorted.
Let's imagine we can count the number of pairs of strings such that the first and last letters are different (we forgot about sorting condition).
Then it is enough to calculate this amount for all strings and subtract this amount from it for all unsorted strings. It will be just right this number if one of them sorted.
So if $$$m$$$ is len of string it will works in $$$O(m^2*n)$$$
Sorry for english :(
Ohh! Thanks a lot for sharing the approach.
You can also look at code, but it is not understandable probably 118437013
can anyone pls tell what is wrong in my solution for problem C:
Try this case:-
0??0
Can someone explain why the first one got TLE and the second one got accepted? 118405641 118410983. It seems to me that both have the same complexity and even if they don't, n all over test cases was <=2.000 so n^2 was 4.000.000 and the time was 2 sec.
In
48thline, you usei < imp.size() - 1. Here,size()returnsunsigned int. If imp.size() == 0, then0 - 1 = 4294967295(unsigned int). That's why you got TLE.Addition: In C++17(64 bits), size() returns signed int.
I want to say a few words about problem C, for which we got an insane amount of questions. There were two main points which participants considered to be ambiguous:
1) "Let's call a string beautiful if it consists of the characters 0, 1, and ?" could mean that the string has to contain all of these characters at least once. I admit that it can be ambiguous. I got used to writing the sentences like this one in input format, for example, where it didn't cause any ambiguity in previous rounds. I'll try to avoid using it in the main statement, since it could have several different interpretations.
2) "Any two adjacent characters are different" — does "any" mean "every" or "some"? Both options are possible in common English, so the statement would be ambiguous if it was ended with this phrase. But the next part of the same sentence allows anyone who doesn't skip that part to understand which meaning the word "any" has. If "any" is "some", then the constraint on the string having format "01010..." or "10101..." has no sense at all! But if "any" is "every", it makes total sense. Why did most participants completely ignore that part?
because it is not englishforces, it's codeforces.....
Is the fact that "any" is often used as "every" some advanced English? I believe it is commonly used, for example, in mathematical theorems/statements of math problems (even school ones).
In my personal opinion,for the first point,'A consists of B' means all elements of A is in B,meanwhile,'A contains B' means all elements of B is in A.Like [1,2,3,4,5] consists of natural numbers and it contains [2,3,5].
For the second point,'any' means 'some' only in questions,like 'Are there any rivers on the Earth?',whilst in other sentences it means 'every'(like 'The Nile is longer than any other rivers.')
Although point 2 didn't affect most people with experience, you also could have just written "every" instead of "some".
We didn't write "some" at all, that would make the statement contradictory to itself.
I understand what you wanted to say though, I agree that "every" would fit better than "any", but we didn't think about that during the preparation stage.
I'm getting confused from the statement again!
Plus, if you just google "any", your first synonym is literally "some".
This is the first link I get by googling "any definition", and it says the synonyms are "each" and "every".
When I read this "Let's call a string beautiful if it consists of the characters 0, 1, and ?" and you can replace the characters ? to 0 or 1 so that the string becomes unstable. This forces me to assume that char '?' is the must and we have to replace it to make it unstable
I bombarded 2 clarifications after first announcement.
So here is what happened with me -
I understood that "any" means "every" here. I wrote a correct soln. Passed sample. Just before I was going to press that damm submit button first announcement came.
In the chaos, I completely forgot that I was supposed to count unstable string only. For 2 mins I was like this problem asks to count stable string. I was like this announcement explicitly say "0" or "1" shouldn't be counted as valid answers contrary to what Vacuous truth.
I spend the next few minutes refreshing the problem statement in the hope of change in the sample output. Later ended up sending the first clarification because if I don't 1 length strings there is no way I can produce the expected sample output for a given sample.
It took me some time to realise that the initial version I assumed was correct and I should just press that submit button.
Feedback / How the statement would have been better -
Unstable string definition could have been avoided. You could have just said that a string is beautiful if it consists of alternative '0' and '1' characters. Some examples of beautiful strings are ......
Now we have a string s which consists of '0', '1' and '?'. Count the number of substrings that can be made beautiful by replacing '?' with '0' or '1'. <Insert something about you should independently replace '?' for each substring.>
explaining the sample test cases in bottom would have avoided lot of confusions.
!
