


Всем привет.
31 марта в стенах Самарского государственного аэрокосмического университета прошла VI Межвузовская олимпиада по программированию. Мы приглашаем вас принять участие в тренировке по задачам этой олимпиады.
Авторы задач — команда Samara SAU Teddy Bears. Тестировал комплект ashmelev, за что ему еще раз спасибо.
Сложность такая же, как в предыдущих наших контестах — три звезды. Продолжительность — 5 часов.
Начало — в эту субботу (27 апреля) в 14:00 (MSK).
UPD. Видеоразбор.







Will the problem description be in English or Russian?
Both.
Does the contest effect rating?
No.
where is the link for the contest?
Codeforces Gyms
Find our contest (it's on the top now), register and solve the problems.
it's russian thread)
http://codeforces.me/gymRegistration/100187
http://codeforces.me/gym/100187
What is the link for the contest?
Codeforces Gyms
Find our contest (it's on the top now), register and solve the problems.
Remember that it's already running and you will have less time. After finish you can participate in virtual mode.
Thanks for the nice problems, it's the first time ever I can solve more than 5 problems in one contest, it's 8!!!!!!!!!!!
How to solve B, G, K?
For B: calculated number of occurrences n_i of each character, probability to pick each letter is n_i/n, where n is total length of the string, and we'll see it n_i times. Expected value is sum of such probabilities.
B — ans = sum(count(c) * count(c)) / |s|, where count(c) means each char, how many times it appears in s. K — you are going to construct an array which has the inversion number equals to k, you can do it greedily.
For K, I start with the decreasing order which has the inversion equal to n * (n-1) / 2, and try to reduce it to k. For example, if the order is 5, 4, 3, 2, 1. We can reduce it by 4 by moving 5 to the end (4, 3, 2, 1, 5), then reduce it by 3 by moving 4 to the position next to 1 (3, 2, 1, 4, 5). The total number of inversion we can reduce is (n-1) + (n-2) + ... (n-m) where m is the number of time we reduce. We try to keep this sum greater than (n * (n-1) / 2)-k. Thus, for the last round of reducing, we will know the position that we need to move the number in the front to.
Here is my code 3643676
will there be solutions or put those problems on problem set?
You can solve these problems in practice mode. Enter the gym (link) and enjoy.
If you're stuck on some problems, ask here, someone will help you for sure.
Why the test cases in the practice mode , aren't shown?( like other contests ) It helps to find what's wrong with our code...
In Codeforces Gyms, the tests aren't shown in practice mode.
Address this question to MikeMirzayanov)
for problem C,we tried a greedy alog,but wa on test 8,,,anyone knows how to solve it ?
First of all, if you have WA 8, make sure that you don't output inversed permutation.
My solution:
We can easily check if the answer exists, using sweep line approach: make events "beginning of the segment", "point" and "end of the segment" and sort them. If we process the beginning of the segment, add pair (its end, its index) to the set. If we process point, take the minimal pair from the set (it's obvious that better to match point with the earliest closing segment). If the set is empty at this moment, matching does not exist.
Now check if the answer is not unique. Answer is not unique if for some points p1, p2 (p1.x <= p2.x) exist two segments s1, s2 such that max(s1.beginX, s2.beginX) <= p1.x, p2.x <= min(s1.endX, s2.endX), and they match each other in some full matching.
Consider that we are processing point p2 and it matches with segment s2. When the situation above can take place? There should exist some point p1 (p1 is earlier in the sorted array) such that s2.beginX <= p1.x. Also the end of the segment s1, which matches with point p1 (p1 was already processed since it is earlier in the points array) should be greater or equal than coordinate of point p2: p2.x <= s1.endX. How to check it? Let's create a segment tree which can do operations getMax(L,R) and set(index,value).