12 hours hacking phase then 12 hours until system start testing :P so nearly 24 hours
ok thanks...i am new to competitive coding
Well the idea for D was simple but it took around 1 hour to implement it. It was very similar to segment tree but not exactly that! Can someone share his code who hase implemented it nicely?
here It was totally implementation based i agree. But Interesting for me because it was the first of its kind i ever tried
Here you go 118435824, I tried to implement it as nicely as I could but it may not be good enough as I have not been coding for sometime now.
118438203
(Submission : 118424181) I created a structure for the match. Then kept a 2d vector of matches, where I stored all
nphases of the tournament.the main problem i was having was was in update function, whether to update left child or right child. i used in time out time concept since the build function is basically a dfs. everything else was pretty much segment trees. but it took me 70 fucking minutes to come up with.
You can perform the updates bottom-up instead of top-down, then instead of "recursively update either the left or right child", the procedure is "recursively update the parent"
F. actually i was already thinking in segment trees so this didn't strike me. would have made things much simpler.
Can someone please explain why I got TLE on D? My approach was that for each change, we just have to update the value of the next round which will require K updates for 1 query.
My submission: https://codeforces.me/contest/1535/submission/118439047
Any help would be appreciated. Thanks a lot
Though I only solved 4 first problems but i think D is the best. It improved ST skill a lot. Thanks for a great contest <3
How to do F?
I only know a $$$O((\sum len)\sqrt{\sum len})$$$.
Try to solve the case when $$$n\leq 500$$$,and $$$len\leq 500$$$.
For Problem F first we observe:
if two strings are equal, this adds 0 to the sum
if two strings have equal prefix and suffix and the different part ist sorted in one of them, then it adds 1 to the sum
if they cannot be transformed into each other, because they have different amount of letters, then they add 1337 to the sum
else they add 2 to the sum, since we can just sort both of them
We seperate the strings into groups, corresponding to the amount of letters they have. All pairs between different groups add 1337 to the sum. So we only regard pairs in the same group. Now we distinguish two cases:
We have many short strings.
We have a few very long strings.
For case 2 we can simply check all strings pairwise, whether they are same or have the same prefix/suffix and the different part is sorted in one of them or not, to add either 0 or 1 or 2 corresponding to the observations. This is $$$O(n^2 \cdot len)$$$
For case 1 we do it the other way round. First we sort all strings, so we can binary search on them. Now we iterate all strings $$$O(n)$$$. We iterate over each subsegment of the string $$$O(len^2)$$$. We sort $$$O(len \cdot log(len))$$$ each subsegment and binary search whether the corresponding partly sorted string exists $$$O(log(n))$$$ in the group. If it doesn't exist, we add 2 to the sum. This additions need to be divided by 2 in the end, since we check each pair twice. We need to take care to not count one pair more than twice. e.g. look at
abcdefgandabedcfg. We could sort the second string from index 1 to index 7 and would obtain the first string. But we could also sort it from Index 2 to Index 6 and would also obtain the first string. To exclude this, we only count, if sorting[l,r]changes the letters at positionlandr. This will be $$$O(n \cdot log(n) \cdot len^3 \cdot log(len))$$$I did check
n<len^2to decide whether to take approach 1 or approach 2. It passed with 400ms for me. Edit: I changed it now to n<6800. Got hacked once and then I did a series of checks to find the ideal cutoff. It is 6800 for my algo.Also note: all strings are pairwise different. The Problem doesn't mention this directly, it is only mentioned in "Input". That took me writing some ugly code and more cases till I noticed that.
Does somebody have a more general solution, which doesn't need to distinguish between those two cases? I did try analyzing some dependencies between strings and maybe find regularities or trying to construct some sort of graph or dp over the string to count, but I didn't manage that.
Isn't that:You are given $$$n$$$ strings $$$s1,s2,…,sk$$$ having equal length.
Yes, they are all equal in length. Is there some place in my solution that assumes them different? Maybe my "different amount of letters" can be misunderstood. I meant
aabcandabcahave the same amounts of letters, butaabcandabbbdon't.Um_nik 's solution does not use any thing related to sqrt and is O(len log (len)), where len is total length of strings. Just watched his screencast, absolutely elegant solution.
1h59min: submit problem F.
2h: contest ends. and running on test 30 :)
2h01min : wa 59
after contest , change the hash parameter ,it passed ...
I missed AC on D by one line.
cout << cnt[6] << '\n';Anyways nice problem.
lol I missed E on Atcoder abc 198 because I misread the statement and had a 9 instead of a 10 for the max number of unique characters. Passed 2 minutes after contest ended but ¯\_(ツ)_/¯
How to get the correct index for D? I was trying to figure how but it's too complicated.
Same to me also
You can use a map to store the index corresponding to the game number while making the tree. This will help you with unnecessary mathematical relations.
Thanks, that's an easy way to implement.
I like problem D very much. while problems requiring segment tree is often asked in many contests, there are few questions that ask about the essential part of this. It is interesting to utilize knowledge of data structures in a way that doesn't just use them :)
I think D looks more like a binary heap (eg the one used for priority_queue) than a segment tree
I would really appreciate if somebody could give some test case where this C solution fails
https://codeforces.me/contest/1535/submission/118438062
I tried to run it on 10000 generated strings of length 2e5 and compare to other solutions, and my solution gave the same results as other working one :(
Overflow. I had the same problem, the answer to input with 20000 '?'s doesn't fit in an int
But i have #define int long long :d
for the case that u said, my program prints 20000100000 which seems fine
Even though it gets assigned to a long long, it's too late because the overflow happened already: (s.size() * (s.size() + 1)) / 2
Screencast with commentary, and it wasn't even livestream during the contest!
Hi 1000 cyans.
Hi 1 cyan.
This is regarding the bugaboo B. Can anyone tell why this solution gets accepted while this solution gets a TLE. The only difference is I am storing vector.size() in a variable and using it in the last for loop. I believe vector.size() has a O(1) complexity.
.size()for vector is O(1). Check complexity in cppreferenceChange
for(i=0;i<odd.size()-1;i++)tofor(i=0;i<odd.size();i++)and see magic..size()is unsigned 64 bit integer type. When its 0 subtracting-1for it makes it2^64-1.Just run
cout<<a.size()-1<<endl;on an empty vectoraonce.Thanks,
could you explain why x==4294967295 and y==-1
Got it, thanksHey can you tell me reason for this too - These are two submissions with same code just a single difference in compare function , can anybody tell me why one is giving TLE and other not ??
TLE — https://codeforces.me/contest/1535/submission/118378801
AC — https://codeforces.me/contest/1535/submission/118474020
In TLE, when the function is sorting and it compares two even numbers, you always return true based only on the first number. It is known that in the compare function you must return false when both elements are considered equal, but here you are returning true. I also had this problem when I didn't know that assumption and I wrote <= in a compare function instead of strict <, which is wrong with the same idea. You can check here for some insight
if
vector.size()>0then your both code will work fine.but ifvector.size()==0thenvector.size()-1will give an unexpected huge value,thats why your 2nd code gave TLE.It's not about time complexity :)it's not really unexpected:
vector::size()issize_t, ifv.size()is 0 thenv.size() - 1will be2^64 - 1, it kinda wraps around like thatsize()returns an unsigned integer, so if the size ofoddis 0, it becomes INT_MAX after subtracted by 1.In D, I had a recursive function that updated the value of the next round. Something like this:
The above was giving me TLE. I changed the recursion to an iterative loop in the following manner:
This solution passed. Could someone explain what might be the reason?
Please ignore this comment. I had made a slight mistake in the first solution.
finally a balanced contest after so long
Thanks for such interesting tasks!!!
My solution for D passed in C++, but timed-out in PyPy. Is there anything I'm doing that looks slower than it needs to be?
https://codeforces.me/contest/1535/submission/118421365 https://codeforces.me/contest/1535/submission/118429580
First to say is PyPy is not very good with strings (to say at least) it is meant for numbers. So your solution runs better in Python 3 — it will pass the 4th test. (PS. Or is it only marginally better and strings doesn't matter? Looks like this is the case.)
But since even your C++ solution needed almost a second — it is not enough to get all the test. One possible solution is to cut 2**(k+1) to only 2**k. This barely passes.
On python you have to use fastio — some things, that will allow you to read and write faster, than the basic functions. Otherwise, even if your programm has just 2*10^5 input()'s and print()'s, and nothing else more, you will get TLE =\
And one thing more, if you collect all output data and then print it as '\n'.join(data) you'll get sufficient speed bust.