How does this segment tree work? For every point we will store the end of the segment which matches with this point. Ok, our sweep line is now processing point p2 and it matches with segment s2. What can point p1 be? Its coordinate should be greater or equal than s2.beginX — find the index of such point with binary search (let it be leftIndex). Then consider all points in the subarray [leftIndex, i-1] (where i is the index of the point p2, after all points are sorted). Make query on this segment and we will find the rightest end of the segment s1 which matches with such point p1 that can be also matched with segment s2. Now, if p2.x <= s1.endX, the answer is multiple. And update the segment tree using set(i, s2.endX).
In fact, we copypasted this problem from Timus. But our problem has much higher contraints :)
I've found very elegant
O(N)DP for checking uniqueness of the answer after some simpleO(N * log N)preprocessing.At first I sort segments by their right ends and maintain points in the set. For
i-th segment I choose the least available point on it and delete it from the set (if it exists). Denote it asbest[i]. Then for future needs I also save the next least available point tonext[i](if it exists).The matching exists if and only if
best[i]exists for eachiand we can find the answer easily by arraybest[].Denote as
segm[i]the segment that matches withi-th point. Sosegm[best[i]] = i.Now how we can check uniqueness. The found matching is lexicographically smallest in some sense. Let's seek for the lexicographically next matching. For this we should try to replace
best[i]bynext[i]for each segmentiin orderN, ...,1, sincenext[i]is the next best choice for thei-th segment. When we do such a replacement, the segmentj = segm[next[i]]looses his point and we should either replace it bybest[i]if possible, or otherwise takenext[j]. In the latter case we should proceed tosegm[next[j]]and so on. The replacement is possible once at some step we reach the segment that contains pointbest[i]and in this case we perform some cyclic shift of the subsequence of our matching.But we don't need to do this walk each time. Instead we can check each segment by clever DP in
O(1)time. Namely, letdp[i]be the smallest left end of the segments in the walki, f(i), f(f(i)), ..., wheref(i) = segm[next[i]]. Then second matching viai-th segment is possible if and only ifdp[f(i)] <= leftEnd[i]dp[f(i)] <= x[best[[i]]. Calculating ofdp[i]is simple: ifnext[i]does not exist thandp[i] = leftEnd[i], otherwisedp[i] = min(leftEnd[i], dp[j]), wherej = segm[next[i]].dp[f(i)] <= lefEnd[i]you probably meandp[i] <= x[best[i]]wherex[best[i]]is a coord of our point?Люди сдавшие Ешку после WA 34, можете подсказать как вы обошли этот тест?
У меня был WA 34 я почему-то думал, что в лабиринте можно ходить только вниз и направо. Потом понял ошибку и использовал три обхода в ширину.
Мы были удивлены, увидев, как много наших тестов проходят подобные решения)
Как кстати решается задача I?
craus вам расскажет)
https://www.youtube.com/watch?feature=player_detailpage&v=vY0qn7DUyHg#t=1202s
Там правда довольно длинно. В двух словах. Строим все производные начиная с конца (с производных старших порядков). При построении текущей производной нужно учитывать ограничение на нее, и ограничение на производную предыдущего порядка. На каждом шаге нужно стремиться сохранять все значения производных как можно меньшими по модулю, чтобы в итоге удовлетворить ограничениям на значения элементов самого массива.
Don't forget that tomorrow there will be another gym contest: http://codeforces.me/blog/entry/7493
will a contest with four stars be as hard as CF div1 ?
Расскажите, пожалуйста, как решается B. Интуитивно сдал вот это:
Но доказать не смог( А еще как решать F?
В очень и очень многих задачах на поиск матожидания нужно вспомнить и применить магическое свойство линейности матожидания. Оно гласит, что матожидание суммы случайных величин равно сумме их матожиданий. При этом неважно, зависимы ли эти случайные величины.
Как оно поможет нам в этой задаче?
Нужно найти матожидание количества совпадений символов. Можно представить это как матожидание суммы количеств совпадений для всех символов одной из строк по отдельности. По свойству линейности матожидания получаем, что эта величина равна сумме матожиданий числа совпадений для каждого символа по отдельности.
Матожидание числа совпадений для одного символа равно просто вероятности совпадения. Таким образом, нужно найти сумму вероятностей совпадения для всех символов. Для одного символа она равна отношению числа таких символов в строке к длине строки.