Is it possible to pass E with O(Nq(N)) time?
Can anyone tell me what happens if we submit two AC solutions to a problem in EDU rounds? As it has not affected my rank in any way and moreover in rank list my first solution time is shown only.
I also have the same question. It supposed to add 10 min as a penalty for resubmission. But today it doesn't change the rank for my second submission.
I think penalty is for wrong submission. I dont think penalty but may be it should consider the time for latest AC submission as total time for that problem but that did not happen.
It cost me a lot of downvotes, but heres an answer to this question :)
https://codeforces.me/blog/entry/88924
tl;dr only last successful submission time counts, so re-submitting a successful submission will lose you points.
Educational rounds have ICPC rules, so they use the first successful attempt. Regular Codeforces rounds have special Codeforces rules and only accept the last successful attempt for system testing.
can anyone help me, i am getting memory limit exceeded in solution for problem D: https://codeforces.me/contest/1535/submission/118446055 I cant find the issue, i haven't declared any array more than limit i think.
invalid index access of the array but should have been a runtime error and not mle
Thanks for the help
I guess it's UB but MLE seems like a weird verdict anyways.
Is there any benefit of sorting the odd array in
problem B?Is there any benefit of sorting the odd array in
problem B?No
Did you get AC without sorting?
See this. 118449788
I Loved problem D, the first time I got a chance to use Segment tree in a CF contest. Thanks to the team behind the contest.
Подскажите, пожалуйста, как в таких случаях переворачивают деревья, то есть, изначально нам дано древо вида (задача D):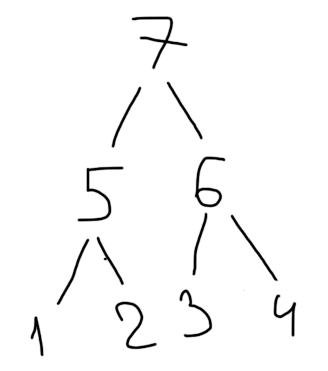 Как можно переназначить номера вершин, дабы у нас получилось дерево, по вершинам которого можно удобно передвигаться как
Как можно переназначить номера вершин, дабы у нас получилось дерево, по вершинам которого можно удобно передвигаться как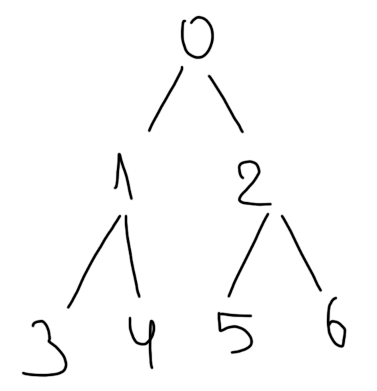 Заранее спасибо
Заранее спасибо
2 * i + 2, 2 * i + 1, то есть, такое:Ты можешь в качестве ноды использовать структуру, в которой будет ссылка на верхний и нижний уровни https://codeforces.me/contest/1535/submission/118441848 вот пример реализации
Я сделал проще — я сразу развернул исходную строку s. И потом когда приходили команды на изменение строки, я вычислял, какое значение нужно редактировать. Ну и конечно правило, что означает '0' и что означает '1' в строке пришлось инвертировать. https://codeforces.me/contest/1535/submission/118416230
Is it possible to solve C with Binary Search? If it is possible, then what would be the approach.
I solved C using binary search. For each index i, let's find how many good substrings starting with str[i]. To do so, we can binary search on the largest j such that all the ones in str[i..j] are in even positions and all zeros are in odd positions or vice versa. We can know how many ones/zeros are in even/odd positions using cumulative sums.
Why is this solution for problem B giving TLE?
check this comment
I solved Problem E in Java after the contest ended. Took me about 1 hour to implement a binary lifting solution, but 3 additional hours to find a way to read the input fast enough to avoid TLE on Test 2! I hate interactive problems...
Actually, given the effects of each query are completely deterministic, I don't see why the problem is interactive in the first place. Is it just to troll non-C++ programmers?
If it wasn't interactive you could do euler tour on final tree and answer queries top down after finding top nonempty node. I guess they didn't want to allow this solution
How much time it takes after hacking phase to provide new ratings?
generally in edu rounds and div-3 rounds, they do another system test. In all last educational rounds and div-3 rounds in which i had participated, another system test occurs after 12 hours of finishing of hacking phase. So ratings will change between 13:35 — 15:35 UTC (19:05 — 21:05 ITC)
Disclaimer: I am not a codeforces official and this is just expectation with reference to previous rounds
NOTE: if you are sure that your solutions pass system test, then you can see unofficial rating changes here(cf-predictor)
Does CHEATING occurs in every Codeforces rounds?... (T_T)
some of the participants tend to do so, preventing cheating completely is tough for codeforces. but its best to avoid doing it for your own good
Does the contest became unrated?
I think so.....
Yes, I don't know why I am still unrated. :cry
Is it usually just the contest phase or the hacking phase to that contributes to ratings?
Is there an advantage to using C++ in these contests? I personally am using Java, but would using C++ potentially remove some TLE errors?
It would not
Editorial please..
Why rating was not upgraded ye?__
To not keep you waiting, the ratings updated preliminarily. In a few hours/days, I will remove cheaters and update the ratings again!
GG to me for reaching Specialist..........
In problem E, it would've been interesting if the child node had less cost than the parent node.
In C, I tried to find the bad substrings and then delete them from the total number of substrings possible. But I failed miserably in implementing that. Can anyone code that for me? Also, I was trying to avoid double counts in my implementation, but I guess I failed at it. So, at least tell me how to avoid double count in its implementation.
Hi, Regarding problem D , I wrote a recursive implementation of a segment tree , But my submission is giving me a TLE . Is it mandatory that we write a iterative implementation of a segment tree ?
If not so , Can someone help me speed up my implementation by pointing out the changes that I need to make. Here's the link for my submission . Thanks in advance .
Dear MikeMirzayanov, awoo my codes were copied and it was my mistake :(
I wanted to have an archive of my CP codes in a GitHub repo . But I found manually committing in the repo, time consuming. So I wrote a cron-job for it.
But my mistake was that I forgot to make the repo private and cron-job was for every 30 mins.
Thus, my codes got auto-uploaded to GitHub during the contest and was available to the public.
I know the mistake was from my end, and I will make sure to not repeat it.
I received a message regarding matching of my code with someone else code. But I wrote it my own. I don't know how that happened but I will take care at my best that such a thing will not happen again. I honestly practice coding. Please consider my point. I have been writing such types of codes for my practice and in contests... And from next time onward I will try to take unique variables so that it does not match with anyone...maybe someone copied the structure of my previous code.
I wonder why people like you write when they have a perfect match of non-trivial code. Do you think we are idiots?
118418799 vs 118418799
MikeMirzayanov, I just got a message that my solution Kal-El/118413234 for 1535C coincides with low_profile/118412998,K0000/118413793, shakeitbaby/118414205, O_BhosDiwale_ChaCha/118414232, madarakaguya1234/118414304, XENOX_GRIX/118417732, codeforcesalt11/118418351, yash_agarl_/118423400
I think this is either coincidence(I used a simple 2 pointer approach for it) or the people mentioned above are indulging in cheating. I have never indulged in leaking my solution or copying someone else code (you can have a look at my profile to confirm it), and looking at the timestamps it is clear that I did not copy paste someone else code.
If u look at template of my other submissions on Codeforces it is similar to my submission for 1535C but for the people mentioned above their code style is not same as their submission for 1535C. I do not know how they got access to my code or was it just a mere coincidence.
I sincerely participated in the contest and it is a humble request to you to not skip my submissions for the contest.
Don't waste my time: 118413234, 118412998
MikeMirzayanov, I got this message, "Attention! Your solution 118427098 for the problem 1535D significantly coincides with solutions XDEv11/118427098, H0WL1NG/118439140. Such a coincidence is a clear rules violation.".
I solved all the problems myself and did not leak any source code. However, I have looked at that submission and some parts seems actually the same as mine. I don't know what happened. Maybe it's just a coincidence. Hope it can be found out. Thank you!
Oops: 118439140, 118427098.
Ya, I know. I thought one possible reason just now. In the last few minutes, I decided not to continued solving problems. And as usual, I saved the archive with git. But, this time, I pushed it to GitHub too early.
This is my fault. Sorry for wasting your time. I'll make sure this won't happen in the future.