Если расписать это, получится именно то, что есть в вашем коде. (У вас, кстати, можно сократить умножение и деление на s.length())
Другой пример на применение этого свойства. Мне он просто очень нравится.
Пусть имеется турнир по некой игре, в результате которого каждый участник займет определенное место в итоговой таблице результатов. Допустим известны правлиа игры и турнира, позволяющие нам для любых двух игроков вычислять вероятность того, что первый выступит лучше и займет место выше второго. Требуется для каждого игрока посчитать матожидание его места в итоговой таблице.
Пусть индексация будет с нуля. Тогда место, занятое игроком — это число игроков, которые выступили лучше его. Значит нужно найти матожидание количества игроков, выступивших лучше чем он. По правилу линейности оно равно сумме по всем остальным игрокам вероятностей выступить лучше чем этот. А их мы считать умеем.
Опять же, при этом неважно, насколько сложны правила, насколько результаты для различных игроков зависят друг от друга. Главное, что мы знаем вероятности интересующих событий по-отдельности.
F — обычная жадность двумя указателями. Меня удивляет, что ее так мало народу решает.
How to solve the problem I?I don't have the idea after thinking a lot? Can someone give me some idea about problem I?
Build all derivatives starting from derivatives of higher orders.
Example.
Let b = [1,0,0,1,1]
4-th derivative has length 1. Any array of length 1 is both increasing and decreasing. But we have restriction for 3-rd derivative: it should be increasing also. This means elements of 4-th derivative should be positive.
a[4] = [1]
3-rd derivative has length 2. We already have built 4-th derivative, so we know that a[3][1]-a[3][0] = 1. 2-nd derivative should be decreasing => elements of 3-rd derivative should be negative.
a[3] = [-2,-1]
With similar reasoning we get:
a[2] = [-1,-3,-4]
a[1] = [9,8,5,1]
a[0] = [1,10,18,23,24]
At every step we should keep absolute values of derivatives minimal possible to satisfy restrictions on elements of resulting array — they must be in range [-10^9..10^9].
Thanks a lot!
Как доказать в А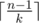 ?
?
Извиняюсь, если это есть в видеоразборе, нормального интернета нет.
Оптимальная стратегия такова:
Сначала последовательно берем наборы из k зелий. При этом в худшем случае каждый раз будет не везти, и кролик будет умирать. Делаем это, пока не останется один набор размера m, m <= k.
Если m = 1, это и есть искомое зелье, кролика тратить не нужно.
Иначе действуем так: поочередно исключаем из набора оставшихся одно зелье, и дополняем набор до размера k любыми другими зельями. Если в результате кролик умер, значит исключенное зелье было зельем бессмертия. Если не умер, продолжаем эту процедуру. Понятно, что в худшем случае на этом этапе понадобится пожертвовать одним кроликом.
Получается, что на первом этапе мы потратим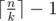 кроликов, а на втором ноль, если n%k == 1, и одного иначе. Можно этот случай проверить ифом, а можно, как у вас, записать итоговый ответ формулой
кроликов, а на втором ноль, если n%k == 1, и одного иначе. Можно этот случай проверить ифом, а можно, как у вас, записать итоговый ответ формулой 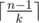 .
.
Весь контест тупили с условием и решали не ту задачу. Больше спасибо, теперь дошло.
Finally ACed probelm C and problem I , really nice problems!!!!!!
Где можно найти тесты к задаче Е?
Твое решение валится на таком тесте (см. в предыдущей правке)
any hints on problem G? I have tried a greedy constructive approach, like sort the k string (i see each block as a string) first and check if it is impossible to have an answer (ie: s[i][k] > s[i+1][k] where s[i] is the i-th string in the sorted array), then try to fill each '1' which is not yet filled before.
I have also tried those case with duplicate blocks given, etc.
Still I keep getting WA in case 3, 5, 12. :(
Your checking of the existence of the answer is correct. I think you have a bug in the next part of the solution.
A hint for the second part: you can set the monochrome for each image immediately after the sorting.